
“10 minutes to pandas” 문서를 따라해보며 작성했습니다.
https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html
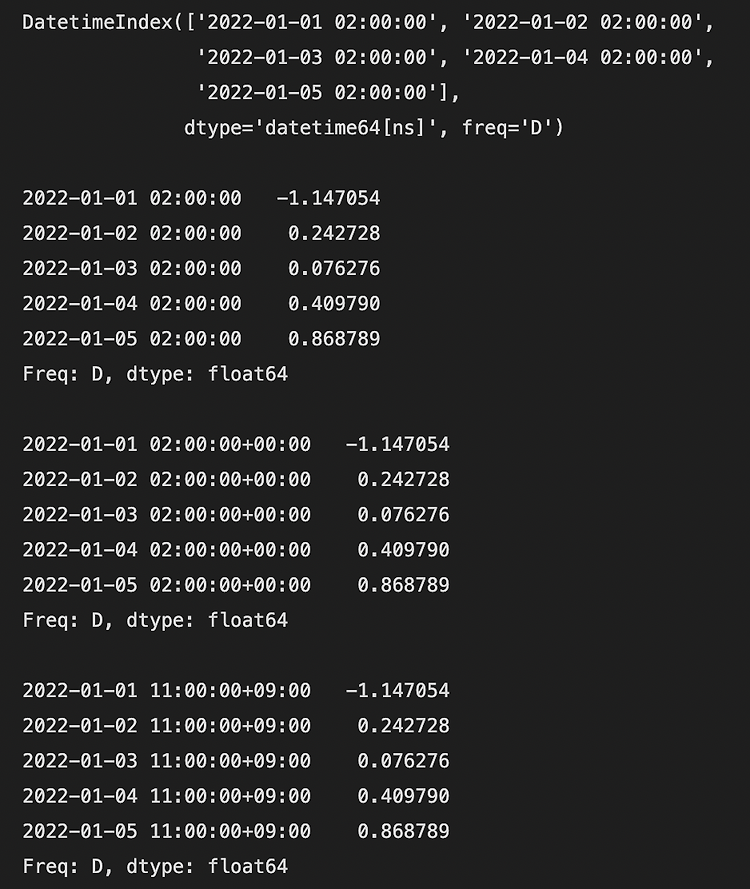
열 이름의 위치가 맞지 않으니 실행하여 결과에서 확인하세요.
2022. 02. 02 최초작성
CSV
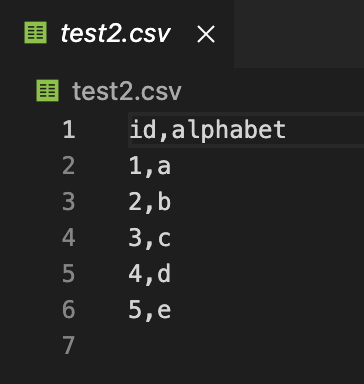
다음 내용으로 test.csv라는 파일을 작성합니다.
첫줄에 있는 컬럼 헤더에 공백이 없도록 주의하세요. Pandas에서 로드후 공백이 포함된 이름이 됩니다.
id,alphabet
1,a
2,b
3,c
4,d
5,e
다음 코드로 csv 파일 로드 및 저장을 테스트합니다.
| import numpy as np import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv("test.csv") print(df) # id alphabet # 0 1 a # 1 2 b # 2 3 c # 3 4 d # 4 5 e df.to_csv('test2.csv', index=None) |
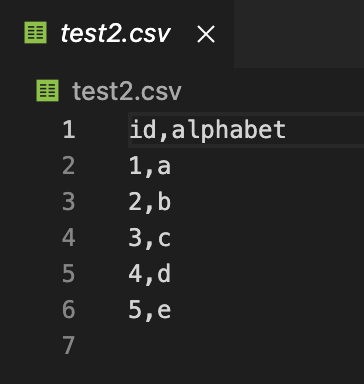
새로 생성된 test2.csv의 내용은 다음과 같습니다.
HDF5
Pandas에 저장된 데이터를 HDF5 포맷으로 저장했다가 로드해봅니다.
추가로 pytables 패키지 설치가 필요합니다.
| import numpy as np import pandas as pd import matplotlib.pyplot as plt # 2022년 1월 1일 0시 0분 0초부터 1초 간격으로 20개를 생성합니다. rng = pd.date_range("1/1/2022", periods=20, freq="S") print(rng) # DatetimeIndex(['2022-01-01 00:00:00', '2022-01-01 00:00:01', # '2022-01-01 00:00:02', '2022-01-01 00:00:03', # '2022-01-01 00:00:04', '2022-01-01 00:00:05', # '2022-01-01 00:00:06', '2022-01-01 00:00:07', # '2022-01-01 00:00:08', '2022-01-01 00:00:09', # '2022-01-01 00:00:10', '2022-01-01 00:00:11', # '2022-01-01 00:00:12', '2022-01-01 00:00:13', # '2022-01-01 00:00:14', '2022-01-01 00:00:15', # '2022-01-01 00:00:16', '2022-01-01 00:00:17', # '2022-01-01 00:00:18', '2022-01-01 00:00:19'], # dtype='datetime64[ns]', freq='S') # 앞에서 생성한 시간정보를 인덱스로 하여 0 ~ 10 사이의 숫자를 20개 생성합니다. ts = pd.Series(np.random.randint(0, 10, len(rng)), index=rng) print(ts) # HDF5 포맷을 파일로 저장합니다. ts.to_hdf("foo.h5", "df") # 2022-01-01 00:00:00 2 # 2022-01-01 00:00:01 6 # 2022-01-01 00:00:02 4 # 2022-01-01 00:00:03 5 # 2022-01-01 00:00:04 5 # 2022-01-01 00:00:05 9 # 2022-01-01 00:00:06 4 # 2022-01-01 00:00:07 0 # 2022-01-01 00:00:08 1 # 2022-01-01 00:00:09 0 # 2022-01-01 00:00:10 5 # 2022-01-01 00:00:11 7 # 2022-01-01 00:00:12 1 # 2022-01-01 00:00:13 7 # 2022-01-01 00:00:14 5 # 2022-01-01 00:00:15 1 # 2022-01-01 00:00:16 1 # 2022-01-01 00:00:17 5 # 2022-01-01 00:00:18 5 # 2022-01-01 00:00:19 1 # Freq: S, dtype: int64 # HDF5 포맷의 파일을 로드합니다. print(pd.read_hdf("foo.h5", "df")) # 2022-01-01 00:00:00 2 # 2022-01-01 00:00:01 6 # 2022-01-01 00:00:02 4 # 2022-01-01 00:00:03 5 # 2022-01-01 00:00:04 5 # 2022-01-01 00:00:05 9 # 2022-01-01 00:00:06 4 # 2022-01-01 00:00:07 0 # 2022-01-01 00:00:08 1 # 2022-01-01 00:00:09 0 # 2022-01-01 00:00:10 5 # 2022-01-01 00:00:11 7 # 2022-01-01 00:00:12 1 # 2022-01-01 00:00:13 7 # 2022-01-01 00:00:14 5 # 2022-01-01 00:00:15 1 # 2022-01-01 00:00:16 1 # 2022-01-01 00:00:17 5 # 2022-01-01 00:00:18 5 # 2022-01-01 00:00:19 1 # Freq: S, dtype: int64 |
Excel
Pandas에 저장된 데이터를 MS Excel 파일로 저장했다가 로드해봅니다.
추가로 openpyxl 패키지 설치가 필요합니다.
| import numpy as np import pandas as pd import matplotlib.pyplot as plt # 2022년 1월 1일 0시 0분 0초부터 1초 간격으로 20개를 생성합니다. rng = pd.date_range("1/1/2022", periods=20, freq="S") print(rng) # DatetimeIndex(['2022-01-01 00:00:00', '2022-01-01 00:00:01', # '2022-01-01 00:00:02', '2022-01-01 00:00:03', # '2022-01-01 00:00:04', '2022-01-01 00:00:05', # '2022-01-01 00:00:06', '2022-01-01 00:00:07', # '2022-01-01 00:00:08', '2022-01-01 00:00:09', # '2022-01-01 00:00:10', '2022-01-01 00:00:11', # '2022-01-01 00:00:12', '2022-01-01 00:00:13', # '2022-01-01 00:00:14', '2022-01-01 00:00:15', # '2022-01-01 00:00:16', '2022-01-01 00:00:17', # '2022-01-01 00:00:18', '2022-01-01 00:00:19'], # dtype='datetime64[ns]', freq='S') # 앞에서 생성한 시간정보를 인덱스로 하여 0 ~ 10 사이의 숫자를 20개 생성합니다. ts = pd.Series(np.random.randint(0, 10, len(rng)), index=rng) print(ts) # Excel 파일로 저장합니다. ts.to_excel("foo.xlsx", sheet_name="Sheet1") # 2022-01-01 00:00:00 0 # 2022-01-01 00:00:01 8 # 2022-01-01 00:00:02 6 # 2022-01-01 00:00:03 2 # 2022-01-01 00:00:04 3 # 2022-01-01 00:00:05 7 # 2022-01-01 00:00:06 8 # 2022-01-01 00:00:07 1 # 2022-01-01 00:00:08 9 # 2022-01-01 00:00:09 2 # 2022-01-01 00:00:10 9 # 2022-01-01 00:00:11 8 # 2022-01-01 00:00:12 8 # 2022-01-01 00:00:13 8 # 2022-01-01 00:00:14 1 # 2022-01-01 00:00:15 3 # 2022-01-01 00:00:16 7 # 2022-01-01 00:00:17 0 # 2022-01-01 00:00:18 6 # 2022-01-01 00:00:19 6 # Freq: S, dtype: int64 # EXCEL 파일을 로드합니다. print(pd.read_excel("foo.xlsx", "Sheet1", index_col=None, na_values=["NA"])) # 0 2022-01-01 00:00:00 0 # 1 2022-01-01 00:00:01 8 # 2 2022-01-01 00:00:02 6 # 3 2022-01-01 00:00:03 2 # 4 2022-01-01 00:00:04 3 # 5 2022-01-01 00:00:05 7 # 6 2022-01-01 00:00:06 8 # 7 2022-01-01 00:00:07 1 # 8 2022-01-01 00:00:08 9 # 9 2022-01-01 00:00:09 2 # 10 2022-01-01 00:00:10 9 # 11 2022-01-01 00:00:11 8 # 12 2022-01-01 00:00:12 8 # 13 2022-01-01 00:00:13 8 # 14 2022-01-01 00:00:14 1 # 15 2022-01-01 00:00:15 3 # 16 2022-01-01 00:00:16 7 # 17 2022-01-01 00:00:17 0 # 18 2022-01-01 00:00:18 6 # 19 2022-01-01 00:00:19 6 |
Pandas 강좌 1 - Pandas 객체 생성
https://webnautes.tistory.com/1957
Pandas 강좌 2 - 데이터 보는 방법
https://webnautes.tistory.com/1958
Pandas 강좌 3 - 데이터 선택하는 방법
https://webnautes.tistory.com/1959
Pandas 강좌 4 - 연산(Operations)
https://webnautes.tistory.com/1960
Pandas 강좌 5 - 연결 및 그룹핑
https://webnautes.tistory.com/1961
Pandas 강좌 6 - 시계열(Time series)
https://webnautes.tistory.com/1962
Pandas 강좌 7 - 그래프 그리기(Plotting)
https://webnautes.tistory.com/1963
Pandas 강좌 8 - Pandas에서 CSV, HDF5, Excel로 저장 및 읽기
https://webnautes.tistory.com/1964
Pandas 강좌 9 - 결측치(Missing data)
https://webnautes.tistory.com/1965
'Python > Pandas' 카테고리의 다른 글
| 값 범위에 따라 컬럼 값 변경하는 pandas 예제 (0) | 2024.03.21 |
|---|---|
| Pandas 강좌 9 - 결측치(Missing data) (0) | 2023.10.12 |
| Pandas 강좌 7 - 그래프 그리기(Plotting) (0) | 2023.10.12 |
| Pandas 강좌 6 - 시계열(Time series) (0) | 2023.10.12 |
| Pandas 강좌 5 - 연결 및 그룹핑 (0) | 2023.10.12 |
시간날때마다 틈틈이 이것저것 해보며 블로그에 글을 남깁니다.
블로그의 문서는 종종 최신 버전으로 업데이트됩니다.
여유 시간이 날때 진행하는 거라 언제 진행될지는 알 수 없습니다.
영화,책, 생각등을 올리는 블로그도 운영하고 있습니다.
https://freewriting2024.tistory.com
제가 쓴 책도 한번 검토해보세요 ^^