“10 minutes to pandas” 문서를 따라해보며 작성했습니다.
https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html
2022. 1. 30 최초작성
2022. 3. 19
head에 지정한 개수만큼 DataFrame 상단의 행을 볼 수 있습니다. 디폴트 값은 5입니다. 여기에선 3으로 지정하고 있습니다.
| import numpy as np import pandas as pd df = pd.DataFrame(np.random.randn(20, 2), columns=list("AB")) print(df.head(3)) |

tail에 지정한 개수만큼 DataFrame 하단의 행을 볼 수 있습니다. 디폴트 값은 5입니다. 여기에선 3으로 지정했습니다.
| import numpy as np import pandas as pd df = pd.DataFrame(np.random.randn(20, 2), columns=list("AB")) print(df.tail(3)) |

인덱스와 열 이름을 각각 출력합니다. 이때 데이터프레임의 values 속성을 사용하여 Numpy 배열로 변환했습니다.
| import numpy as np import pandas as pd df = pd.DataFrame(np.random.randn(3, 3), columns=list("ABC")) print(df) print(df.index.values) print(df.columns.values) |

to_numpy() 메소드 또는 values 속성을 사용하여 DataFrame을 넘파이 배열로 변환합니다.
데이터프레임에 속한 데이터의 타입이 모두 같지 않으면 넘파이 배열로 변환시 타입이 모두 같을 때에 비해 시간이 더 걸립니다.
왜냐하면 넘파이 배열은 모두 같은 타입을 가지기 때문에 데이터 프레임의 데이터 타입이 컬럼별로 다른 경우 모든 타입을 하나의 데이터 타입으로 변환해야 하기 때문입니다.
데이터프레임 df의 경우 모든 컬럼이 같은 타입이고 데이터프레임 df2는 컬럼별로 다른 타입으로 구성되어 있습니다.
df(0.0초)보다 df2(2.7초)가 넘파이 배열로 변환하는데 걸린 시간이 더 오래 걸린 것을 볼 수 있습니다.
| import numpy as np import pandas as pd import time df = pd.DataFrame(np.random.randn(1000000, 2), columns=list("AB")) start = time.time() n1 = df.to_numpy() print("time1 :", time.time() - start) # time1 : 0.0 print(n1.dtype) # float64 df2 = pd.DataFrame( { "A": np.random.randn(1000000), "B": pd.Timestamp("20211211") } ) start = time.time() n2 = df2.to_numpy() print("time2 :", time.time() - start) # time2 : 2.714345932006836 print(n2.dtype) # object |
to_numpy()를 사용하여 데이터프레임을 NumPy 배열로 변환한 경우 인덱스와 컬럼 라벨은 포함되지 않습니다.
| import numpy as np import pandas as pd df = pd.DataFrame(np.random.randn(4, 2), columns=list("AB")) print(df) print() n1 = df.to_numpy() print(n1) |

describe()를 사용하면 데이터프레임에 저장된 데이터의 통계를 보여줍니다.
| import numpy as np import pandas as pd df = pd.DataFrame(np.arange(100)) print(df.describe()) |

데이터프레임을 전치(Transpose)합니다.
| import numpy as np import pandas as pd df = pd.DataFrame([[1, 2], [3, 4]], columns=list("AB")) print(df) print() print(df.T) |

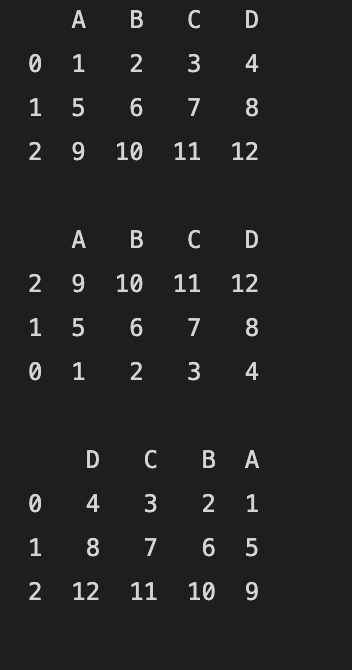
축(axis)을 기준으로 정렬합니다.
첫번째 축을(axis=0) 따라 정렬하면 행을 기준으로 하며 ascending를 False로 했기 때문에 내림차순으로 정렬됩니다.
두번째 축을(axis=1) 따라 정렬하면 열을 기준으로 하며 ascending를 False로 했기 때문에 내림차순으로 정렬됩니다.
| import numpy as np import pandas as pd df = pd.DataFrame([[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12]], columns=list("ABCD")) print(df) print() print(df.sort_index(axis=0, ascending=False)) print() print(df.sort_index(axis=1, ascending=False)) |
특정 컬럼의 값을 기준으로 정렬합니다.
아래 예제에서는 B 컬럼의 값이 뒤섞여 있는 상태인데 B 컬럼의 값이 내림차순으로 정렬되도록 하여 나머지 컬럼도 정렬되었습니다.
| import numpy as np import pandas as pd df = pd.DataFrame([[1, 3, 3, 4],[5, 0, 7, 8],[9, 2, 11, 12]], columns=list("ABCD")) print(df) print() print(df.sort_values(by="B")) |

Pandas 강좌 1 - Pandas 객체 생성
https://webnautes.tistory.com/1957
Pandas 강좌 2 - 데이터 보는 방법
https://webnautes.tistory.com/1958
Pandas 강좌 3 - 데이터 선택하는 방법
https://webnautes.tistory.com/1959
Pandas 강좌 4 - 연산(Operations)
https://webnautes.tistory.com/1960
Pandas 강좌 5 - 연결 및 그룹핑
https://webnautes.tistory.com/1961
Pandas 강좌 6 - 시계열(Time series)
https://webnautes.tistory.com/1962
Pandas 강좌 7 - 그래프 그리기(Plotting)
https://webnautes.tistory.com/1963
Pandas 강좌 8 - Pandas에서 CSV, HDF5, Excel로 저장 및 읽기
https://webnautes.tistory.com/1964
Pandas 강좌 9 - 결측치(Missing data)
https://webnautes.tistory.com/1965
'Python > Pandas' 카테고리의 다른 글
| Pandas 강좌 5 - 연결 및 그룹핑 (0) | 2023.10.12 |
|---|---|
| Pandas 강좌 4 - 연산(Operations) (0) | 2023.10.12 |
| Pandas 강좌 1 - Pandas 객체 생성 (0) | 2023.10.12 |
| pandas의 read_csv 함수에 사용되는 경로 문자열 앞에 r을 붙이는 이유 (0) | 2023.10.09 |
| Pandas DataFrame 숫자 아닌 값을 0으로 처리하기 (0) | 2023.10.09 |
시간날때마다 틈틈이 이것저것 해보며 블로그에 글을 남깁니다.
블로그의 문서는 종종 최신 버전으로 업데이트됩니다.
여유 시간이 날때 진행하는 거라 언제 진행될지는 알 수 없습니다.
영화,책, 생각등을 올리는 블로그도 운영하고 있습니다.
https://freewriting2024.tistory.com
제가 쓴 책도 한번 검토해보세요 ^^