
“10 minutes to pandas” 문서를 따라해보며 작성했습니다.
https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html
2022. 02. 02 최초작성
2022. 03. 19
2022. 08. 20
2023. 6. 17
열 이름과 행 인덱스로 선택하기
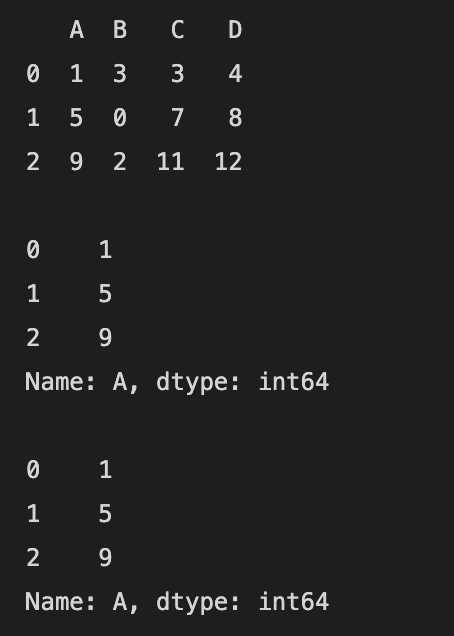
df["A"] 또는 df.A 처럼 열의 이름을 지정하여 해당 열을 선택할 수 있습니다.
| import numpy as np import pandas as pd df = pd.DataFrame([[1, 3, 3, 4],[5, 0, 7, 8],[9, 2, 11, 12]], columns=list("ABCD")) print(df) print() # 열 이름이 A인 열을 선택합니다. print(df["A"]) print() print(df.A) print() |

행을 슬라이싱하여 선택할 수 있습니다. 시작행 인덱스와 끝행 인덱스+1로 범위를 지정해줘야 합니다. 하나의 행 인덱스만 적으면 에러가 납니다.
| import numpy as np import pandas as pd df = pd.DataFrame([[1, 3, 3, 4],[5, 0, 7, 8],[9, 2, 11, 12]], columns=list("ABCD")) print(df) print() # 첫행만 출력합니다. print(df[0:1]) print() # 첫행과 두번째 행만 출력합니다. print(df[0:2]) |

행의 인덱스로 날짜 범위 지정도 가능합니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() # 인덱스가 2022-01-04부터 2022-01-05까지 해당되는 행을 출력합니다. print(df["2022-01-04":"2022-01-05"]) |

라벨로 선택하기
지정한 행을 열 형태로 가져옵니다.
행의 인덱스를 적어서 df['2022-01-01']처럼은 안됩니다. Pandas가 열을 기준으로 하기 때문입니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() # 인덱스가 2022-01-01인 행을 열 형태로 가져옵니다. print(df.loc['2022-01-01']) # 또는 print(df.loc[dates[0]]) |

행을 지정하기 위해 인덱스를 사용하고 열을 지정하기 위해 열 이름을 사용하는 예제입니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() # 날짜 범위로 행을 지정하고(이때 지정한 날짜도 포함됩니다) 열 이름으로 가져올 열을 지정합니다. print(df.loc['2022-01-01':'2022-01-04', ['A','C']]) print() # 행 전체를 지정하고 열 이름으로 가져올 열을 지정합니다. print(df.loc[:, ['A','C']]) |

하나의 행만 지정한 경우 1 차원 배열로 바꾸어서 가져옵니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() # 하나의 행만 지정하고 두개의 열을 지정하고 있습니다. # 가져온 결과는 1차원 배열이 됩니다. print(df.loc['2022-01-01', ['A','B']]) print() print(df.loc['2022-01-01', ['A','B']].shape) # 1차원 배열의 shape인 (2,)가 출력됩니다. |

열 하나, 행 하나를 지정하여 스칼라 값 하나만 선택합니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() print(df.loc['2022-01-01', "A"]) # 또는 print(df.loc[dates[0], "A"]) |

loc보다 좀 더 빠르게 스칼라값을 가져오는 방법입니다.
행을 지정할때 loc와 다르므로 주의해야 합니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() print(df.at[dates[0], "A"]) print() print(df.at['2022-01-01', "A"]) |

Position으로 선택하기
정수로 지정한 Position으로 열과 행을 가져올 수 있습니다.
Positon이 0부터 시작함에 유의해야합니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() print(df.iloc[3]) # 하나의 행(2022-01-04)을 가져옵니다. 1차원 배열입니다. print() print(df.iloc[:, 1]) # 하나의 열(B)을 가져옵니다. |

슬라이싱으로 열과 행의 범위를 지정하여 가져올 수도 있습니다.
주의할점은 슬라이싱 지정시 끝 인덱스는 가져오는 범위에 포함안됩니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() # 첫행,두번째 행의 데이터 중 첫번째 열 ~ 세번째 열을 가져옵니다. print(df.iloc[0:2, 0:3]) |

iloc를 사용하여 열과 행의 범위를 각각 지정하여 가져올 수도 있습니다.
슬라이싱 지정시 끝 인덱스는 가져오는 범위에 포함안됩니다.
| import numpy as np import pandas as pd df = pd.DataFrame([[1, 3, 3, 4],[5, 0, 7, 8],[9, 2, 11, 12]], columns=list("ABCD")) print('원본 데이터') print(df) print() print('1,2행 출력') print(df[0:2]) # print(df[:2]) print() print('2행 3열의 값 출력') print(df.iloc[1,2]) print() print('2,3행 중애 2, 4열만 출력') print(df.iloc[[1,2],[1,3]]) print() print('1,2행 중에 3,4열만 출력') print(df.iloc[:2,2:]) print() print('1,2행 출력') print(df.iloc[0:2]) print() print('전체 행중에 1,2열만 출력') print(df.iloc[:, 0:2]) |

리스트로 지정한 행, 열을 가져올 수 있습니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() # 첫번째 행, 세번째 행, 다섯번째 행 중에서 두번째 열과 네번째 열에 해당되는 데이터를 가져옵니다. print(df.iloc[[0, 2, 4], [1, 3]]) |

지정된 값 하나를 가져옵니다.
| import numpy as np import pandas as pd df = pd.DataFrame([[1, 2], [3, 4], [5, 6]], columns=list("AB")) print(df) print() # 세번째 행, 두번째 열에 해당되는 값을 가져옵니다. print(df.iloc[2, 1]) print(df.iloc[2][1]) # 인덱스를 괄호로 분리하여 적을 수도 있습니다. |

iloc보다 빠르게 지정된 값을 하나 가져오는 방법입니다.
| import numpy as np import pandas as pd df = pd.DataFrame([[1, 2], [3, 4], [5, 6]], columns=list("AB")) print(df) print() print(df.iat[2, 1]) |

조건으로 선택하기(Boolean indexing)
하나의 컬럼 값을 기준으로 행을 선택합니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() # A 컬럼의 값이 0보다 큰 행만 출력합니다. print(df[df["A"] > 0]) |

DataFrame에서 주어진 조건에 맞는 값을 선택합니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() # 값이 0보다 큰 경우만 값을 출력하고 조건에 맞지 않는 값은 NaN으로 출력됩니다. print(df[df > 0]) |

isin() 메소드를 사용하여 필터링
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() # 원본 데이터그램을 복사합니다. df2 = df.copy() # E 컬럼을 추가합니다. df2["E"] = ["one", "one", "two", "three", "four", "three"] print(df2) print() # E열에 "tow", "four" 있는 행만 출력합니다. print(df2[df2["E"].isin(["two", "four"])]) |

값 대입하기
행 인덱스와 열 이름으로 특정 위치의 값을 변경합니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() # 행 인덱스와 열 이름으로 지정한 위치의 값이 0이 됩니다. df.at["2022-01-01", "A"] = 0 print(df) |

position으로 지정한 위치에 값을 입력합니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() # position으로 지정한 두번째 열, 첫번째 행의 셀만 값이 0이 됩니다. df.iat[0, 1] = 0 print(df) |

넘파이 배열을 사용하여 값을 대입합니다.
| import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() # 라벨 D인 열에 숫자 5를 대입합니다. # 대괄호 안에 5를 넣어야 5가 해당 열에 대입됩니다. df.loc[ : , "D"] = np.array([5] * len(df)) print(df) |

조건에 따라 값을 변경합니다.
import numpy as np
import pandas as pd
dates = pd.date_range("20220101", periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD"))
print(df)
print()
# 데이터그램에서 음수인 값을 0으로 변경합니다.
df[df < 0] = 0
print(df)

Pandas 강좌 1 - Pandas 객체 생성
https://webnautes.tistory.com/1957
Pandas 강좌 2 - 데이터 보는 방법
https://webnautes.tistory.com/1958
Pandas 강좌 3 - 데이터 선택하는 방법
https://webnautes.tistory.com/1959
Pandas 강좌 4 - 연산(Operations)
https://webnautes.tistory.com/1960
Pandas 강좌 5 - 연결 및 그룹핑
https://webnautes.tistory.com/1961
Pandas 강좌 6 - 시계열(Time series)
https://webnautes.tistory.com/1962
Pandas 강좌 7 - 그래프 그리기(Plotting)
https://webnautes.tistory.com/1963
Pandas 강좌 8 - Pandas에서 CSV, HDF5, Excel로 저장 및 읽기
https://webnautes.tistory.com/1964
Pandas 강좌 9 - 결측치(Missing data)
https://webnautes.tistory.com/1965
'Python > Pandas' 카테고리의 다른 글
| 컬럼에서 특정 값을 가진 행 삭제하는 Pandas 예제 (0) | 2024.03.22 |
|---|---|
| 값 범위에 따라 컬럼 값 변경하는 pandas 예제 (0) | 2024.03.21 |
| Pandas 강좌 9 - 결측치(Missing data) (0) | 2023.10.12 |
| Pandas 강좌 8 - Pandas에서 CSV, HDF5, Excel로 저장 및 읽기 (0) | 2023.10.12 |
| Pandas 강좌 7 - 그래프 그리기(Plotting) (0) | 2023.10.12 |
시간날때마다 틈틈이 이것저것 해보며 블로그에 글을 남깁니다.
블로그의 문서는 종종 최신 버전으로 업데이트됩니다.
여유 시간이 날때 진행하는 거라 언제 진행될지는 알 수 없습니다.
영화,책, 생각등을 올리는 블로그도 운영하고 있습니다.
https://freewriting2024.tistory.com
제가 쓴 책도 한번 검토해보세요 ^^