

괜찮은 파이토치 강좌를 찾아서 나름 다시 정리해본 결과를 공유합니다.
최초작성 2024. 12. 10
다음 포스트에 이어지는 내용입니다.
괜찮은 파이토치 강좌 - 01. 파이토치 기초
https://webnautes.tistory.com/2409
괜찮은 파이토치 강좌 - 02. 파이토치 워크플로 살펴보기
https://webnautes.tistory.com/2410
다음 문서를 기반으로 작성되었습니다. 코랩에서 실행한 결과를 정리했습니다.
https://www.learnpytorch.io/02_pytorch_classification/
분류 문제(Classification)
분류 문제는 주어진 대상이 미리 정해놓은 클래스 중에 어떤 것에 해당하는지 예측하는 문제입니다.
분류가 어떤 것인지 예를 들어보면 사진이 주어질때 사진 속에 있는 것이 개와 고양이 중 어느 쪽인지 예측하는 것입니다. 여기서 개와 고양이가 클래스입니다. 분류는 사진을 보고 예측한 것이 개와 고양이 클래스 중 어느 쪽에 속하는지 판단하게 됩니다.
만약 사진 속에 고양이와 개 중 하나가 아닌 오리가 있다면 어떻게 될까요. 보통은 개와 고양이 중 가까워 보이는 쪽을 예측한 결과를 보여줍니다. 개나 고양이가 아닌 경우 학습한 사진이 아니라고 출력하기 위한 고민이 필요하지만 본 문서에서는 다루지 않습니다.
분류 문제는 보통 다음 같은 세부 분류가 있습니다.
이진 분류(Binary classification)
주어진 대상은 두 가지 클래스 중 하나가 될 수 있습니다.
예) 주어진 이메일이 스팸 메일인지 정상 메일인지 분류합니다.
다중 분류(Multi-class classification)
주어진 대상은 두 가지 이상의 클래스 중 하나가 될 수 있습니다.
예) 주어진 손사진이 가위, 바위, 보 중 어떤 것인지 분류합니다.
다중 레이블 분류(Multi-label classification)
주어진 대상에 둘 이상의 클래스를 지정할 수 있습니다.
예) 위키백과에 있는 특정 문서는 수학, 과학, 철학같은 여러 카테고리에 속할 수 있습니다.
분류(Classification)는 회귀(Regression)와 함께 대표적인 머신 러닝 문제 유형 중 하나입니다.
본 글에서는 파이토치를 사용해 분류 문제를 다루어 보겠습니다. 일련의 입력을 받아 해당 입력이 어떤 클래스에 속하는지 예측하게 됩니다.
0. 분류 신경망의 아키텍처
분류 신경망의 일반적인 아키텍처를 살펴보겠습니다. 지금은 가볍게 읽고 지나쳐도 됩니다. 공부를 꾸준히 하다보면 어느 순간 아래 표에 있는 내용이 모두 이해될 때가 있습니다. 사용하는 데이터셋이나 학습시키려는 문제에 따라 달라질 수 있기 때문에 아래 표 내용이 정답은 아닙니다.

1. 분류 데이터를 만들고 준비하기
간단히 분류를 진행해보기 위해 가상의 데이터를 생성하여 사용합니다. 여기에선 분류에 사용할 데이터를 생성하기 위해 Scikit-Learn의 make_circles() 메서드를 사용하여 색상이 다른 두 개의 원을 구성하는 점들을 생성합니다.
| from sklearn.datasets import make_circles # 생성할 샘플 개수를 1000개로 지정합니다. n_samples = 1000 # 원을 생성합니다. X, y = make_circles(n_samples, noise=0.03, # 노이즈를 추가합니다. random_state=42) # 실행할때 마다 똑같은 데이터를 생성할 수 있도록 랜덤 시드를 설정합니다. |
X를 특징(feature)라고 부르고 y를 레이블(label)이라고 부릅니다. 분류 학습후 X를 모델에 제공하면 y와 똑같은 값을 모델이 출력으로 내놓도록 해야 합니다. X와 y의 처음 5개 값을 살펴보겠습니다.
| print(f"First 5 X features:\n{X[:5]}") print(f"\nFirst 5 y labels:\n{y[:5]}") |
First 5 X features:
[[ 0.75424625 0.23148074]
[-0.75615888 0.15325888]
[-0.81539193 0.17328203]
[-0.39373073 0.69288277]
[ 0.44220765 -0.89672343]]
First 5 y labels:
[1 1 1 1 0]
위 출력 결과를 보면 X의 샘플(하나의 데이터를 샘플이라고 부릅니다.)은 2개의 값으로 구성되어 있으며 y의 샘플은 한개의 값으로 구성되어 있습니다. 잘 학습된 모델이라면 X에 주어진 두 개의 값을 입력으로 받으면 y에 주어지는 하나의 값을 예측해야 합니다. 예를 들어 [ 0.75424625 0.23148074]가 주어지면 1을 예측해야 합니다.
데이터가 시각적으로 보기 좋도록 하기 위해 판다스의 데이터 프레임에 넣어 출력해보겠습니다.
| # 원 데이터를 데이터프레임으로 변환합니다. import pandas as pd circles = pd.DataFrame({"X1": X[:, 0], "X2": X[:, 1], "label": y }) circles.head(10) |
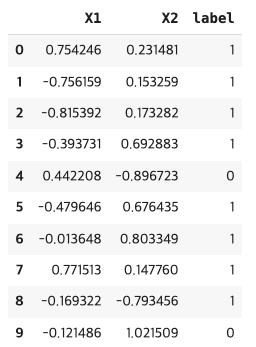
2개의 값으로 구성된 특징 X의 샘플에 한 개의 값으로 구성된 레이블의 y의 샘플이 주어지고 있습니다.
레이블 y의 값은 0 또는 1만 가지므로 이 데이터로 풀려고 하는 문제는 이진 분류라는 것을 알 수 있습니다.
아래처럼 레이블 값이 0인 것과 레이블 값이 1인 것의 개수를 세어보면 각각 500개입니다. 레이블 값이 0인 것과 레이블 값이 1인 것이 각각 클래스입니다. 이 경우 모든 클래스에 속한 샘플의 개수가 동일하기 때문에 균형 데이터셋입니다. 실제 상황에선 클래스 별로 속한 샘플의 개수가 다를 수 있습니다. 이 경우 불균형 데이터셋입니다.
| circles.label.value_counts() |
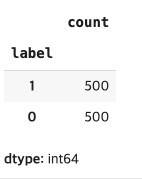
이제 데이터를 시각화 해보겠습니다.
| import matplotlib.pyplot as plt plt.scatter(x=X[:, 0], y=X[:, 1], c=y, cmap=plt.cm.RdYlBu); |
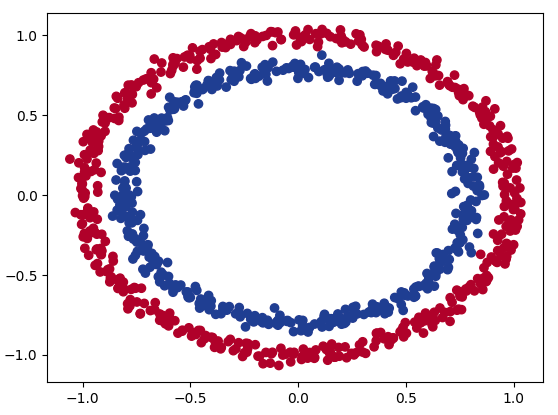
데이터를 시각화한 결과를 파란색 원을 구성하는 점과 빨간색 원을 구성하는 점이 있습니다. 파란색 원을 구성하는 점은 레이블이 1이며, 빨간색 원을 구성하는 점은 레이블이 0입니다.
본 글에서는 점을 빨간색(0) 또는 파란색(1)으로 분류하는 신경망을 만들어볼 것입니다.
1.1 입력 및 출력의 형태(shape)
입력으로 주어지는 특징 X의 형태(shape)와 출력으로 주어지는 레이블 y의 형태(shape)를 다음처럼 확인해볼 수 있습니다.
| X.shape, y.shape |
((1000, 2), (1000,))
특징과 레이블의 첫번째 차원의 개수가 1000으로 일치합니다. 1000개의 X와 1000개의 y가 있다는 의미입니다.
shape 출력값의 두번째 차원이 2인 것은 무슨 의미인지 확인하기 위해 샘플 하나를 출력해봅니다.
| X_sample = X[0] y_sample = y[0] print(f"Values for one sample of X: {X_sample} and the same for y: {y_sample}") print(f"Shapes for one sample of X: {X_sample.shape} and the same for y: {y_sample.shape}") |
Values for one sample of X: [0.75424625 0.23148074] and the same for y: 1
Shapes for one sample of X: (2,) and the same for y: ()
X의 샘플 하나의 shape가 (2,)입니다. 즉 샘플 하나에 2개의 값이 포함되어 있다는 의미합니다. y의 샘플 하나의 shape 출력시 ()가 출력된것은 y가 하나의 값(=스칼라)을 가지고 있다는 것을 의미합니다.
즉 특징 X의 shape 출력시 두 번째 차원의 값이 2라는 것의 의미는 X의 하나의 샘플이 두 개의 값을 가지고 있다는 의미하며 레이블 y의 shape 출력시 두번째 차원의 값이 없는 의미는 y의 하나의 샘플이 한 개의 값을 가지고 있다는 의미입니다.
정리해보면 두개의 값으로 구성된 샘플 1000개로 구성된 특징 X가 입력으로 주어지며, 하나의 값으로 구성된 샘플 1000개로 구성된 레이블 y가 출력으로 주어집니다.
1.2 데이터를 텐서로 변환하고 Train 및 Test 데이터 세트로 분할하기
현재 데이터는 Numpy 배열에 있으므로 파이토치에서 작업하려면 텐서로 변환해야 합니다.
| import torch X = torch.from_numpy(X).type(torch.float) y = torch.from_numpy(y).type(torch.float) # 5개의 샘플의 값을 출력해봅니다. X[:5], y[:5] |
(tensor([[ 0.7542, 0.2315],
[-0.7562, 0.1533],
[-0.8154, 0.1733],
[-0.3937, 0.6929],
[ 0.4422, -0.8967]]),
tensor([1., 1., 1., 1., 0.]))
이제 데이터를 Train 데이터 세트와 Test 데이터 세트로 나눕니다. Train 데이터 세트를 사용하여 모델을 학습시켜 X와 y 사이의 패턴을 학습한 다음 Test 데이터 데이터 세트을 사용하여 학습된 패턴을 평가합니다.
데이터를 Train 데이터 세트와 Test 데이터 세트로 나누기위해 Scikit-Learn의 train_test_split 함수를 사용합니다.
test_size=0.2로 설정하면 전체 데이터 중 80%는 Train 데이터 세트로 사용하고, 전체 데이터 중 20%는 Test 데이터 세트로 사용합니다.
이런 분할은 데이터 전체에서 무작위로 이루어지므로 실행할때 마다 똑같은 분할을 얻기 위해 랜덤 시드를 설정해야 합니다. 여기에선 랜덤 시드로 42를 사용합니다.
| from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) len(X_train), len(X_test), len(y_train), len(y_test) |
(800, 200, 800, 200)
이제 800개의 Train 데이터 세트 샘플과 200개의 Test 데이터 세트 샘플이 생겼습니다.
2. 모델 구축
데이터가 준비되었으니 이제 모델을 구축할 차례입니다.
먼저 torch 모듈과 torch.nn을 가져오고 GPU 사용 가능여부에 따라 device 변수의 값을 설정합니다.
| import torch from torch import nn device = "cuda" if torch.cuda.is_available() else "cpu" device |
cuda
이제 device 변수 값을 설정했으니 데이터와 모델이 GPU 또는 CPU에 같이 있도록 해야 합니다.
우선 모델을 만들어 보겠습니다. X(특징)가 주어지면 y(레이블)를 예측할 수 있는 모델이 필요합니다.
특징과 레이블이 있는 이런 구성을 지도 학습(supervised learning)이라고 합니다. 특정 데이터가 입력으로 모델에 주어졌을때(특징 X가 주어집니다.) 모델에서 입력에 대응하는 어떤 출력을 내놓아야 할지 알려주기 때문입니다.(레이블 y가 주어집니다.)
이러한 모델을 만들려면 모델의 입력으로 주어지는 특징 X의 형태(shape)와 모델의 출력으로 주어지는 레이블 y의 형태(shape)를 검토해야 합니다.
이제 다음 순서로 모델 클래스를 생성하고 인스턴스화합니다.
1. nn.Module의 서브클래스로 모델 클래스를 생성해야 합니다.
2. 생성자에서 X와 y의 입력 및 출력 형태(shape)를 처리할 수 있는 2개의 nn.Linear 레이어를 생성합니다.
3. 모델의 순방향 패스 계산을 담당하는 forward() 메서드를 정의합니다.
4. 이제 정의된 모델 클래스를 인스턴스화하여 device 변수에 정의된 장치로 모델을 전송합니다. 나중에 데이터도 device 변수에 정의된 장치로 전송해야 합니다.
| # 1. nn.Module의 서브클래스로 모델을 정의합니다. class CircleModelV0(nn.Module): def __init__(self): super().__init__() # 2. X와 y의 형태(shape)를 고려하여 nn.Linear를 구성합니다. self.layer_1 = nn.Linear(in_features=2, out_features=5) # 2개의 값을 입력받아(X의 값 개수와 동일합니다.) 5개의 값을 출력합니다. self.layer_2 = nn.Linear(in_features=5, out_features=1) # 5개의 값을 입력받아(앞 레이어의 출력 개수와 동일합니다.) 1개의 값을 출력합니다.(y의 값 개수와 동일합니다.) # 3. 순방향 패스 계산을 담당하는 forward 메서드를 정의합니다. def forward(self, x): # y의 값 개수와 동일한(shape가 동일한) layer_2의 출력을 리턴합니다. return self.layer_2(self.layer_1(x)) # 4. 모델의 인스턴스를 생성하고 device 변수의 값을 정의한 장치로 전송합니다. model_0 = CircleModelV0().to(device) model_0 |
CircleModelV0(
(layer_1): Linear(in_features=2, out_features=5, bias=True)
(layer_2): Linear(in_features=5, out_features=1, bias=True)
)
self.layer_1은 2개의 입력 피처 in_features=2를 가져와서 5개의 출력 피처 out_features=5를 생성합니다.
이 레이어는 입력 데이터의 2개 특징을 5개의 특징으로 바꿉니다. 5개의 특징은 5개의 히든 유닛 또는 뉴런을 의미합니다.
이렇게 하는 이유는 모델이 2개의 숫자가 아닌 5개의 숫자로부터 패턴을 학습할 수 있으므로, 잠재적으로 더 나은 결과를 얻을 수 있기 때문입니다. 잠재적이라는 표현을 쓴 이유는 항상 더 나은 결과를 얻는 것은 아니기 때문입니다.
신경망 레이어에서 사용할 수 있는 히든 유닛의 개수는 하이퍼파라미터 (사용자가 직접 설정할 수 있는 값)이며, 반드시 사용해야 하는 정해진 값은 없습니다.
일반적으로 히든 유닛의 개수가 많을수록 좋지만 너무 많으면 오히려 모델의 성능이 떨어지게 됩니다. 선택하는 개수는 모델 유형과 작업 중인 데이터 세트에 따라 달라집니다. 테스트를 통해 정해야 하는 것 같습니다.
본 글에서 사용하는 데이터 집합은 작고 단순하므로 히든 유닛의 개수를 작게 설정합니다.
히든 유닛의 개수 정할 때 규칙은 다음 레이어(이 경우 self.layer_2)가 이전 레이어 출력 개수와 동일한 개수의 입력값을 가져야 한다는 것입니다.
그렇기 때문에 self.layer_2의 in_features는 self.layer_1의 out_features와 동일하게 5입니다. 이렇게 self.layer_2는 self.layer_1의 입력을 받아 선형 계산을 수행하여 out_features=1(레이블 y와 같은 형태)로 바꾸게 됩니다.
nn.Sequential을 사용하여 위와 동일한 작업을 수행할 수도 있습니다. nn.Sequential은 레이어가 나타나는 순서대로 입력 데이터를 순방향으로 계산합니다.
| model_0 = nn.Sequential( nn.Linear(in_features=2, out_features=5), nn.Linear(in_features=5, out_features=1) ).to(device) model_0 |
Sequential(
(0): Linear(in_features=2, out_features=5, bias=True)
(1): Linear(in_features=5, out_features=1, bias=True)
)
nn.Sequential을 사용하는 것이 nn.Module을 서브클래싱하는 것보다 훨씬 간단해 보입니다. 하지만 nn.Sequential은 항상 순차 순서로 실행됩니다. 따라서 단순한 순차 연산이 아닌 다른 동작을 원한다면 nn.Module를 상속받아 모델을 정의해야 합니다.
이제 모델을 만들었으니니 데이터를 전달하면 어떤 일이 일어나는지 살펴봅시다. 특징 X를 모델에 제공하여 추론을 해본다는 의미입니다.
| untrained_preds = model_0(X_test.to(device)) print(f"Length of predictions: {len(untrained_preds)}, Shape: {untrained_preds.shape}") print(f"Length of test samples: {len(y_test)}, Shape: {y_test.shape}") print(f"\nFirst 10 predictions:\n{untrained_preds[:10]}") print(f"\nFirst 10 test labels:\n{y_test[:10]}") |
Length of predictions: 200, Shape: torch.Size([200, 1])
Length of test samples: 200, Shape: torch.Size([200])
First 10 predictions:
tensor([[-0.5710],
[-0.7108],
[-0.2414],
[-0.6642],
[-0.3000],
[-0.3849],
[-0.7321],
[-0.6560],
[-0.2394],
[-0.7208]], device='cuda:0', grad_fn=<SliceBackward0>)
First 10 test labels:
tensor([1., 0., 1., 0., 1., 1., 0., 0., 1., 0.])
모델의 예측 결과 untrained_preds와 Test 데이터 세트의 레이블 y_test의 값이 전혀 다른 값처럼 보입니다.
이 문제를 해결하기 위해 할 수 있는 몇 가지 단계가 있으며 뒤에서 살펴보겠습니다.
2.1 손실 함수 및 옵티마이저 설정하기
문제 유형에 따라 다른 손실 함수를 사용해야 합니다. 예를 들어 회귀 문제의 경우 평균 절대 오차(MAE) 손실 함수를 사용하고 이진 분류 문제의 경우에는 이진 교차 엔트로피를 손실함수로 사용할 수 있습니다.
옵티마이저의 경우엔 같은 옵티마이저를 여러 문제에서 사용하는 경우가 많습니다. 예를 들어 확률적 경사 하강 옵티마이저(SGD)와 아담 옵티마이저(Adam)의 경우 여러 문제에서 사용됩니다.
몇가지 손실함수와 옵티마이저 예입니다.

본 글에서는 이진 분류 문제를 다루고 있으므로 이진 교차 엔트로피 손실 함수를 사용해 보겠습니다.
손실 함수는 모델 예측이 얼마나 잘못되었는지를 측정하는 것으로, 손실이 클수록 모델이 잘못되었다는 것을 의미합니다.
파이토치에는 두 가지 이진 교차 엔트로피 구현이 있습니다:
1. torch.nn.BCELoss() 대상(레이블)과 입력(특징) 사이의 이진 교차 엔트로피를 측정하는 손실 함수를 생성합니다.
2. torch.nn.BCEWithLogitsLoss() 시그모이드 레이어 nn.Sigmoid가 내장되어 있다는 점을 제외하면 위와 동일합니다.
torch.nn.BCEWithLogitsLoss()에 대한 문서에 따르면 nn.Sigmoid 레이어 뒤에 torch.nn.BCELoss()를 사용하는 것보다 수치적으로 더 안정적이라고 명시되어 있습니다.
따라서 일반적으로 구현 2가 더 나은 옵션입니다. 본 글에서는 구현 2를 사용합니다.
그러나 고급 사용을 위해 nn.Sigmoid와 torch.nn.BCELoss()의 조합을 분리할 수도 있지만 이는 본 글의 범위를 벗어납니다.
이제 손실 함수와 옵티마이저 함수를 정의해 보겠습니다.
옵티마이저의 경우 torch.optim.SGD()를 사용하여 학습률 0.1로 모델 파라미터를 최적화하겠습니다.
| # 손실함수(loss function) # loss_fn = nn.BCELoss() # BCELoss = no sigmoid built-in loss_fn = nn.BCEWithLogitsLoss() # BCEWithLogitsLoss = sigmoid built-in # 옵티마이저(optimizer) optimizer = torch.optim.SGD(params=model_0.parameters(), lr=0.1) |
이제 평가 지표도 만들어 보겠습니다.
평가 지표는 모델의 학습이 어떻게 진행되고 있는지에 대한 또 다른 관점을 제공하는 데 사용할 수 있습니다.
손실 함수가 모델이 얼마나 틀렸는지를 측정한다면, 평가 지표는 모델이 얼마나 올바른지를 측정하는 것으로 생각하면 좋습니다.
물론 이 두 가지가 궁극적으로 같은 일을 한다고 볼 수 있지만 평가 지표는 손실함수와는 다른 관점을 제공합니다. 모델을 평가할 때는 다양한 관점에서 바라보는 것이 좋습니다.
분류 문제에 사용할 수 있는 평가 지표는 여러 가지가 있지만 여기에서 정확도(accuracy)를 사용합니다. 정확도는 정확히 예측한 횟수를 총 예측 횟수로 나눈것입니다.
예를 들어 100개 중 99개를 정확히 예측하는 모델은 정확도가 99%입니다.
정확도를 측정하는 함수를 작성해 보겠습니다.
| def accuracy_fn(y_true, y_pred): correct = torch.eq(y_true, y_pred).sum().item() # torch.eq()는 2개의 텐서가 동일한지 계산합니다. acc = (correct / len(y_pred)) * 100 return acc |
이제 이 함수를 사용하여 모델을 학습시키면서 손실과 함께 성능을 측정할 수 있습니다.
3. Train 모델
이제 손실 함수와 옵티마이저가 준비되었으니 모델을 학습시켜 보겠습니다.
파이토치 Train 루프 단계를 다시 복습해봅니다.
포워드 패스 - 모델이 모든 학습 데이터를 한 번 통과하여 forward() 함수 계산을 수행합니다(model(x_train)).
손실 계산 - 모델의 출력(예측)을 기준 실측치와 비교하여 얼마나 잘못되었는지 평가합니다(loss = loss_fn(y_pred, y_train)).
제로 그라데이션 - 특정 학습 단계에 대해 다시 계산할 수 있도록 옵티마이저 그라데이션을 0으로 설정합니다.(왜냐하면 옵티마이저는 계속 누적만 하기 때문입니다. )(optimizer.zero_grad()).
손실에 대한 역전파 수행 - 업데이트할 모든 모델 파라미터( requires_grad = True인 각 파라미터)에 대해 손실의 기울기를 계산합니다. 이를 역전파라고 하며, 또는 “역방향”(loss.backward())이라고 합니다.
최적화 단계(경사 하강) - 손실 경사도를 개선하기 위해 손실 경사도와 관련하여 requires_grad=True로 파라미터를 업데이트합니다(optimizer.step()).
3.1 모델 출력을 예측 레이블로 변환하기
학습 루프 단계 전에 포워드 패스(forward() 메서드로 정의됨) 동안 모델에서 어떤 결과가 나오는지 살펴봅시다.
| # Test 데이터 세트에 대한 포워드 패스의 처음 5개 출력을 확인합니다. y_logits = model_0(X_test.to(device))[:5] y_logits |
tensor([[-0.5710],
[-0.7108],
[-0.2414],
[-0.6642],
[-0.3000]], device='cuda:0', grad_fn=<SliceBackward0>)
모델이 아직 학습되지 않았기 때문에 지금 보이는 출력은 무작위값입니다.
이 출력은 forward() 메서드의 출력으로 내부적으로 다음 방정식을 호출하는 2개의 nn.Linear 레이어로 구현됩니다.
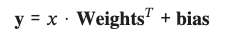
방정식 ( 𝐲 )의 출력 또는 모델의 출력을 로짓(logits)이라고 부릅니다.
모델이 입력 데이터 (방정식의 𝑥 또는 코드의 X_test)를 받아 출력하는 것이 바로 이 로짓입니다. 이러한 숫자는 해석하기 어렵습니다.
Test 데이터 세트의 정답값인 레이블과 비교할 수 있는 숫자인 1 또는 0을 결과로 내놓아야 합니다. 모델의 출력인 로짓을 이러한 형태로 변환하기 위해 시그모이드 활성화 함수를 사용할 수 있습니다.
| y_pred_probs = torch.sigmoid(y_logits) y_pred_probs |
tensor([[0.3610],
[0.3294],
[0.4399],
[0.3398],
[0.4255]], device='cuda:0', grad_fn=<SigmoidBackward0>)
모델의 출력에 시그모이드 함수를 적용한 후, 이제 출력에 어느 정도 일관성이 있는 것 같습니다(하지만 여전히 무작위값입니다.)
이제 이 값은 예측 확률의 형태로, 즉 모델이 특정 데이터가 특정 클래스에 속한다고 생각하는 정도를 나타냅니다.
여기에선 이진 분류를 다루기 때문에 이상적인 출력은 0 또는 1입니다.
0에 가까울수록 모델은 샘플이 클래스 0에 속한다고 판단하고, 1에 가까울수록 모델은 샘플이 클래스 1에 속한다고 바꿔야 합니다.
- If y_pred_probs >= 0.5, y=1 (class 1)
- If y_pred_probs < 0.5, y=0 (class 0)
즉, 예측 확률을 예측 레이블로 바꾸려면 시그모이드 활성화 함수의 출력을 반올림하면 됩니다.
| # Find the predicted labels (round the prediction probabilities) y_preds = torch.round(y_pred_probs) # In full y_pred_labels = torch.round(torch.sigmoid(model_0(X_test.to(device))[:5])) # Check for equality print(torch.eq(y_preds.squeeze(), y_pred_labels.squeeze())) # Get rid of extra dimension y_preds.squeeze() |
tensor([True, True, True, True, True], device='cuda:0')
tensor([0., 0., 0., 0., 0.], device='cuda:0', grad_fn=<SqueezeBackward0>)
다음처럼 y_test의 값을 출력해보면 이제 모델의 예측이 Test 데이터 세트의 레이블 y(y_test)와 같은 형태인 것처럼 보입니다.
| y_test[:5] |
tensor([1., 0., 1., 0., 1.])
모델의 예측을 Test 데이터 세트의 레이블과 비교하면 모델이 얼마나 에측을 잘하는지 확인할 수 있습니다.
요약하자면, 시그모이드 활성화 함수를 사용하여 모델의 출력(로짓)을 예측 확률로 변환하고 예측 확률을 반올림하여 예측 레이블로 변환했습니다.
시그모이드 활성화 함수는 이진 분류에서 사용되며 다중 클래스 분류의 경우에는 소프트맥스 활성화 함수를 사용합니다.
그리고 모델의 출력을 nn.BCEWithLogitsLoss에 전달할 때 시그모이드 활성화 함수를 사용할 필요가 없습니다. 그 이유는 시그모이드 함수가 내장되어 있기 때문입니다.
3.2 Training 및 Testing 루프 구축하기
지금까지 모델의 출력을 예측 레이블로 변환하는 방법에 대해 설명했으니 이제 학습 루프를 구축해 보겠습니다.
100개의 에포크에 대해 학습하고 10개의 에포크마다 모델의 진행 상황을 출력하는 것으로 시작하겠습니다.
| torch.manual_seed(42) # 에포크 개수 epochs = 100 # 데이터 세트를 GPU(GPU를 사용할 수없는 경우 CPU)로 옮깁니다. X_train, y_train = X_train.to(device), y_train.to(device) X_test, y_test = X_test.to(device), y_test.to(device) for epoch in range(epochs): ### 학습 루프 # Train 모드로 설정합니다. model_0.train() # 1. 모델 내에 있는 forward 메소드를 사용하여 Train 데이터에 대한 Forward pass를 진행하여 추론 결과를 얻습니다. y_logits = model_0(X_train).squeeze() # 여분의 차원을 제거합니다. y_pred = torch.round(torch.sigmoid(y_logits)) # 로짓을 예측 레이블로 변환합니다. # 2. 손실과 정확도를 계산합니다. # loss = loss_fn(torch.sigmoid(y_logits), # Using nn.BCELoss you need torch.sigmoid() # y_train) loss = loss_fn(y_logits, # Using nn.BCEWithLogitsLoss works with raw logits y_train) acc = accuracy_fn(y_true=y_train, y_pred=y_pred) # 3. 그레디언트를 초기화합니다. optimizer.zero_grad() # 4. 역전파를 수행합니다. loss.backward() # 5. 모델의 파라미터를 업데이트합니다. optimizer.step() ### 테스트 루프 # 평가 모드로 설정합니다. model_0.eval() # 추론에 필요없는 기능을 끄도록 추론 모드 컨텍스트 관리자를 사용합니다. with torch.inference_mode(): # 1. 모델 내에 있는 forward 메소드를 사용하여 Test 데이터에 대한 Forward pass를 진행하여 추론 결과를 얻습니다. 여분의 차원을 제거합니다. test_logits = model_0(X_test).squeeze() # 로짓을 예측 레이블로 변환합니다. test_pred = torch.round(torch.sigmoid(test_logits)) # 2. 손실과 정확도를 계산합니다. test_loss = loss_fn(test_logits, y_test) test_acc = accuracy_fn(y_true=y_test, y_pred=test_pred) # 10 에포크마다 로그를 출력합니다. if epoch % 10 == 0: print(f"Epoch: {epoch} | Loss: {loss:.5f}, Accuracy: {acc:.2f}% | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%") |
Epoch: 0 | Loss: 0.72360, Accuracy: 50.00% | Test loss: 0.71465, Test acc: 50.00%
Epoch: 10 | Loss: 0.70676, Accuracy: 46.38% | Test loss: 0.69953, Test acc: 47.50%
Epoch: 20 | Loss: 0.70010, Accuracy: 44.88% | Test loss: 0.69393, Test acc: 49.00%
Epoch: 30 | Loss: 0.69725, Accuracy: 47.25% | Test loss: 0.69192, Test acc: 50.50%
Epoch: 40 | Loss: 0.69588, Accuracy: 47.88% | Test loss: 0.69128, Test acc: 54.00%
Epoch: 50 | Loss: 0.69511, Accuracy: 48.12% | Test loss: 0.69117, Test acc: 53.50%
Epoch: 60 | Loss: 0.69462, Accuracy: 48.62% | Test loss: 0.69127, Test acc: 53.50%
Epoch: 70 | Loss: 0.69428, Accuracy: 48.50% | Test loss: 0.69146, Test acc: 54.00%
Epoch: 80 | Loss: 0.69402, Accuracy: 48.88% | Test loss: 0.69168, Test acc: 53.00%
Epoch: 90 | Loss: 0.69383, Accuracy: 48.75% | Test loss: 0.69191, Test acc: 53.00%
모델의 학습 중 로그를 보면 훈련과 테스트 단계를 잘 수행하고 있지만 학습이 진행됨에 따라 모델의 성능이 향상되는 것 같지 않습니다. 정확도(Accuracy)가 50%를 넘지 못하고 있습니다.
4. 예측을 하고 모델 평가하기
출력된 평가지표 Accuracy의 값이 50%대라서 모델이 무작위로 추측하는 것처럼 보입니다.
시각화하여 어떤 의미인지 확인해보겠습니다.
모델의 예측, 예측하려는 데이터, 그리고 어떤 것이 클래스 0인지 클래스 1인지에 대한 결정 경계를 도표로 만들어 보겠습니다.
이를 위해 다음처럼 학습용 파이토치 딥러닝 리포지토리에서 helper_functions.py 스크립트를 다운로드한 후, 사용하겠습니다.
여기에는 모델이 특정 클래스를 예측하는 여러 지점을 시각적으로 그리기 위해 NumPy 메시 그리드를 생성하는 plot_decision_boundary()라는 유용한 함수가 포함되어 있습니다. 이 함수를 임포트합니다.
또한 나중에 사용하기 위해 앞 강좌에서 사용했던 plot_predictions()을 임포트합니다.
| import requests from pathlib import Path # Download helper functions from Learn PyTorch repo (if not already downloaded) if Path("helper_functions.py").is_file(): print("helper_functions.py already exists, skipping download") else: print("Downloading helper_functions.py") request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/helper_functions.py") with open("helper_functions.py", "wb") as f: f.write(request.content) from helper_functions import plot_predictions, plot_decision_boundary |
Downloading helper_functions.py
| # Plot decision boundaries for training and test sets plt.figure(figsize=(12, 6)) plt.subplot(1, 2, 1) plt.title("Train") plot_decision_boundary(model_0, X_train, y_train) plt.subplot(1, 2, 2) plt.title("Test") plot_decision_boundary(model_0, X_test, y_test) |
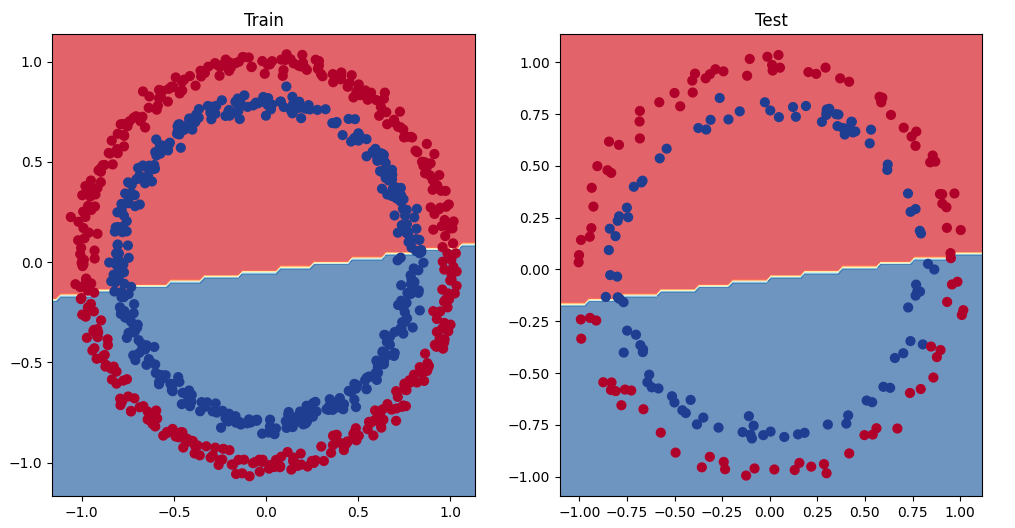
시각화해보니 모델의 성능 문제의 원인을 찾은 것 같습니다. 현재 직선을 사용하여 빨간색과 파란색 점을 분할하려고 시도하고 있습니다.
그래서 50%의 정확도가 나왔던 거네요. 지금 사용중인 데이터는 원형이기 때문에 직선을 그리면 위 그림처럼 중간만 잘릴 수 있습니다.
즉, 현재 사용중인 모델로는 빨간점과 파란점을 분리할 수 었습니다.
이를 어떻게 개선할 수 있을까요?
5. 비선형성(non-linearity)
모델이 직선이 아닌 비선형 선을 그릴 수 있도록 해봅시다.
5.1 비선형성이 있는 모델 구축하기
현재 살펴보고 있는 데이터는 원모양의 비선형 데이터입니다.
모델에 비선형 활성화 함수를 추가하면 어떤 일이 일어날까요?
비선형 활성화 함수 중 일반적이고 성능이 좋은 것 중 하나는 ReLU입니다.
포워드 패스의 히든 레이어 사이에 있는 신경망에 ReLU 활성화 함수를 추가하여 어떤 일이 일어나는지 살펴봅시다.
| from torch import nn class CircleModelV2(nn.Module): def __init__(self): super().__init__() self.layer_1 = nn.Linear(in_features=2, out_features=10) self.layer_2 = nn.Linear(in_features=10, out_features=10) self.layer_3 = nn.Linear(in_features=10, out_features=1) self.relu = nn.ReLU() # 모델에 ReLU 활성화 함수를 추가합니다. # Can also put sigmoid in the model # This would mean you don't need to use it on the predictions # self.sigmoid = nn.Sigmoid() def forward(self, x): # 레이어 사이에 relu 함수를 추가합니다. return self.layer_3(self.relu(self.layer_2(self.relu(self.layer_1(x))))) model_3 = CircleModelV2().to(device) print(model_3) |
CircleModelV2(
(layer_1): Linear(in_features=2, out_features=10, bias=True)
(layer_2): Linear(in_features=10, out_features=10, bias=True)
(layer_3): Linear(in_features=10, out_features=1, bias=True)
(relu): ReLU()
)
신경망을 구성할 때 비선형 활성화 함수를 어디에 넣어야 하나요?
경험상 히든 레이어 사이와 출력 레이어 바로 뒤에 배치하는 것이 좋지만, 정해진 구성 방법은 없습니다. 신경망과 딥 러닝에 대해 자세히 알아가면서 다양한 구성 방법을 발견하게 될 것입니다. 그전까지는 실험해보는 것이 좋습니다.
이제 모델이 준비되었으니 이진 분류 손실 함수와 옵티마이저를 생성합니다.
| loss_fn = nn.BCEWithLogitsLoss() optimizer = torch.optim.SGD(model_3.parameters(), lr=0.1) |
5.2 비선형성을 사용한 모델 훈련하기
모델, 손실 함수, 옵티마이저가 준비되었으니 이제 훈련 및 테스트 루프를 만들어 보겠습니다.
| # 랜덤 시드를 설정합니다. torch.manual_seed(42) # 에포크 개수 epochs = 1000 # 데이터 세트를 GPU(GPU를 사용할 수없는 경우 CPU)로 옮깁니다. X_train, y_train = X_train.to(device), y_train.to(device) X_test, y_test = X_test.to(device), y_test.to(device) for epoch in range(epochs): # 1. 모델 내에 있는 forward 메소드를 사용하여 Train 데이터에 대한 Forward pass를 진행하여 추론 결과를 얻습니다. 여분의 차원을 제거합니다. y_logits = model_3(X_train).squeeze() # 로짓을 예측 레이블로 변환합니다. y_pred = torch.round(torch.sigmoid(y_logits)) # 2. 손실과 정확도를 계산합니다. loss = loss_fn(y_logits, y_train) # BCEWithLogitsLoss calculates loss using logits acc = accuracy_fn(y_true=y_train, y_pred=y_pred) # 3. 그레디언트를 초기화합니다. optimizer.zero_grad() # 4. 역전파를 수행합니다. loss.backward() # 5. 모델의 파라미터를 업데이트합니다. optimizer.step() ### Testing # 평가 모드로 설정합니다. model_3.eval() # 추론에 필요없는 기능을 끄도록 추론 모드 컨텍스트 관리자를 사용합니다. with torch.inference_mode(): # 1. 모델 내에 있는 forward 메소드를 사용하여 Test 데이터에 대한 Forward pass를 진행하여 추론 결과를 얻습니다. 여분의 차원을 제거합니다. test_logits = model_3(X_test).squeeze() # 로짓을 예측 레이블로 변환합니다. test_pred = torch.round(torch.sigmoid(test_logits)) # 2. 손실과 정확도를 계산합니다. test_loss = loss_fn(test_logits, y_test) test_acc = accuracy_fn(y_true=y_test, y_pred=test_pred) # 100 에포크마다 로그를 출력합니다. if epoch % 100 == 0: print(f"Epoch: {epoch} | Loss: {loss:.5f}, Accuracy: {acc:.2f}% | Test Loss: {test_loss:.5f}, Test Accuracy: {test_acc:.2f}%") |
Epoch: 0 | Loss: 0.69295, Accuracy: 50.00% | Test Loss: 0.69319, Test Accuracy: 50.00%
Epoch: 100 | Loss: 0.69115, Accuracy: 52.88% | Test Loss: 0.69102, Test Accuracy: 52.50%
Epoch: 200 | Loss: 0.68977, Accuracy: 53.37% | Test Loss: 0.68940, Test Accuracy: 55.00%
Epoch: 300 | Loss: 0.68795, Accuracy: 53.00% | Test Loss: 0.68723, Test Accuracy: 56.00%
Epoch: 400 | Loss: 0.68517, Accuracy: 52.75% | Test Loss: 0.68411, Test Accuracy: 56.50%
Epoch: 500 | Loss: 0.68102, Accuracy: 52.75% | Test Loss: 0.67941, Test Accuracy: 56.50%
Epoch: 600 | Loss: 0.67515, Accuracy: 54.50% | Test Loss: 0.67285, Test Accuracy: 56.00%
Epoch: 700 | Loss: 0.66659, Accuracy: 58.38% | Test Loss: 0.66322, Test Accuracy: 59.00%
Epoch: 800 | Loss: 0.65160, Accuracy: 64.00% | Test Loss: 0.64757, Test Accuracy: 67.50%
Epoch: 900 | Loss: 0.62362, Accuracy: 74.00% | Test Loss: 0.62145, Test Accuracy: 79.00%
학습을 진행함에 따라 정확도가 점점 상승하고 있습니다. 모델 성능이 좋아진거 같습니다.
5.3 비선형 활성화 함수로 훈련된 모델 평가하기
비선형 활성화 함수를 추가하여 학습한 모델의 예측을 확인해보겠습니다.
| model_3.eval() with torch.inference_mode(): y_preds = torch.round(torch.sigmoid(model_3(X_test))).squeeze() # 10개의 추론 결과와 정답 레이블을 출력하여 비교해봅니다. y_preds[:10], y[:10] |
(tensor([1., 0., 1., 0., 0., 1., 0., 0., 1., 0.], device='cuda:0'),
tensor([1., 1., 1., 1., 0., 1., 1., 1., 1., 0.]))
추론 결과를 시각화해봅니다.
| # Plot decision boundaries for training and test sets plt.figure(figsize=(12, 6)) plt.subplot(1, 2, 1) plt.title("Train") plot_decision_boundary(model_0, X_train, y_train) # model_1 = no non-linearity plt.subplot(1, 2, 2) plt.title("Test") plot_decision_boundary(model_3, X_test, y_test) # model_3 = has non-linearity |
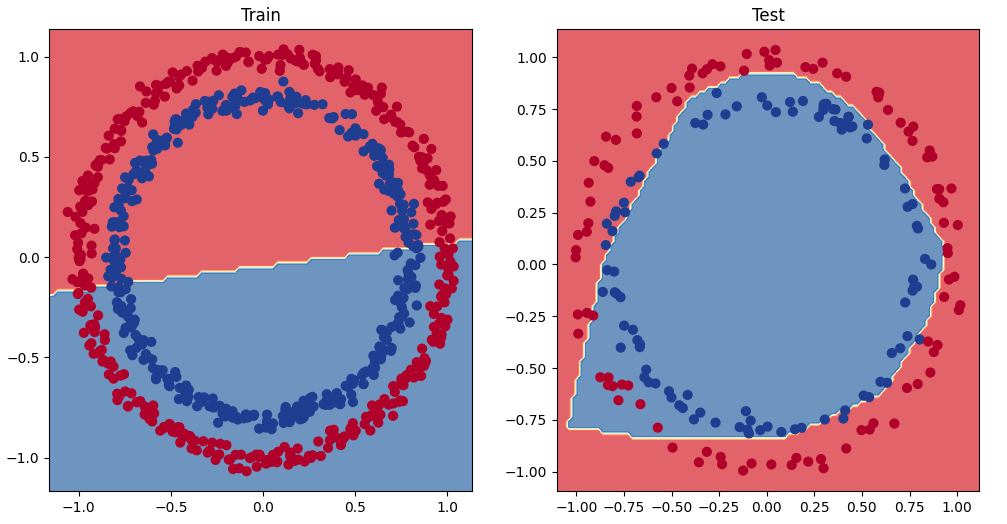
완벽하지는 않지만 그래도 이전보다는 훨씬 나아졌습니다.
6. 다중 클래스 PyTorch 모델을 구축하여 통합하기
이제 다중 클래스 분류 문제를 사용하여 모든 것을 종합해 보겠습니다.
이진 분류 문제는 두 가지 클래스(예: 사진을 고양이 또는 개로 분류) 중 하나로 분류하는 문제인 반면, 다중 클래스 분류 문제는 두 가지 이상의 클래스(예: 사진을 고양이, 개 또는 오리로 분류)중 하나로 분류합니다.
6.1 다중 클래스 분류 데이터 만들기
다중 클래스 분류 데이터를 생성해 보겠습니다.
이를 위해 Scikit-Learn의 make_blobs() 메서드를 활용할 수 있습니다. 이 메서드는 centers 매개 변수를 사용하여 원하는 만큼의 클래스를 생성합니다.
1. make_blobs()로 다중 클래스 데이터를 생성합니다.
2. 데이터를 텐서로 변환합니다(make_blobs()을 사용하여 생성된 데이터의 데이터타입은 NumPy 배열입니다)
3. train_test_split()을 사용하여 데이터를 Train 데이터 세트와 Test 데이터 세트로 분할합니다.
4. 데이터를 시각화합니다.
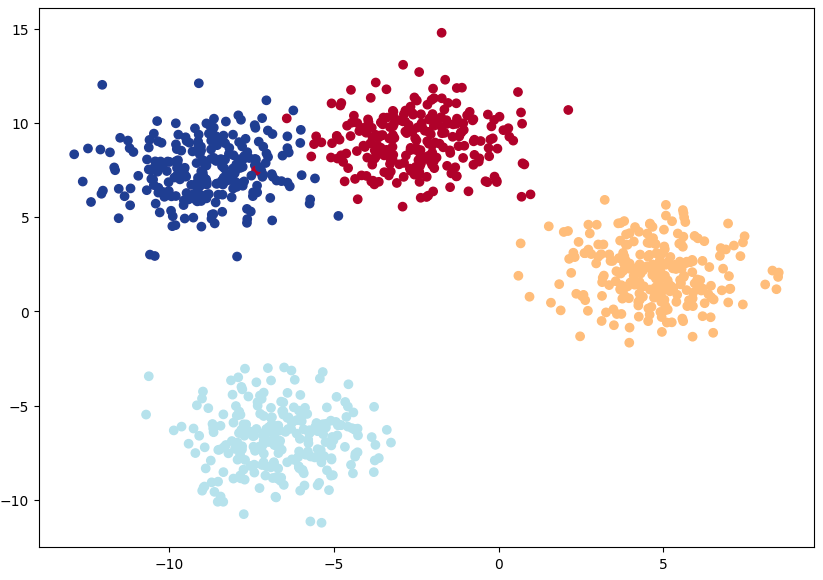
| import torch import matplotlib.pyplot as plt from sklearn.datasets import make_blobs from sklearn.model_selection import train_test_split NUM_CLASSES = 4 # 출력 클래스 개수 NUM_FEATURES = 2 # 입력 특징 개수 RANDOM_SEED = 42 # 랜덤시드 # 다중 클래스 데이터를 생성합니다. X_blob, y_blob = make_blobs(n_samples=1000, # 1000개의 샘플 데이터를 생성합니다. n_features=NUM_FEATURES, # 입력 X의 특징 개수를 2개로 설정합니다. centers=NUM_CLASSES, # 출력 y의 레이블 개수를 4개로 설정합니다 cluster_std=1.5, # give the clusters a little shake up (try changing this to 1.0, the default) random_state=RANDOM_SEED # 랜덤시드 ) # 2. 데이터를 텐서로 변환합니다. X_blob = torch.from_numpy(X_blob).type(torch.float) y_blob = torch.from_numpy(y_blob).type(torch.LongTensor) # 5개의 샘플 데이터를 출력합니다. 입력은 값 2개로 구성되어 있고 출력은 값 1개로 구성된걸 확인할 수 있습니다. print(X_blob[:5], y_blob[:5]) # 3. Train 데이터 세트와 Test 데이터 세트로 분리합니다 X_blob_train, X_blob_test, y_blob_train, y_blob_test = train_test_split(X_blob, y_blob, test_size=0.2, random_state=RANDOM_SEED) # 4. 데이터를 시각화합니다. plt.figure(figsize=(10, 7)) plt.scatter(X_blob[:, 0], X_blob[:, 1], c=y_blob, cmap=plt.cm.RdYlBu); |
tensor([[-8.4134, 6.9352],
[-5.7665, -6.4312],
[-6.0421, -6.7661],
[ 3.9508, 0.6984],
[ 4.2505, -0.2815]]) tensor([3, 2, 2, 1, 1])
6.2 파이토치에서 다중 클래스 분류 모델 구축하기
다중 클래스 데이터를 처리할 수 있는 모델을 만들어 보겠습니다.
이를 위해 세 개의 하이퍼파라미터를 파라미터로 하는 nn.Module의 서브클래스를 만들어 보겠습니다
input_features - 모델에 제공되는 입력 X의 특징의 개수입니다.
output_features - 예상되는 출력 y의 특징의 개수로 다중 클래스 분류 문제에선 클래스 개수와 동일합니다.
hidden_units - 각 히든 레이어에서 사용할 히든 뉴런의 개수입니다.
우선 GPU를 사용할 수 있는 여부에 따라 변수 device의 값을 설정합니다.
| device = "cuda" if torch.cuda.is_available() else "cpu" device |
cuda
이제 모델을 생성합니다.
| from torch import nn class BlobModel(nn.Module): def __init__(self, input_features, output_features, hidden_units=8): """Initializes all required hyperparameters for a multi-class classification model. Args: input_features (int): Number of input features to the model. out_features (int): Number of output features of the model (how many classes there are). hidden_units (int): Number of hidden units between layers, default 8. """ super().__init__() self.linear_layer_stack = nn.Sequential( nn.Linear(in_features=input_features, out_features=hidden_units), # nn.ReLU(), # <- does our dataset require non-linear layers? (try uncommenting and see if the results change) nn.Linear(in_features=hidden_units, out_features=hidden_units), # nn.ReLU(), # <- does our dataset require non-linear layers? (try uncommenting and see if the results change) nn.Linear(in_features=hidden_units, out_features=output_features), # how many classes are there? ) def forward(self, x): return self.linear_layer_stack(x) # BlobModel의 인스턴스를 생성하고 device에 설정된 장치로 모델을 전송합니다. model_4 = BlobModel(input_features=NUM_FEATURES, output_features=NUM_CLASSES, hidden_units=8).to(device) model_4 |
BlobModel(
(linear_layer_stack): Sequential(
(0): Linear(in_features=2, out_features=8, bias=True)
(1): Linear(in_features=8, out_features=8, bias=True)
(2): Linear(in_features=8, out_features=4, bias=True)
)
)
6.3 다중 클래스 파이토치 모델을 위한 손실 함수 및 옵티마이저 생성하기
다중 클래스 분류 문제를 다루고 있으므로 손실 함수로 nn.CrossEntropyLoss() 메서드를 사용하겠습니다.
손실함수로는 모델의 파라미터를 최적화하기 위해 학습률이 0.1인 SGD를 사용하겠습니다.
| loss_fn = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model_4.parameters(), lr=0.1) |
6.4 다중 클래스 파이토치 모델에 대한 예측 확률 구하기
학습을 시작하기 전에 모델의 추론이 동작하는지 테스트해봅니다.
| model_4(X_blob_train.to(device))[:5] |
tensor([[-1.2711, -0.6494, -1.4740, -0.7044],
[ 0.2210, -1.5439, 0.0420, 1.1531],
[ 2.8698, 0.9143, 3.3169, 1.4027],
[ 1.9576, 0.3125, 2.2244, 1.1324],
[ 0.5458, -1.2381, 0.4441, 1.1804]], device='cuda:0',
grad_fn=<SliceBackward0>)
각 샘플의 특징당 하나의 값을 얻었습니다. 형태(shape)를 확인하여 확인해 보겠습니다.
| model_4(X_blob_train.to(device))[0].shape, NUM_CLASSES |
(torch.Size([4]), 4)
주어진 특징 X의 샘플을 입력으로 모델이 추론한 결과 4개의 값을 내놓았고 각각 각 클래스에 속할 값을 의미합니다.
지금 얻은 모델의 출력을 로짓이라고 부릅니다. 이 값으로는 정확한 예측인지 알 수 없기에 소프트맥스 활성화 함수를 적용해야 합니다
소프트맥스 함수는 모델의 출력으로 얻은 4개의 값을 각각 클래스에 속할 확률로 바꾸어 줍니다.
| # Test 데이터 세트의 X를 입력으로 추론해봅니다. y_logits = model_4(X_blob_test.to(device)) # 모델 출력에 소프트맥스를 적용합니다. y_pred_probs = torch.softmax(y_logits, dim=1) print(y_logits[:5]) print(y_pred_probs[:5]) |
tensor([[-1.2549, -0.8112, -1.4795, -0.5696],
[ 1.7168, -1.2270, 1.7367, 2.1010],
[ 2.2400, 0.7714, 2.6020, 1.0107],
[-0.7993, -0.3723, -0.9138, -0.5388],
[-0.4332, -1.6117, -0.6891, 0.6852]], device='cuda:0',
grad_fn=<SliceBackward0>)
tensor([[0.1872, 0.2918, 0.1495, 0.3715],
[0.2824, 0.0149, 0.2881, 0.4147],
[0.3380, 0.0778, 0.4854, 0.0989],
[0.2118, 0.3246, 0.1889, 0.2748],
[0.1945, 0.0598, 0.1506, 0.5951]], device='cuda:0',
grad_fn=<SliceBackward0>)
소프트맥스 함수의 출력은 여전히 무작위 숫자처럼 보일 수 있지만(모델이 학습되지 않았고 무작위 패턴을 사용하여 예측하기 때문에 실제로도 그렇습니다), 차이가 있습니다.
모델의 출력을 변환하여 각 클래스에 속할 확률로 바꾸는데 그 합은 1이 되도록합니다. 확인해봅시다.
| torch.sum(y_pred_probs[0]) |
tensor(1., device='cuda:0', grad_fn=<SumBackward0>)
이러한 예측 확률은 기본적으로 모델이 대상 X 샘플(입력)이 각 클래스에 얼마나 매핑된다고 생각하는지를 나타냅니다.
y_pred_probs에 있는 하나의 샘플에 저장된 4개의 값은 각 클래스에 속할 확률을 의미하므로 가장 높은 확률 값의 인덱스가 바로 주어진 해당 X 특징의 샘플로부터 추론된 클래스입니다. 즉 해당 클래스에 속한다는 의미입니다.
가장 높은 값을 가진 인덱스는 torch.argmax()를 사용하여 확인할 수 있습니다.
| # Which class does the model think is *most* likely at the index 0 sample? print(y_pred_probs[0]) print(torch.argmax(y_pred_probs[0])) |
tensor([0.1872, 0.2918, 0.1495, 0.3715], device='cuda:0',
grad_fn=<SelectBackward0>)
tensor(3, device='cuda:0')
torch.argmax()의 출력으로 3이 반환되었습니다. 특징 X의 인덱스 0에 해당하는 샘플에 대해 모델은 가장 가능성이 높은 클래스 값(y)으로 3을 예측하고 있습니다.
물론 지금은 무작위로 추측하는 것이므로 맞을 확률은 25%입니다(4개의 클래스가 있기 때문에). 학습을 진행하면 개선할 수 있습니다.
6.5 다중 클래스 파이토치 모델을 위한 트레이닝 및 테스트 루프 생성하기
이제 모든 준비 단계가 끝났으니 모델을 개선하고 평가하기 위한 훈련 및 테스트 루프를 작성해 보겠습니다.
유일한 차이점은 모델 출력(로짓)을 예측 확률(소프트맥스 활성화 함수 사용)로 전환한 다음 예측 레이블(소프트맥스 활성화 함수 출력의 인자를 취하여)로 전환하는 단계를 조정한다는 것입니다. 모델을 에포크=100으로 훈련하고 10개의 에포크마다 평가해 보겠습니다.
| # 랜덤 시드를 설정합니다. torch.manual_seed(42) # 에포크 개수 epochs = 100 # 데이터 세트를 GPU(GPU를 사용할 수없는 경우 CPU)로 옮깁니다. X_blob_train, y_blob_train = X_blob_train.to(device), y_blob_train.to(device) X_blob_test, y_blob_test = X_blob_test.to(device), y_blob_test.to(device) for epoch in range(epochs): ### 학습 루프 # Train 모드로 설정합니다. model_4.train() # 1. 모델 내에 있는 forward 메소드를 사용하여 Train 데이터에 대한 Forward pass를 진행하여 추론 결과를 얻습니다. y_logits = model_4(X_blob_train) # 로짓을 예측 레이블로 변환합니다. y_pred = torch.softmax(y_logits, dim=1).argmax(dim=1) # 2. 손실과 정확도를 계산합니다. loss = loss_fn(y_logits, y_blob_train) acc = accuracy_fn(y_true=y_blob_train, y_pred=y_pred) # 3. 그레디언트를 초기화합니다. optimizer.zero_grad() # 4. 역전파를 수행합니다. loss.backward() # 5. 모델의 파라미터를 업데이트합니다. optimizer.step() ### 테스트 루프 # 평가 모드로 설정합니다. model_4.eval() # 추론에 필요없는 기능을 끄도록 추론 모드 컨텍스트 관리자를 사용합니다. with torch.inference_mode(): # 1. 모델 내에 있는 forward 메소드를 사용하여 Test 데이터에 대한 Forward pass를 진행하여 추론 결과를 얻습니다. test_logits = model_4(X_blob_test) # 로짓을 예측 레이블로 변환합니다. test_pred = torch.softmax(test_logits, dim=1).argmax(dim=1) # 2. 손실과 정확도를 계산합니다. test_loss = loss_fn(test_logits, y_blob_test) test_acc = accuracy_fn(y_true=y_blob_test, y_pred=test_pred) # 10 에포크마다 로그를 출력합니다. if epoch % 10 == 0: print(f"Epoch: {epoch} | Loss: {loss:.5f}, Acc: {acc:.2f}% | Test Loss: {test_loss:.5f}, Test Acc: {test_acc:.2f}%") |
Epoch: 0 | Loss: 1.04324, Acc: 65.50% | Test Loss: 0.57861, Test Acc: 95.50%
Epoch: 10 | Loss: 0.14398, Acc: 99.12% | Test Loss: 0.13037, Test Acc: 99.00%
Epoch: 20 | Loss: 0.08062, Acc: 99.12% | Test Loss: 0.07216, Test Acc: 99.50%
Epoch: 30 | Loss: 0.05924, Acc: 99.12% | Test Loss: 0.05133, Test Acc: 99.50%
Epoch: 40 | Loss: 0.04892, Acc: 99.00% | Test Loss: 0.04098, Test Acc: 99.50%
Epoch: 50 | Loss: 0.04295, Acc: 99.00% | Test Loss: 0.03486, Test Acc: 99.50%
Epoch: 60 | Loss: 0.03910, Acc: 99.00% | Test Loss: 0.03083, Test Acc: 99.50%
Epoch: 70 | Loss: 0.03643, Acc: 99.00% | Test Loss: 0.02799, Test Acc: 99.50%
Epoch: 80 | Loss: 0.03448, Acc: 99.00% | Test Loss: 0.02587, Test Acc: 99.50%
Epoch: 90 | Loss: 0.03300, Acc: 99.12% | Test Loss: 0.02423, Test Acc: 99.50%
6.6 파이토치 다중 클래스 모델로 예측하기 및 평가하기
학습을 진행함에 따라 정확도가 99%가 나온것을 보면 학습된 모델이 꽤 잘 작동하는 것 같습니다.
하지만 이를 확인하기 위해 예측 결과를 시각화해 보겠습니다.
| # 예측을 해봅니다. model_4.eval() with torch.inference_mode(): y_logits = model_4(X_blob_test) # 처음 10개의 값을 출력합니다. y_logits[:10] |
tensor([[ 4.3377, 10.3539, -14.8948, -9.7642],
[ 5.0142, -12.0371, 3.3860, 10.6699],
[ -5.5885, -13.3448, 20.9894, 12.7711],
[ 1.8400, 7.5599, -8.6016, -6.9942],
[ 8.0726, 3.2906, -14.5998, -3.6186],
[ 5.5844, -14.9521, 5.0168, 13.2890],
[ -5.9739, -10.1913, 18.8655, 9.9179],
[ 7.0755, -0.7601, -9.5531, 0.1736],
[ -5.5918, -18.5990, 25.5309, 17.5799],
[ 7.3142, 0.7197, -11.2017, -1.2011]], device='cuda:0')
지금 얻은 모델의 출력은 로짓입니다. 실제로 클래스에 속할 확률인 예측값으로 변환하기 위해 소프트맥스를 적용합니다.
| # Turn predicted logits in prediction probabilities y_pred_probs = torch.softmax(y_logits, dim=1) # Turn prediction probabilities into prediction labels y_preds = y_pred_probs.argmax(dim=1) # Compare first 10 model preds and test labels print(f"Predictions: {y_preds[:10]}\nLabels: {y_blob_test[:10]}") print(f"Test accuracy: {accuracy_fn(y_true=y_blob_test, y_pred=y_preds)}%") |
Predictions: tensor([1, 3, 2, 1, 0, 3, 2, 0, 2, 0], device='cuda:0')
Labels: tensor([1, 3, 2, 1, 0, 3, 2, 0, 2, 0], device='cuda:0')
Test accuracy: 99.5%
이제 모델 예측 결과를 테스트 데이터 세트의 레이블과 비교해볼 수 있게 되었으며 정확도가 99.5%로 성능이 좋습니다.
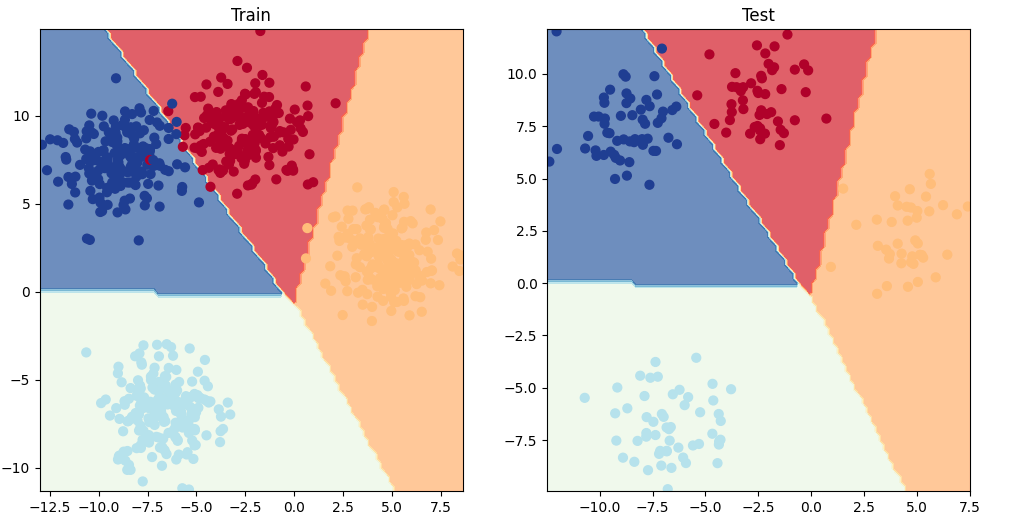
plot_decision_boundary()를 사용해 추론 결과를 시각화해 보겠습니다. 데이터가 GPU에 있으므로 matplotlib에서 사용하려면 데이터를 CPU로 옮겨야 합니다(plot_decision_boundary()가 자동으로 이 작업을 수행합니다).
학습에 사용하지 않은 Test 데이터 세트에 대한 분류 결과도 좋은 편입니다.
| plt.figure(figsize=(12, 6)) plt.subplot(1, 2, 1) plt.title("Train") plot_decision_boundary(model_4, X_blob_train, y_blob_train) plt.subplot(1, 2, 2) plt.title("Test") plot_decision_boundary(model_4, X_blob_test, y_blob_test) |
'Deep Learning & Machine Learning > 괜찮은 파이토치 강좌' 카테고리의 다른 글
| 괜찮은 파이토치 강좌 - 02. 파이토치 워크플로 살펴보기 (1) | 2024.11.24 |
|---|---|
| 괜찮은 파이토치 강좌 - 01. 파이토치 기초 (2) | 2024.11.24 |
시간날때마다 틈틈이 이것저것 해보며 블로그에 글을 남깁니다.
블로그의 문서는 종종 최신 버전으로 업데이트됩니다.
여유 시간이 날때 진행하는 거라 언제 진행될지는 알 수 없습니다.
영화,책, 생각등을 올리는 블로그도 운영하고 있습니다.
https://freewriting2024.tistory.com
제가 쓴 책도 한번 검토해보세요 ^^


그렇게 천천히 걸으면서도 그렇게 빨리 앞으로 나갈 수 있다는 건.
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!

