
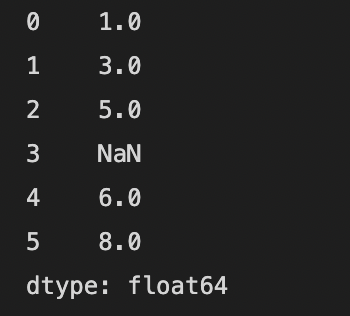
“10 minutes to pandas” 문서를 따라해보며 작성했습니다. https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html 2022. 01. 30 최초작성 2022. 12. 06 값이 저장되어 있는 리스트를 전달하여 Series 객체를 생성합니다. import numpy as np import pandas as pd series = pd.Series([1, 3, 5, np.nan, 6, 8]) print(series) 왼쪽 첫번째 열이 0부터 시작하는 인덱스 열이고 두번째 열이 리스트에 저장되어 있던 값입니다. 마지막 줄에 있는 dtype은 Series 객체에 저장되어 있는 값의 데이터 타입을 의미합니다. float64는 64비트 fl..
pandas의 read_csv 함수에 사용되는 경로 문자열 앞에 r을 붙이는 이유를 다룹니다. 2022. 12. 5 최초작성 read_csv 함수에 경로 문자열을 추가시 디렉토리 구분자로 \를 사용할 경우에 문제가 생길 수 있습니다. 디렉토리 이름이 n으로 시작하면 \n이 이스케이프 문자로 인식되어 문제가 되어 다음처럼 에러가 발생합니다. import pandas as pd df = pd.read_csv('.\new\test.csv') Traceback (most recent call last): File "d:\code\Python\pandas_read_csv.py", line 4, in df = pd.read_csv('.\new\test.csv') File "C:\Users\webnautes\mini..

pandas의 DataFrame에서 숫자가 아닌 값을 0으로 처리하는 예제입니다. 2023. 6. 17 최초작성 import pandas as pd # DataFrame 생성 df = pd.DataFrame([[1.5, '2.7', '3.2'], ['4.1', 5, '6.0']]) print(df) print() 해당 열의 값이 정수나 실수가 아니면 0으로 변경합니다. df[0] = df[0].apply(lambda x: x if isinstance(x, (int, float)) else 0) df[1] = df[1].apply(lambda x: x if isinstance(x, (int, float)) else 0) df[2] = df[2].apply(lambda x: x if isinstance(x,..
groupby를 사용하여 특정열 기준으로 DataFrame의 데이터 그룹 나누는 Pandas 예제 코드입니다. 2022. 10. 21 최초작성 import pandas as pd # DataFrame은 2개의 컬럼으로 구성되며 alphabet 컬럼의 값을 기준으로 그룹을 나누려고 합니다. data = pd.DataFrame([[1, 'a'],[2, 'a'],[3,'b'],[4,'b'],[5,'b'],[4,'c']], columns=['number', 'alphabet']) print(data) number alphabet 0 1 a 1 2 a 2 3 b 3 4 b 4 5 b 5 4 c # alphabet 컬럼의 값을 기준으로 그룹으로 묶을 수 있도록 합니다. groups = data.groupby('al..
Pandas의 read_csv 함수의 느린 속도를 개선하는 방법을 다룹니다. 2022. 03. 11 최초작성 csv 파일을 하나 읽어서 작업할 때에는 Pandas의 read_csv 함수가 느리다는 것을 알지 못했는데 대량의 csv 파일을(정확히는 196,032개) 로드해보니 느리다는 것을 알 수 있었습니다. 개선할 방법을 찾아보니 read_csv의 engine 아규먼트에 pyarrow를 지정하는 방법이 있었습니다. 앞에서 했던 196,032개의 csv 파일을 로드하는 시간이 3분에 1로 감소했습니다. df = pd.read_csv("large.csv", engine="pyarrow") 속도는 빨라지지만 단점이 있다면 기존 read_csv와 완벽히 호환이 안되서 nrows 같은 아규먼트를 사용할 수 없습니..
Pandas에서 drop을 사용하여 DataFrame의 열 또는 행을 삭제하는 예제입니다. 2022. 10. 31 최초작성 import pandas as pd df = pd.DataFrame({ 'alphabet': ['a', 'b', 'c', 'd'], 'integer' : [1, 2, 3, 4], 'blood type': ['A', 'B', 'AB', 'O'], }) print(df) ''' alphabet integer blood type 0 a 1 A 1 b 2 B 2 c 3 AB 3 d 4 O ''' # 행을 지우려면 행 인덱스 번호와 axis=0을 사용해야 합니다. # 두번째, 세번째 행이 삭제됩니다. df = df.drop([1,2], axis=0) print(df) ''' alphabet ..