

캐글의 딥러닝 튜토리얼을 바탕으로 정리한 문서입니다. 개인적으로 추가한 내용이 있어서 원문 내용에 차이가 있습니다.
Intro to Deep Learning
https://www.kaggle.com/learn/intro-to-deep-learning
추가로 참고
https://mongxmongx2.tistory.com/26
2022. 3. 3 최초작성
2022. 3. 20
Overfitting과 Underfitting
Keras는 모델을 훈련시키는 동안 train 데이터 세트를 여러번 입력으로 사용하게 됩니다. 한번 train 데이터 세트를 입력으로 사용할때마다 epoch가 1씩 증가하며 이때마다 compile 메소드로 지정한 메트릭인 훈련/검증 손실, 훈력/검증 정확도 등을 저장합니다.
학습 곡선 해석하기
train 데이터 세트의 정보는 신호와 잡음의 두 종류라고 생각할 수 있습니다. 신호는 일반화하는 부분으로, 우리 모델이 새로운 데이터로부터 예측하는 데 도움이 될 수 있는 부분이고 노이즈는 실제 데이터 및 모든 부수적인 데이터에서 발생하는 모든 무작위 데이터입니다. 즉 모델이 예측하는 데 실제로 도움이 되지 않습니다.
train 데이터 세트의 손실을 최소화하는 방향으로 학습을 진행하여 그에 맞는 가중치를 선택합니다. 이때 모델의 성능을 정확하게 평가하기위해 학습에 사용하지 않은 validation 데이터 세트를 사용하여 모델을 평가합니다. 이 평가를 통해 현재 모델의 학습이 Overfitting인지 알 수 있습니다.
아래 그림은 모델을 훈련할 때 training 데이터 세트의 손실과 validation 데이터 세트의 손실을 그래프로 나타냈습니다. X축은 epoch, Y축은 loss입니다. epoch만큼 train 데이터셋을 모델 학습에 사용시 loss가 어떻게 변했는지를 보여줍니다.

validation 손실은 학습에 사용하지 않은 데이터에서 학습중인 모델의 예상 오류의 추정치를 제공합니다.
위 그래프처럼 모델에 대한 학습이 진행됨에 따라(그래프가 오른쪽으로 이동함에 따라) train 손실은 줄어듭니다. 그러나 모델이 의미있는 신호를 학습할 때만 validation 손실이 줄어듭니다. 따라서 모델이 신호를 학습하면 train 손실과 validation 손실은 모두 감소하지만 노이즈를 학습하면 두 곡선 사이에 간격이 생깁니다. 이 간격이 클수록 모델이 노이즈를 많이 학습했을 가능성이 있습니다. 두 곡선의 차이가 거의 없고 일치해야 좋습니다.
이상적으로는 신호만 학습하고 노이즈는 학습하지 않아야 좋지만 그런 일은 거의 일어나지 않습니다.
그래서 노이즈를 많이 학습하는 대신 신호를 많이 학습하도록 해야 합니다. 신호를 많이 학습하고 있다면 validation 손실은 계속해서 감소하게 됩니다. 하지만 특정 epoch가 지난 후, 신호보단 노이즈를 많이 학습하여 validation 손실이 증가하는 상황이 생길 수 있습니다. 이를 Overfitting이라고 합니다.

Underfitting과 overfitting
모델을 학습할때 의미있는 데이터인 신호가 충분하지 않거나 노이즈가 너무 많은 두 가지 상황이 생길수 있습니다. Train 데이터 세트에 대해 학습시 Underfitting이 발생했다는 것은 모델이 신호를 충분히 학습하지 못했기 때문에 손실이 높은 상황으로 위 왼쪽 그림처럼 모델이 직선처럼 만들어져서 실제 데이터인 2차함수 그래프를 설명할 수 없는 경우입니다. Train 데이터 세트에 대해 학습시 Overfitting이 발생했다는 것은 모델이 신호보단 노이즈를 더 많이 학습했기 때문에 손실이 높은 상황으로 위 오른쪽 그림처럼 모델이 너무 실제 모습인 2차함수 그래프에 대해 많이 학습한 경우로 학습에 사용하지 않는 Test 데이터 세트를 모델에 적용시 모델이 이 데이터 세트를 설명할 수 없는 상황이 생깁니다. 따라서 딥러닝 모델을 학습 시킬때 신호가 충분하고 노이즈가 적도록 해야 합니다.
피자를 예로 들면 Underfitting은 피자가 원형이라는 점만 학습하여(너무 적은 개수의 특징만 학습) 시계도 원형이니 피자로 판단하는 것입니다. Overfitting은 올리브에 토핑으로 추가되어 있는 경우만 피자라고 학습하여(너무 많은 개수의 특징을 학습) 올리브가 토핑으로 추가되지 않은 피자는 피자가 아니라고 판단하는 것입니다.
모델의 복잡도와 테이터 세트의 양과 질때문에 오버피팅이 발생할 수 있습니다.
모델의 파라미터수가 많아지면 더 복잡한 것을 학습할 수 있는 모델이 되며 모델의 복잡도가 올라간다고 합니다. 하지만 모델의 복잡도가 올라간다고 성능이 좋아지는 것은 아닙니다. 올리브가 얹어진 피자만 피자로 판단한 것처럼 원하는 학습결과와 상관없는 특징까지 학습하여 오버피팅이 발생할 수 있습니다.
Train 데이터 세트에 올리브가 올라간 피자만 포함된 경우 올리브가 없는 피자는 피자로 인식하지 못하는 문제가 발생합니다. 올리브가 있는 피자와 올리브가 없는 피자가 모두 데이터 세트에 포함되어야 합니다.
오버피팅이란 모델이 Train 데이터 세트에 대해서 지나치게 훈련되어 Test 데이터 세트에 대해서는 결과가 안 좋은 경우입니다.

위 그림처럼 빨간색 점과 파란색 점이 흩어져 있을 때 빨간색 점과 파란색 점으로 분류하는 모델을 학습시킨 경우, 학습이 잘 이루어진 경우에는 검은색 선과 같이 파란색 점과 빨간색 점을 나누게 됩니다.
하지만 학습 데이터 세트에 대해 너무 학습이 잘되었다면(즉 오버피팅) 일어났을 경우 녹색 선과 같이 빨간색 점과 파란색 점을 나누게 됩니다.
이러한 오버피팅은 학습에 사용되지 않은 Test 데이터 세트에서 좋지 않은 분류 결과를 보여주게 됩니다.
Capacity
모델의 크기는 학습할 수 있는 패턴의 크기와 복잡성을 나타냅니다. 신경망의 경우 모델의 크기는 뉴런의 수와 레이어 연결 방법에 따라 결정됩니다.
주어진 Train 데이터 세트를 사용하여 신경망이 학습이 안되지 않으면 네트워크 크기를 늘려야 합니다.
이 네트워크 크기를 늘리는 방식은 다음 2가지입니다.
- 기존 레이어에 더 많은 유닛(뉴런)을 추가하여 네트워크를 더 넓게 만들기
- 더 많은 레이어를 추가하여 네트워크를 더 깊게 만들기
네트워크가 더 넓어지게 되면 선형적인 관계를 쉽게 배울 수 있는 반면 네트워크가 더 깊어지면 비선형적인 관계를 쉽게 배울 수 있게 됩니다.
두가지 방법 중 어느 것이 더 나은지는 학습에 사용하는 데이터 세트에 따라 다릅니다.
기본 신경망입니다.
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(1),
])
레이어의 유닛수를 증가시며 신경망을 넓게 만든 경우입니다.
wider = keras.Sequential([
layers.Dense(32, activation='relu'),
layers.Dense(1),
])
레이어 개수를 증가시켜서 신경망을 깊게 만든 경우입니다.
deeper = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1),
])
Early Stopping
모델이 노이즈를 너무 많이 학습하는 경우 학습 중에 validation 손실이 증가할 수 있습니다. 이를 방지하기 위해 검증 손실이 더 이상 감소하지 않는 시점에서 학습을 중단시킬 수 있습니다. 이렇게 학습을 중단시키는 것을 조기 중단(Early Stopping)이라고 합니다.

Validation 손실이 증가하기 시작할때에는 신경망의 가중치는 업데이트하지 않고 이전 값을 유지하도록 할 수 있습니다. 이렇게 하면 모델이 계속해서 노이즈를 학습하더라도 Overfitting이 발생하지 않습니다.
Early Stopping을 하게되면 너무 빨리 학습을 중지할 가능성이 줄어듬을 의미합니다. 따라서 Overfitting 상태로 학습되는 것을 방지하면서 동시에 충분히 학습하지 못한 Underfitting 상태가 되는 것도 방지할 수 있습니다. 학습할 epoch를 실제로 필요하다고 생각하는 것보다 더 크게 설정하고 학습을 시작하면 Early Stopping이 Validation 손실이 더 이상 감소하지 않는 상황을 감지하여 Overfitting이 발생하기전에 학습을 중단시켜줍니다.
Keras에서 Early Stopping 사용
Keras에서 Early Stopping을 사용하려면 콜백을 추가하면 됩니다. 콜백은 신경망이 훈련되는 동안 epoch 전후처럼 특정 시점에 실행되는 함수입니다.
Early Stopping 콜백은 epoch가 끝날때마다 실행됩니다. 이 시점에서 모델에 대한 loss가 측정되기 때문입니다. 보통 Validation 손실 상태를 확인하여 Early Stopping을 할 시점을 결정하도록 합니다.
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
min_delta=0.001, # 개선으로 간주되는 최소 변경 크기. 이 값만큼 개선이 없으면 Early Stopping 대상이 됩니다.
patience=20, # Early Stopping이 실제로 학습을 중지하기 전에 몇 epoch를 기다릴지를 의미합니다.
restore_best_weights=True, # Early Stopping시 이전에 찾은 최적의 가중치값으로 복원합니다.
)
위에서 지정한 파라미터의 의미는 "20개 에포크 동안 validation 손실이 0.001 이상 개선되지 않은 경우 훈련을 중지하고 이 시점에서 찾았던 최적의 가중치를 신경망이 유지하도록 한다"입니다.
예제 - Early Stopping를 적용한 모델 훈련
네트워크의 크기를 늘리면서 Overfitting을 방지하기 위해 Early Stopping 콜백을 fit 메소드에 추가합니다.
from tensorflow import keras
from tensorflow.keras import layers, callbacks
early_stopping = EarlyStopping(
min_delta=0.001, # 개선으로 간주되는 최소 변경 크기. 이 값만큼 개선이 없으면 Early Stopping 대상이 됩니다.
patience=20, # Early Stopping이 실제로 학습을 중지하기 전에 몇 epoch를 기다릴지를 의미합니다.
restore_best_weights=True, # Early Stopping시 이전에 찾은 최적의 가중치값으로 복원합니다.
)
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=[11]),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
model.compile(
optimizer='adam',
loss='mae',
)
EarlyStopping 콜백을 정의한 후 fit 메소드의 callbacks 인수로 추가합니다. 리스트에 콜백함수를 여러 개 넣어 추가할 수 있습니다. early stopping를 사용시 학습에 필요한 에포크보다 더 많은 수의 에포크를 선택합니다.
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=500,
callbacks=[early_stopping] # 콜백을 리스트에 추가합니다.
)
학습 결과 model의 fit 메소드의 epochs 아규먼트에 지정한 500 에포크가 완료되기 전에 학습이 중단된 것을 볼 수 있습니다.

Dropout
Overfitting을 해결하는 방법 중 하나가 모델에 드롭아웃 레이어를 추가하는 것입니다.
무작위로 선택된 히든 레이어의 일부 유닛이 동작하지 않게 하여 overfitting 되는 것을 막는 방법입니다.

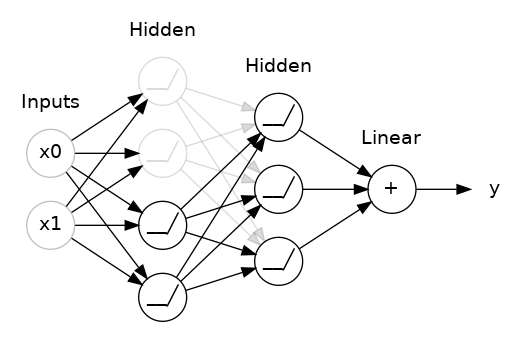
위 그림은 히든 레이어에 50% 드롭아웃을 추가한 경우입니다. 첫번째 히든 레이어에서 50%의 유닛만 다음에 오는 히든 레이어에 데이터를 전달하고 있습니다.
드롭아웃을 적용하며 실행할때마다 무작위로 레이어의 유닛이 삭제하기 때문에 실행할때 마다 다른 네트워크가 됩니다.
keras에서 Dropout 추가하기
Dropout 레이어의 rate 아규먼트에 차단할 입력 유닛의 백분율을 적어줍니다.
드롭아웃을 적용하려는 레이어 바로 앞에 드롭아웃 레이어를 배치합니다.
keras.Sequential([
layers.Dense(32),
layers.Dropout(rate=0.3), # 이전 레이어의 30%에 해당하는 유닛들만 다음 레이어에 데이터 전달하도록 함
layers.Dense(16),
# ...
])
Batch Normalization
배치 정규화를 모델에 적용하면 학습 속도가 느리거나 네트워크가 불안정한 경우 도움이 될 수 있습니다.
데이터 세트를 신경망 학습에 사용하기 전에 표준화(Standardization)나 정규화(Normalization)를 적용하여 모든 데이터가 공통 스케일로 만드는 것이 좋습니다. 데이터가 공통 스케일을 갖지 않는다면 학습이 불안정할 수 있습니다.
네트워크 내부에서도 이 정규화를 하도록 하기 위해 배치 정규화(Batch Normalization) 레이어를 추가합니다.
배치 정규화 레이어는 들어오는 각 배치(batch)에 대해 자체 평균과 표준 편차로 배치를 정규화 해줍니다.
keras에 Batch Normalization 레이어 추가
Batch Normalization 레이어를 추가하는 방법은 여러가지입니다.
레이어 뒤에 추가할 수도 있고
layers.Dense(16, activation='relu'),
layers.BatchNormalization(),
레이어와 활성화 함수 사이에 추가할 수도 있습니다.
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),
캐글 딥러닝 강좌 정리 1 - 뉴런(Neuron)과 깊은 신경망(DNN)
https://webnautes.tistory.com/2184
캐글 딥러닝 강좌 정리 2 - 확률적 경사 하강법(Stochastic Gradient Descent), 손실함수, 옵티마이저
https://webnautes.tistory.com/2185
캐글 딥러닝 강좌 정리 3 - 과적합(Overfitting)과 해결 방법(dropout, batch normalization)
https://webnautes.tistory.com/2186
'Deep Learning & Machine Learning > 강좌&예제 코드' 카테고리의 다른 글
| Tensorflow에서 재현 가능한 결과(reproducible results) 얻기 (0) | 2024.03.28 |
|---|---|
| onnx 파일의 shape 확인하기 (0) | 2023.11.05 |
| 캐글 딥러닝 강좌 정리 2 - 확률적 경사 하강법(Stochastic Gradient Descent), 손실함수, 옵티마이저 (0) | 2023.10.26 |
| 캐글 딥러닝 강좌 정리 1 - 뉴런(Neuron)과 깊은 신경망(DNN) (0) | 2023.10.26 |
| 이상치(Outlier) 제거하는 Python 예제 코드 (0) | 2023.10.23 |
시간날때마다 틈틈이 이것저것 해보며 블로그에 글을 남깁니다.
블로그의 문서는 종종 최신 버전으로 업데이트됩니다.
여유 시간이 날때 진행하는 거라 언제 진행될지는 알 수 없습니다.
블로그 글과 유튜브 영상을 만드는 것은 전문가라서라기보단 공부한 내용을 함께 공유하는 게 좋아서입니다.
제가 쓴 책도 한번 검토해보세요 ^^



