
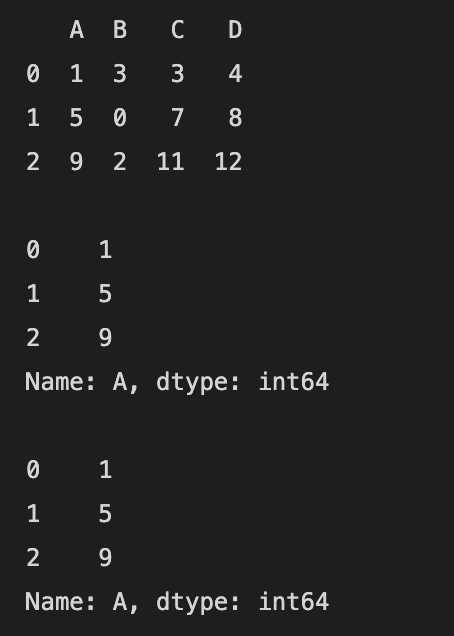
“10 minutes to pandas” 문서를 따라해보며 작성했습니다.https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html2022. 02. 02 최초작성2022. 03. 192022. 08. 202023. 6. 17열 이름과 행 인덱스로 선택하기 df["A"] 또는 df.A 처럼 열의 이름을 지정하여 해당 열을 선택할 수 있습니다. import numpy as npimport pandas as pddf = pd.DataFrame([[1, 3, 3, 4],[5, 0, 7, 8],[9, 2, 11, 12]], columns=list("ABCD"))print(df)print()# 열 이름이 A인 열을 선택합니다. print(df["A"])p..
컬럼에서 특정 값을 가진 행을 삭제하는 Pandas 예제입니다. 2024. 3. 21 최초작성 Age 컬럼의 값이 40인 행과 Age 컬럼의 값이 34이하인 행을 제거하는 예제코드입니다. import pandas as pd data = {'Name': ['John', 'Anna', 'Peter', 'Linda'], 'Age': [28, 34, 39, 40]} df = pd.DataFrame(data) print(df) print() # 'Age'가 40인 행의 인덱스를 찾기 indexes_to_drop = df[df['Age'] == 40].index # 해당 인덱스를 가진 행을 삭제 df.drop(indexes_to_drop, inplace=True) # 'Age'가 34 이하인 행의 인덱스를 찾기 i..
값 범위에 따라 컬럼 값을 변경하는 pandas 예제입니다. 2024. 3. 21 최초작성 label 컬럼에 있는 1에서 11 범위의 값을 주어진 조건에 따라 0과 1로 변경합니다. 컬럼의 값이 1~5이면 1로, 6~11이면 0으로 변경합니다. import pandas as pd # 1에서 11 범위를 갖는 값을 가진 label 컬럼이 포함된 데이터프레임을 생성합니다. df = pd.DataFrame({ 'label': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] }) # 컬럼에 포함된 값의 통계를 출력합니다. value_counts = df['label'].value_counts() print(value_counts) print('\n') # 'label' 컬럼의 값이 1~5이면 1..
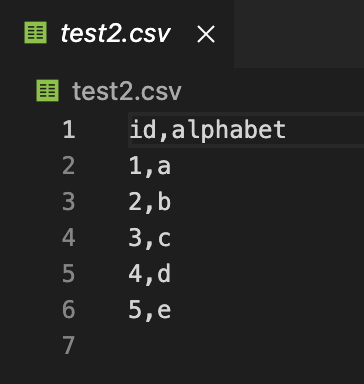
“10 minutes to pandas” 문서를 따라해보며 작성했습니다. https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html 열 이름의 위치가 맞지 않으니 실행하여 결과에서 확인하세요. 2022. 02. 02 최초작성 CSV 다음 내용으로 test.csv라는 파일을 작성합니다. 첫줄에 있는 컬럼 헤더에 공백이 없도록 주의하세요. Pandas에서 로드후 공백이 포함된 이름이 됩니다. id,alphabet 1,a 2,b 3,c 4,d 5,e 다음 코드로 csv 파일 로드 및 저장을 테스트합니다. import numpy as np import pandas as pd import matplotlib.pyplot as plt df = pd.rea..
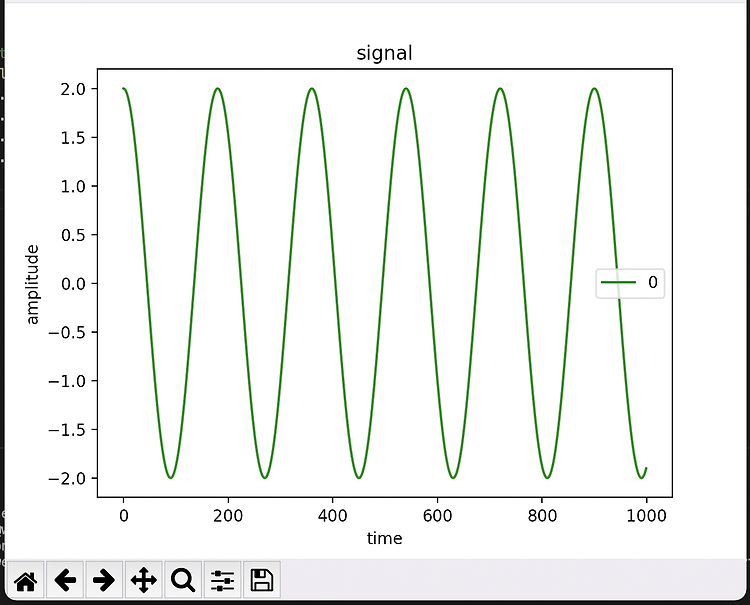
“10 minutes to pandas” 문서를 따라해보며 작성했습니다. https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html 2022. 02. 02 최초작성 matplotlib와 함께 사용하여 그래프를 그릴 수 있습니다. import numpy as np import pandas as pd import matplotlib.pyplot as plt t = np.arange(0, 1000) y = pd.DataFrame(2*np.cos(2*np.pi/180*t), index=t) # 다음 두 가지 방식으로 그래프를 그릴 수 있습니다. #plt.plot(y, c='green') y.plot(c='green') plt.title('signal'..
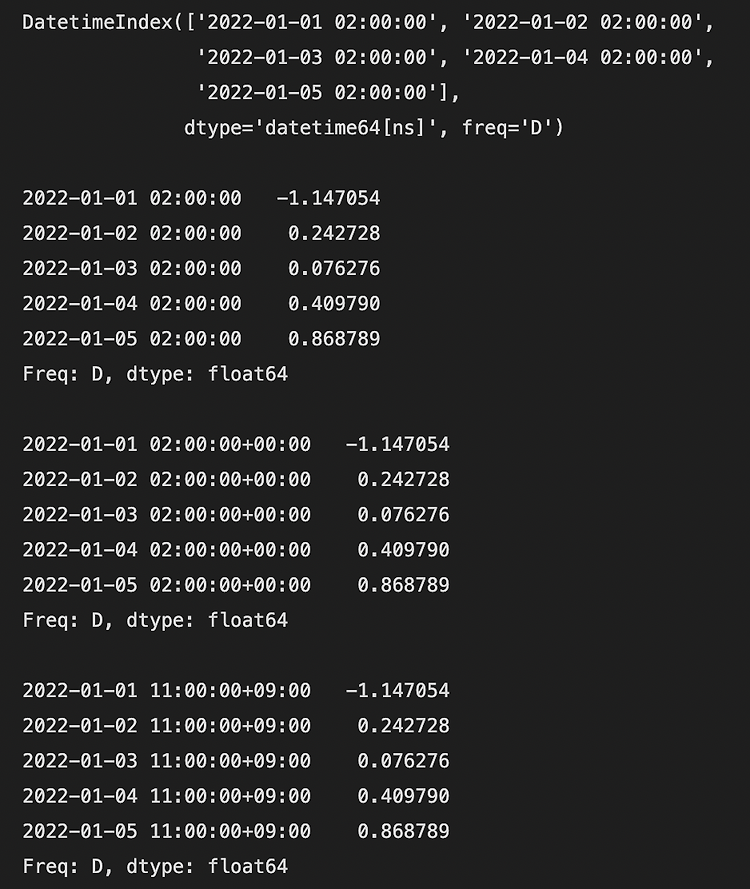
“10 minutes to pandas” 문서를 따라해보며 작성했습니다. https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html 2022. 02. 02 최초작성 2022. 3. 20 샘플링 특정 주기로 샘플링된 데이터를 원하는 주기로 리샘플링을 할 수 있습니다. import numpy as np import pandas as pd # 2022년 1월 1일 0시 0분 0초부터 1초 간격으로 20개를 생성합니다. rng = pd.date_range("1/1/2022", periods=20, freq="S") print(rng) print('\n\n') # 앞에서 생성한 시간정보를 인덱스로 하여 0 ~ 10 사이의 숫자를 20개 생성합니다. ts..
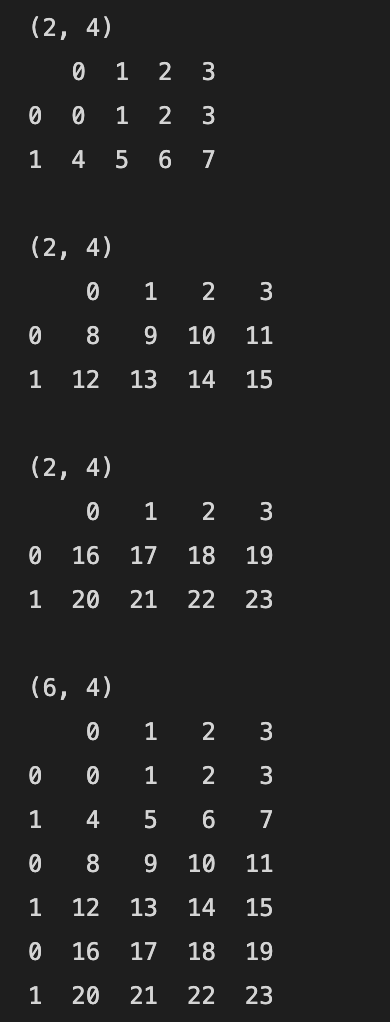
“10 minutes to pandas” 문서를 따라해보며 작성했습니다. https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html 2022. 02. 02 최초작성 2022. 03. 20 연결하기 concat 메소드를 사용하여 열방향으로 DataFrame을 연결합니다. import numpy as np import pandas as pd df1 = pd.DataFrame(np.arange(8).reshape(2,4)) print(df1.shape) print(df1) print() df2 = pd.DataFrame(np.arange(8,16).reshape(2,4)) print(df2.shape) print(df2) print() df3 = p..
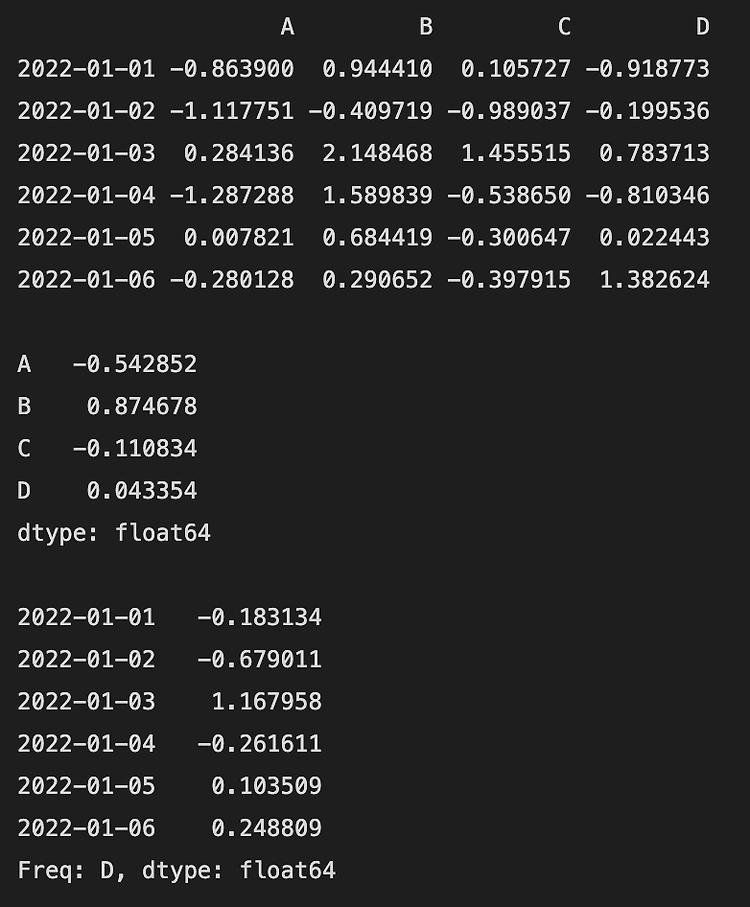
“10 minutes to pandas” 문서를 따라해보며 작성했습니다. https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html 2022. 02. 02 최초작성 2022. 03. 20 DataFrame이나 Series에 저장된 데이터에 대해 특정 연산을 수행하는 예제들입니다. 행 또는 열을 기준으로 평균을 구합니다. import numpy as np import pandas as pd dates = pd.date_range("20220101", periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD")) print(df) print() # 열을 기..

“10 minutes to pandas” 문서를 따라해보며 작성했습니다. https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html 2022. 1. 30 최초작성 2022. 3. 19 head에 지정한 개수만큼 DataFrame 상단의 행을 볼 수 있습니다. 디폴트 값은 5입니다. 여기에선 3으로 지정하고 있습니다. import numpy as np import pandas as pd df = pd.DataFrame(np.random.randn(20, 2), columns=list("AB")) print(df.head(3)) tail에 지정한 개수만큼 DataFrame 하단의 행을 볼 수 있습니다. 디폴트 값은 5입니다. 여기에선 3으로 지정했..
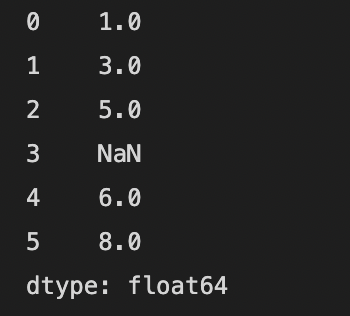
“10 minutes to pandas” 문서를 따라해보며 작성했습니다. https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html 2022. 01. 30 최초작성 2022. 12. 06 값이 저장되어 있는 리스트를 전달하여 Series 객체를 생성합니다. import numpy as np import pandas as pd series = pd.Series([1, 3, 5, np.nan, 6, 8]) print(series) 왼쪽 첫번째 열이 0부터 시작하는 인덱스 열이고 두번째 열이 리스트에 저장되어 있던 값입니다. 마지막 줄에 있는 dtype은 Series 객체에 저장되어 있는 값의 데이터 타입을 의미합니다. float64는 64비트 fl..