

허깅페이스의 다음 문서를 정리했습니다. transformers 라이브러리를 사용하여 LLM을 사용하는 모든 것을 다루지는 않습니다. 좀 더 상세한 문서를 보기 전에 보면 좋을듯합니다. 원문에 있던 모델 파인튜닝하고 저장하는 방법은 제외했습니다.
Quick tour
https://huggingface.co/docs/transformers/quicktour
문서버전 V4.37.2
2024. 3. 1 최초작성
Transformer 라이브러리를 사용하면 다양한 작업을 다루는 사전학습된 대규모 언어 모델(Large Language Models, LLM)를 쉽게 다뤄볼 수 있습니다.
허깅페이스 허브( https://huggingface.co/models )에 공개된 다양한 작업의 사전학습된 모델을 로드하여 추론해볼 수 있고, 자신만의 데이터셋 또는 허깅페이스 허브에 공개된 데이터셋을 사용하도록 모델을 학습시킬 수 있습니다.
본 포스트에 있는 코드를 실행해보려면 다음 2개의 라이브러리를 설치해야 합니다.
pip install transformers datasets
transformers 라이브러리는 사전 학습된 모델을 다운로드하거나 로드하여 텍스트, 이미지, 음성 등의 데이터셋을 대상으로 다양한 작업을 수행할 수 있습니다.
datasets 라이브러리는 다양한 데이터셋을 로드하고 전처리하기 위한 도구를 제공합니다.
추가로 PyTorch, Tensorflow 중 선호하는 딥러닝 프레임워크를 설치해야 합니다. 설치 방법은 다음 포스트를 참고하세요.
원문에는 파이토치와 텐서플로우 코드를 모두 설명하고 있으나 본 포스트에서는 분량을 감안하여 파이토치의 경우만 다룹니다.
Ubuntu / Windows / WSL2에서 CUDA를 사용하는 Tensorflow / Pytorch 설치
https://webnautes.tistory.com/2254
MacBook M1에 PyTorch 설치하기
https://webnautes.tistory.com/2113
MacBook M1에 Tensorflow 설치하기
https://webnautes.tistory.com/2115
Pipeline
pipeline()은 사전 학습된 모델을 사용하여 추론을 할 수 있는 쉬운 방법입니다. 약간 더 복잡한 방법으로 generate()가 있으며 pipeline() 보다 성능이 더 좋은 듯합니다. pipeline()을 사용하면 사전 학습된 모델로 다양한 작업의 추론을 하기위한 준비작업을 쉽게 할 수 있습니다.
pipeline에서 사용할 수 있는 주요 작업 리스트입니다.

사용 가능한 작업의 전체 리스트는 아래 링크의 pipeline API 레퍼런스를 확인하세요.
https://huggingface.co/docs/transformers/main_classes/pipelines
pipeline의 사용 방법은 간단합니다. 사용할 작업과 사전학습된 모델을 지정하여 pipeline()의 인스턴스를 생성하기만 하면 됩니다. pipeline()은 특정 작업을 위한 사전 학습된 모델과 토크나이저( tokenizer)를 다운로드하고 디스크 공간에 캐시합니다. 다음 코드에서는 감정 분석(sentiment analysis)을 위한 pipeline()의 인스턴스를 생성합니다. 사전학습된 모델은 생략하고 있는데 이렇게하면 디폴트로 지정된 모델이 다운로드되는데 권장하지는 않는다고 합니다.
| from transformers import pipeline classifier = pipeline("sentiment-analysis") |
이제 원하는 문장을 pipeline() 인스턴스인 classifier의 입력으로 사용해볼 수 있습니다.
| classifier("We are very happy to show you the 🤗 Transformers library.") |
코드를 테스트해봅니다. 다음 전체 코드를 사용하세요.
| from transformers import pipeline classifier = pipeline("sentiment-analysis") print(classifier("We are very happy to show you the 🤗 Transformers library.")) |
실행해보면 추론 후, 주어진 문장에 대한 긍정/부정 여부와 점수가 다음처럼 출력됩니다.
다음 실행결과의 의미는 "We are very happy to show you the 🤗 Transformers library." 문장이 긍정일 가능성 점수가 0.9998라는 의미입니다.
[{'label': 'POSITIVE', 'score': 0.9998}]

입력으로 사용할 문장이 두 개 이상인 경우 문장들을 리스트로 묶어서 pipeline() 인스턴스인 classifier에 전달하면 됩니다. 추론 후, 딕셔너리가 원소인 리스트를 반환합니다:
| results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."]) for result in results: print(f"label: {result['label']}, with score: {round(result['score'], 4)}") |
다음 전체 코드를 사용하여 실행해 볼 수 있습니다.
| from transformers import pipeline classifier = pipeline("sentiment-analysis") results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."]) for result in results: print(f"label: {result['label']}, with score: {round(result['score'], 4)}") |
실행하면 "We are very happy to show you the 🤗 Transformers library." 문장은 긍정일 점수가 0.9998이고 "We hope you don't hate it." 문장은 부정일 점수가 0.5309입니다.
label: POSITIVE, with score: 0.9998
label: NEGATIVE, with score: 0.5309

pipeline()의 입력으로 데이터 세트를 사용할 수도 있습니다. 다음 예제 코드에서는 자동 음성 인식(automatic speech recognition)을 작업으로 선택해 보겠습니다. 모델로는 페이스북에서 배포한 "facebook/wav2vec2-base-960h"를 사용합니다.
| from transformers import pipeline speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h") |
이번엔 텍스트 데이터가 아닌 아닌 오디오 데이터를 다루어봅니다.
오디오 데이터 세트인 "PolyAI/minds14"를 로드합니다.
| from datasets import load_dataset, Audio dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") |
데이터 세트의 샘플링 속도가 앞에서 로드한 모델(facebook/wav2vec2-base-960h)이 학습할때 사용한 샘플링 속도와 일치시켜야 합니다. 샘플링 속도가 다르면 원하는 결과를 얻지 못합니다. 샘플링 레이트를 파이프라인 인스턴스(speech_recognizer)으로부터 가져와서 Audio 클래스를 사용하여 “audio”열에 있는 오디오 데이터의 샘플링 레이트를 변경합니다.
| dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate)) |
데이터 세트의 처음 4개의 샘플에서 원시 파형(raw waveform) 배열을 추출하여 pipeline 인스턴스 speech_recognizer에 리스트로 전달하여 얻은 result에서 인식된 텍스트를 가져와 출력합니다.
| result = speech_recognizer(dataset[:4]["audio"]) print([d["text"] for d in result]) |
다음 전체 코드를 사용하여 테스트해볼 수 있습니다.
실행해보기 전에 오디오를 다루는데 필요한 다음 패키지를 추가로 설치해야 합니다.
pip install soundfile librosa
| from transformers import pipeline from datasets import load_dataset, Audio speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h") dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate)) result = speech_recognizer(dataset[:4]["audio"]) print([d["text"] for d in result]) |
실행결과입니다. 4개의 오디오에서 인식된 문장 4개가 리스트에 담겨져 출력됩니다.
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HELL T WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AN I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I FURN A JOINA COUT']
입력이 큰 대규모 데이터 세트의 경우, 리스트 대신 제너레이터(generator)를 입력으로 사용하는 것이 좋습니다. 모든 데이터셋을 한꺼번에 메모리에 로드하기 힘들기 때문입니다.
pipeline에서 사용할 AutoClass와 AutoTokenizer 지정
이번엔 한국어 텍스트에 대한 감정 분석을 해봅니다. 허깅페이스 허브( https://huggingface.co/models )의 태그를 사용하여 필터링하면 적절한 모델을 찾을 수 있습니다.
Tasks 탭에 있는 Natural Languages Processing 항목에 있는 Text Classification을 선택합니다.
Languages 탭에서 Korean을 선택합니다.
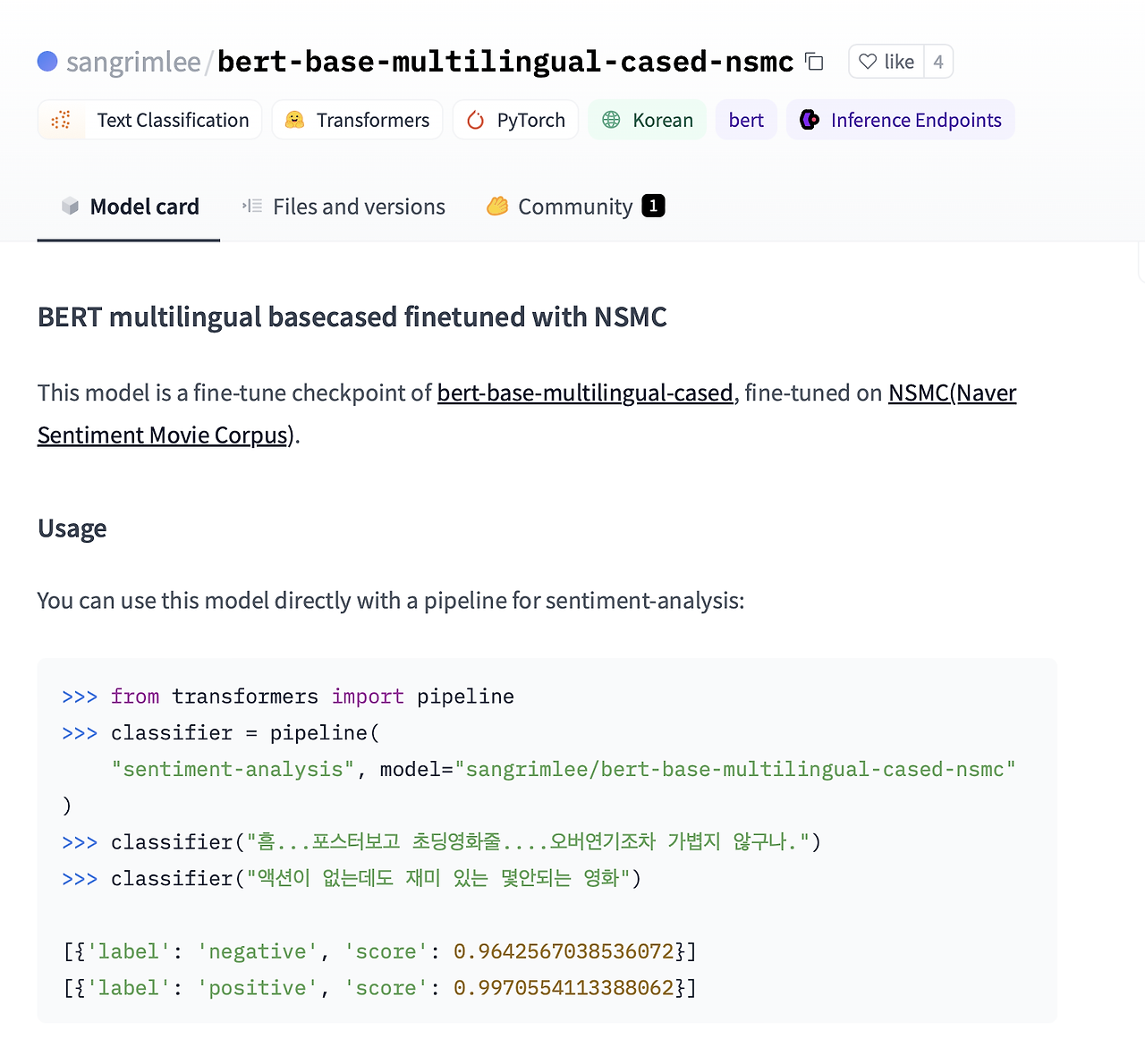
검색된 모델에서 sangrimlee/bert-base-multilingual-cased-nsmc를 선택해보니 감정분석 예제가 있네요. 이 모델을 사용해보겠습니다.
AutoModelForSequenceClassification 및 AutoTokenizer를 사용하여 사전 학습된 모델과 토크나이저를 로드합니다.
| from transformers import AutoTokenizer, AutoModelForSequenceClassification model_name = "sangrimlee/bert-base-multilingual-cased-nsmc" model = AutoModelForSequenceClassification.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name) |
pipeline() 인스턴스 생성시 작업으로 감정 분석을 지정하고 사용할 모델과 토크나이저를 지정합니다.
| from transformers import pipeline model_name = "sangrimlee/bert-base-multilingual-cased-nsmc" classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer) |
이제 classifier의 입력으로 한국어 텍스트를 사용하여 추론을 해볼 수 있습니다.
| print(classifier("나는 기분이 좋다")) print(classifier("나는 기분이 나쁘다")) |
다음 전체 코드를 사용하여 테스트해볼 수 있습니다.
| from transformers import AutoTokenizer, AutoModelForSequenceClassification from transformers import pipeline model_name = "sangrimlee/bert-base-multilingual-cased-nsmc" model = AutoModelForSequenceClassification.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name) classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer) print(classifier("나는 기분이 좋다")) print(classifier("나는 기분이 나쁘다")) |
실행결과입니다. “나는 기분이 좋다” 문장은 긍정일 점수가 약 0.89이며, “나는 기분이 나쁘다” 문장의 부정일 점수가 약 0.99입니다.
[{'label': 'positive', 'score': 0.8960141539573669}]
[{'label': 'negative', 'score': 0.9960733652114868}]
원하는 모델을 찾을 수 없는 경우에는 주어진 데이터셋에 대해 사전 학습된 모델을 미세 조정(파인 튜닝)해야 합니다.
AutoClass
위에서 사용한 pipeline()은 AutoModelForSequenceClassification 클래스와 AutoTokenizer 클래스가 함께 동작합니다. AutoModelForSequenceClassification 클래스같은 AutoClass를 사용하면 지정한 모델 이름이나 경로에서 사전 학습된 모델의 아키텍처를 자동으로 검색해줍니다. 원하는 작업과 필요한 전처리 클래스에 적합한 AutoClass를 선택하기만 하면 됩니다. AutoClass를 사용하지 않는다면 직접 모델의 아키텍처에 맞는 클래스를 선택해야 합니다.
이번엔 pipeline()없이 진행해보겠습니다.
AutoTokenizer
토크나이저는 텍스트를 모델에 입력할 수 있도록 숫자 배열로 변환하는 전처리하는 작업을 담당합니다. 토큰화 프로세스에서 단어를 분할하는 방법과 단어를 어느 수준으로 분할해야 하는지 등 여러 가지 토큰화 규칙이 적용됩니다. 기억해야 할 중요한 점은 모델이 사전 학습된 것과 동일한 토큰화 규칙을 사용하려면 모델 이름과 동일한 이름의 토크나이저를 인스턴스화해야 한다는 것입니다.
AutoTokenizer 클래스를 사용하여 토크나이저를 로드할때 모델 이름을 사용하는 것을 볼 수 있습니다.
| from transformers import AutoTokenizer model_name = "sangrimlee/bert-base-multilingual-cased-nsmc" tokenizer = AutoTokenizer.from_pretrained(model_name) |
토크나이저에 텍스트를 전달합니다:
| encoding = tokenizer("나는 기분이 좋다.") print(encoding) |
전체 코드입니다.
| from transformers import AutoTokenizer model_name = "sangrimlee/bert-base-multilingual-cased-nsmc" tokenizer = AutoTokenizer.from_pretrained(model_name) encoding = tokenizer("나는 기분이 좋다.") print(encoding) |
실행해보면 “나는 기분이 좋다.”라는 문장을 숫자로 바꾼 것을 볼 수 있습니다.
{'input_ids': [101, 100585, 8932, 37712, 10739, 9685, 11903, 119, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
토크나이저는 다음 항목을 포함하는 딕셔너리를 반환합니다:
input_ids : 텍스트를 분할하여 얻은 토큰을 숫자로 표시합니다.
attention_mask : 어떤 토큰에 주목해야 하는지를 나타냅니다.
토크나이저는 하나 이상의 텍스트가 저장되어 있는 inputs 리스트를 받아들이고 리스트에 있는 모든 텍스트의 길이가 똑같아지도록 패딩(pad)하거나 잘라내어(truncate) 균일한 길이의 배치(batch)를 반환할 수 있습니다:
| pt_batch = tokenizer( ["나는 기분이 나쁘다.", "나는 오늘 집에 빨리 가서 기분이 좋다."], # 두개의 텍스트의 길이가 다릅니다. padding=True, # 패딩을 허용합니다. max_length보다 텍스트 길이가 작은 경우 패딩을 합니다. truncation=True, # 잘라내기를 허용합니다. max_length보다 텍스트 길이가 긴 경우 텍스트의 일부를 잘라냅니다. max_length=512, # 최대 길이를 지정합니다. return_tensors="pt", # 반환 타입입니다. ) |
AutoModel
트랜스포머는 사전 학습된 인스턴스를 로드하는 간단하고 통합된 방법을 제공합니다. 즉, AutoTokenizer를 로드하는 것처럼 AutoModel을 로드할 수 있습니다. 토크나이저와 달리 작업에 적합한 AutoModel 클래스를 선택해야 합니다. 예를 들어 텍스트 분류의 경우에는 AutoModelForSequenceClassification 클래스를 사용하여 로드해야 합니다:
| from transformers import AutoModelForSequenceClassification model_name = "sangrimlee/bert-base-multilingual-cased-nsmc" pt_model = AutoModelForSequenceClassification.from_pretrained(model_name) |
AutoModel 클래스에서 지원하는 작업은 작업 요약을 참조하세요.(https://huggingface.co/docs/transformers/task_summary )
이제 전처리된 입력 배치를 모델에 직접 전달하세요. **를 추가하여 딕셔너리를 unpack하기만 하면 됩니다:
| pt_outputs = pt_model(**pt_batch) |
모델은 최종 활성화 결과를 로짓(logits) 속성으로 출력합니다. 확률로 변환하기 위해 로짓에 softmax 함수를 적용합니다:
| from torch import nn pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1) print(pt_predictions) |
최종 활성화 함수가 손실과 융합되는 경우가 많기 때문에 모든 Transformers 모델은 최종 활성화 함수(소프트맥스 등)가 적용되지 않은 텐서를 출력합니다. 모델 출력은 튜플 또는 딕셔너리(정수, 슬라이스 또는 문자열로 인덱싱할 수 있음)처럼 작동하며, 이 경우 None인 속성은 무시됩니다.
다음 전체 코드를 사용하여 테스트해볼 수 있습니다. .
| from transformers import AutoModelForSequenceClassification from transformers import AutoTokenizer from torch import nn model_name = "sangrimlee/bert-base-multilingual-cased-nsmc" tokenizer = AutoTokenizer.from_pretrained(model_name) pt_model = AutoModelForSequenceClassification.from_pretrained(model_name) pt_batch = tokenizer( ["나는 기분이 나쁘다.", "나는 오늘 집에 빨리 가서 기분이 좋다."], # 두개의 텍스트의 길이가 다릅니다. padding=True, # 패딩을 허용합니다. max_length보다 텍스트 길이가 작은 경우 패딩을 합니다. truncation=True, # 잘라내기를 허용합니다. max_length보다 텍스트 길이가 긴 경우 텍스트의 일부를 잘라냅니다. max_length=512, # 최대 길이를 지정합니다. return_tensors="pt", # 반환 타입입니다. ) pt_outputs = pt_model(**pt_batch) pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1) print(pt_predictions) |
실행결과 "나는 기분이 나쁘다." 문장은 부정일 가능성이 0.9940점, 긍정일 가능성이 0.0060점이고 "나는 오늘 집에 빨리 가서 기분이 좋다." 문장은 부정일 가능성이 0.0521점이고 긍정일 가능성이 0.9479점입니다.
tensor([[0.9940, 0.0060],
[0.0521, 0.9479]], grad_fn=<SoftmaxBackward0>)
'Deep Learning & Machine Learning > HuggingFace & Transformer' 카테고리의 다른 글
| Sentence Transformers 사용방법 (2) | 2025.01.05 |
|---|---|
| the current text generation call will exceed the model's predefined maximum length 해결방법 (0) | 2024.02.29 |
| colab에서 transformers 라이브러리로 LLM 학습시 checkpoint 사용하기 (0) | 2024.02.27 |
| Transformer 개념 정리 - Attention is all you need (0) | 2023.11.11 |
시간날때마다 틈틈이 이것저것 해보며 블로그에 글을 남깁니다.
블로그의 문서는 종종 최신 버전으로 업데이트됩니다.
여유 시간이 날때 진행하는 거라 언제 진행될지는 알 수 없습니다.
영화,책, 생각등을 올리는 블로그도 운영하고 있습니다.
https://freewriting2024.tistory.com
제가 쓴 책도 한번 검토해보세요 ^^



