

Fashion MNIST 데이터셋을 학습하는 PyTorch 예제 코드를 다루고 있습니다.
아래 링크의 PyTorch의 QuickStart 문서를 기반으로 작성되었습니다.
https://pytorch.org/tutorials/beginner/basics/quickstart_tutorial.html
2022. 6. 24 최초작성
아직 PyTorch를 자주 사용하지 않아서 정리한 내용에 부족함이 있습니다.
자주 사용하게 되면 채울수 있는 내용이 많지 않을까 혼자 기대해봅니다.
2023. 5.20 최종작성
필요한 모듈을 임포트합니다.
| import torch from torch import nn from torch.utils.data import DataLoader from torchvision import datasets from torchvision.transforms import ToTensor |
torchvision.datasets 모듈에는 CIFAR, COCO와 같은 데이터셋을 포함하고 있습니다. 전체 데이터셋 리스트는 아래 링크를 참고하세요.
https://pytorch.org/vision/stable/datasets.html
본 문서에서는 Fashion MNIST 데이터셋을 사용하여 학습을 진행해봅니다.
| # Fashion MNIST의 training 데이터셋을 준비합니다. training_data = datasets.FashionMNIST( # 현재 파이썬 코드가 있는 위치에 root에 지정한 디렉토리를 생성하여 이곳에 train 데이터셋을 저장합니다. root="data", # True이면 train-images-idx3-ubyte 파일에서 데이터셋을 생성하고 False이면 t10k-images-idx3-ubyte 파일에서 데이터셋을 생성합니다. train=True, # True이면 인터넷에서 데이터셋을 다운로드하여 root에서 지정한 디렉토리에 저장합니다. 데이터셋이 이미 다운로드된 경우 다시 다운로드되지 않습니다. download=True, # 이미지를 가져와 변환할때 사용할 함수를 적습니다. transform=ToTensor(), # ToTensor() - PIL 이미지 또는 numpy.ndarray를 텐서로 변환합니다. ) # Fashion MNIST의 test 데이터셋을 준비합니다. test_data = datasets.FashionMNIST( # 현재 파이썬 코드가 있는 위치에 root에 지정한 디렉토리를 생성하여 이곳에 test 데이터셋을 저장합니다. root="data", # True이면 train-images-idx3-ubyte 파일에서 데이터셋을 생성하고 False이면 t10k-images-idx3-ubyte 파일에서 데이터셋을 생성합니다. train=False, # True이면 인터넷에서 데이터셋을 다운로드하여 root에서 지정한 디렉토리에 저장합니다. 데이터셋이 이미 다운로드된 경우 다시 다운로드되지 않습니다. download=True, # 이미지를 가져와 변환할때 사용할 함수를 적습니다. transform=ToTensor(), # ToTensor() - PIL 이미지 또는 numpy.ndarray를 텐서로 변환합니다. ) |
생성된 객체의 데이터 타입은 class 'torchvision.datasets.mnist.FashionMNIST' 입니다.
| print(type(training_data), type(test_data)) |
실행결과
<class 'torchvision.datasets.mnist.FashionMNIST'> <class 'torchvision.datasets.mnist.FashionMNIST'>
DataLoadder 객체를 생성합니다. 반복적으로 데이터셋에서 지정한 배치 크기 단위로 샘플을 가져오는 역할을 합니다.
| batch_size = 64 # 데이터 로더. 반복적으로 지정한 데이터셋에서 지정한 배치 크기 단위로 샘플을 가져옵니다. (iterable) # training 데이터셋과 test 데이터셋을 가져올 데이터 로더를 각각 생성해줍니다. train_dataloader = DataLoader(training_data, # 데이터를 로드할 데이터셋 batch_size=batch_size) # 배치 하나에 포함된 샘플의 개수 test_dataloader = DataLoader(test_data, # 데이터를 로드할 데이터셋 batch_size=batch_size) # 배치 하나에 포함된 샘플의 개수 # 파이썬의 Generator처럼 for문을 사용하여 반복될때마다 지정한 배치 단위로 샘플을 가져옵니다. 배치 크기는 64이며 샘플 하나의 shape는 (1, 28, 28)이며 타입은 텐서(class 'torch.Tensor')입니다. # X의 원소 데이터 타입은 torch.int64이고 y의 원소 데이터 타입은 torch.int64입니다. for X, y in test_dataloader: print(f"X.shape [N, C, H, W]: {X.shape} X.dtype : {X.dtype} type(X) : {type(X)}") print(f"y.shape : {y.shape} y.dtype : {y.dtype} type(y) : {type(y)}") break |
실행결과
X.shape [N, C, H, W]: torch.Size([64, 1, 28, 28]) X.dtype : torch.float32 type(X) : <class 'torch.Tensor'>
y.shape : torch.Size([64]) y.dtype : torch.int64 type(y) : <class 'torch.Tensor'>
이미지가 저장되어 있는 X의 shape가 [64, 1, 28, 28]라는 의미는 이미지 하나에 해당되는 샘플의 shape는 (1,28,28)이고 이런 샘플이 64개씩 묶여 하나의 배치라는 것을 의미합니다.
이미지가 의미하는 것을 정수로
PyTorch에서 CUDA를 사용할 수 있으면 device의 값은 cuda가 되고, 그렇지 않으면 device의 값은 cpu가 됩니다.
| # cuda를 사용할 수 있는지 체크하여 cuda 또는 cpu를 사용하도록 합니다. device = "cuda" if torch.cuda.is_available() else "cpu" print(f"Using {device} device") |
CUDA를 사용할 수 없어 device 값에 cpu가 입력되어 있는 경우입니다.
실행결과
Using cpu device
모델을 정의하고 지정한 디바이스로 보냅니다.
| # 모델을 정의합니다. # 모든 네트워크는 기본 클래스 nn.Module에서 파생됩니다. class NeuralNetwork(nn.Module): #모델을 만드는데 사용할 레이어를 정의합니다. def __init__(self): super(NeuralNetwork, self).__init__() # shape가 (1,28,28)인 샘플을 shape가 (784)인 1차원 배열로 변환합니다. self.flatten = nn.Flatten() # 레이어를 쌓아서 모델을 생성합니다. self.linear_relu_stack = nn.Sequential( # y = Wx + b 선형 변환을 위한 입력 개수(28*28)과 출력 개수(512)를 설정합니다. nn.Linear(28*28, 512), # 활성화 함수로 비선형 함수인 ReLU를 사용합니다. nn.ReLU(), # y = Wx + b 선형 변환을 위한 입력 개수(512)과 출력 개수(512)를 설정합니다. nn.Linear(512, 512), # 활성화 함수로 비선형 함수인 ReLU를 사용합니다. nn.ReLU(), # y = Wx + b 선형 변환을 위한 입력 개수(512)과 출력 개수(10)를 설정합니다. nn.Linear(512, 10) ) # 앞에서 미리 선언해놓은 레이어들을 사용하여 입력에서 출력까지 모델을 생성합니다. def forward(self, x): x = self.flatten(x) logits = self.linear_relu_stack(x) return logits # NeuralNetwork 클래스의 인스턴스를 생성하고, 모델을 지정한 device로 이동시킨 후, 모델 구조를 출력합니다. model = NeuralNetwork().to(device) print(model) |
실행결과
NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)
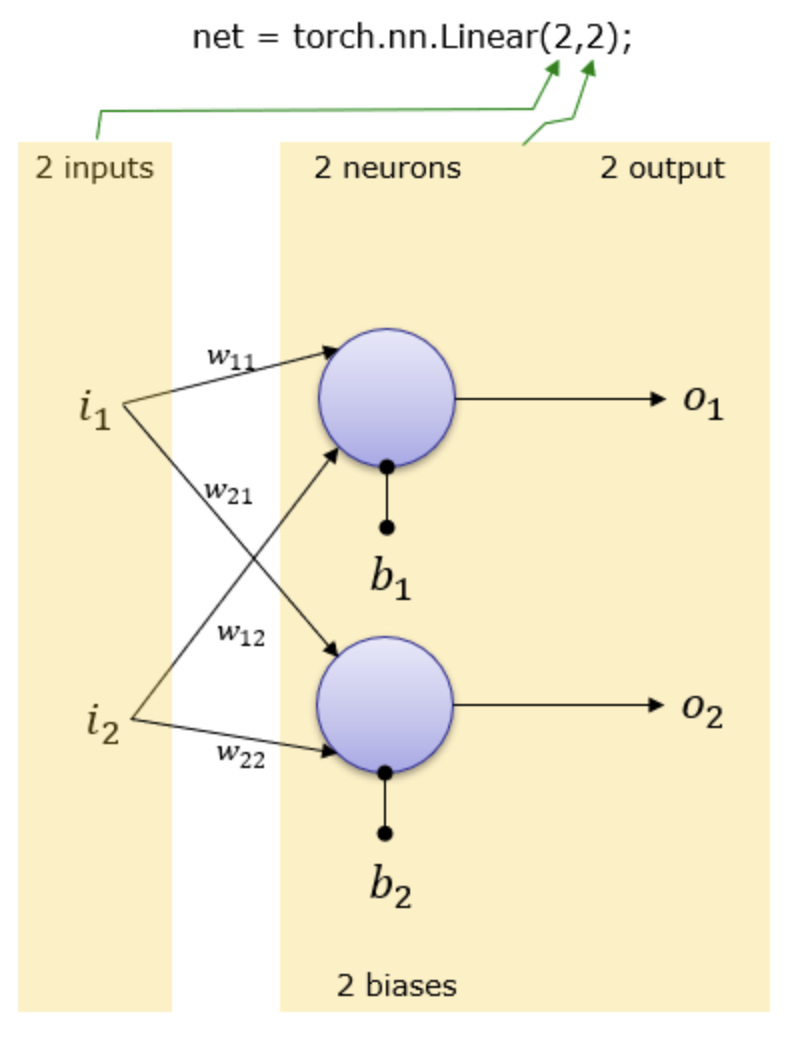
nn.Linear(n,m)
( https://www.sharetechnote.com/html/Python_PyTorch_nn_Linear_01.html )
n개의 입력과 m개의 출력을 갖는 단일 레이어(피드 포워드 네트워크)를 생성하는 모듈입니다. 수학적으로는 선형 방정식 Ax = b를 계산하도록 설게되었습니다. 선형 방정식에서 x는 입력, b는 출력, A는 가중치입니다.
nn.Linear(2,2) 모듈을 그림으로 그려보면 다음과 같습니다. 가중치(Weight)와 편향(Bias)은 자동으로 설정됩니다.
nn.Linear의 첫번째 아규먼트 2는 입력 개수가 2개 임을 나타내며
nn.Linear의 두번째 아규먼트 2는 뉴런의 개수와 출력 개수가 2개 임을 나타냅니다.
사용할 손실 함수와 옵티마이저를 준비합니다.
| # 사용할 손실 함수를 준비합니다. loss_fn = nn.CrossEntropyLoss() # 모델을 구성하는 레이어의 파라메터/가중치를 iterator로 반환한다 print(type(model.parameters())) # model.parameters()의 타입은 generator 클래스입니다. for v in model.parameters(): print(v.shape, type(v)) # 사용할 옵티마이저를 준비합니다. optimizer = torch.optim.SGD(params = model.parameters(), lr=1e-3) # params - 최적화할 매개변수의 iterable. 또는 매개변수 그룹을 정의하는 dicts # lr - learning rate |
실행결과
<class 'generator'>
torch.Size([512, 784]) <class 'torch.nn.parameter.Parameter'>
torch.Size([512]) <class 'torch.nn.parameter.Parameter'>
torch.Size([512, 512]) <class 'torch.nn.parameter.Parameter'>
torch.Size([512]) <class 'torch.nn.parameter.Parameter'>
torch.Size([10, 512]) <class 'torch.nn.parameter.Parameter'>
torch.Size([10]) <class 'torch.nn.parameter.Parameter'>
훈련 데이터셋에 대한 예측을 수행하고 예측 오류를 역전파하여 모델의 가중치를 조정합니다.
| def train(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) # 모델을 훈련(train) 모드로 설정합니다. model.train() for batch, (X, y) in enumerate(dataloader): # batch는 인덱스로 일정 간격으로 로그 출력을 하기 위해 사용됩니다. # X, y는 텐서. 지정한 device로 보냅니다. X, y = X.to(device), y.to(device) # 예측 오류를 계산합니다. # 모델을 사용하기 위해 입력 데이터를 전달합니다. 백그라운드 작업으로 모델의 forward을 실행합니다. model.forward()를 직접 호출하면 안됩니다. pred = model(X) # 손실을 계산합니다. loss = loss_fn(pred, y) # 역전파(Backpropagation) # 모든 Tensor의 그래디언트를 0으로 초기화합니다. 해주지 않으면 그레디언트가 누적되는 문제가 생깁니다. optimizer.zero_grad() # 역전파를 시작합니다. 모델을 구성하는 파라미터에 대한 손실의 gradient를 계산합니다. loss.backward() # 모델 파라미터를 업데이트합니다. optimizer.step() if batch % 100 == 0: # 100번 반복할때마다 로그 출력합니다. loss, current = loss.item(), batch * len(X) print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]") |
test 데이터 세트에 대한 모델의 성능을 확인합니다.
| def test(dataloader, model, loss_fn): size = len(dataloader.dataset) num_batches = len(dataloader) # 학습에 사용했던 dropout, batchnorm 등을 비활성화 하고 추론 모드로 바꿔줍니다. model.eval() test_loss, correct = 0, 0 # 그레디언트를 계산해주는 autograd 엔진을 비활성화시킵니다. 그 결과 메모리 사용량이 줄어들고 연산 속도가 빨라집니다. with torch.no_grad(): for X, y in dataloader: # X, y는 텐서. 지정한 device로 보냅니다. X, y = X.to(device), y.to(device) # 추론을 합니다. pred = model(X) #손실과 정답 맞춘 개수를 누적합니다. test_loss += loss_fn(pred, y).item() correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 손실은 배치 크기로 나누고, 정답 맞춘 개수는 전체 샘플 개수로 나눕니다. test_loss /= num_batches correct /= size print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n") |
학습과 성능평가를 번갈아가며 5번 반복합니다. 각 에포크 동안 모델은 가중치를 학습합니다. 각 에포크에서의 모델의 정확도와 손실을 출력한 결과를 보면 학습을 진행함에 따라 정확도가 증가하고 손실이 감소하는 것을 볼 수 있습니다.
| # 5 Epoch 반복하도록 합니다. 1 Epoch는 전체 Train 데이터셋을 학습에 한번 사용하는 것을 의미합니다. # 여기에선 5 Epoch를 사용하지만 실제론 더 많은 Epoch를 사용해야 합니다. epochs = 5 for t in range(epochs): print(f"Epoch {t+1}\n-------------------------------") # 학습 1 Epoch를 수행합니다. train(train_dataloader, model, loss_fn, optimizer) # Test 데이터셋으로 모델을 평가합니다. test(test_dataloader, model, loss_fn) print("Done!") |
실행결과
Epoch 1
-------------------------------
loss: 2.293690 [ 0/60000]
loss: 2.282755 [ 6400/60000]
loss: 2.266276 [12800/60000]
loss: 2.270950 [19200/60000]
loss: 2.230864 [25600/60000]
loss: 2.205004 [32000/60000]
loss: 2.216660 [38400/60000]
loss: 2.177848 [44800/60000]
loss: 2.187038 [51200/60000]
loss: 2.148802 [57600/60000]
Test Error:
Accuracy: 40.0%, Avg loss: 2.140368
Epoch 2
-------------------------------
loss: 2.150337 [ 0/60000]
loss: 2.142723 [ 6400/60000]
loss: 2.078261 [12800/60000]
loss: 2.105926 [19200/60000]
loss: 2.033313 [25600/60000]
loss: 1.968949 [32000/60000]
loss: 2.009539 [38400/60000]
loss: 1.922651 [44800/60000]
loss: 1.942659 [51200/60000]
loss: 1.861855 [57600/60000]
Test Error:
Accuracy: 51.2%, Avg loss: 1.859203
Epoch 3
-------------------------------
loss: 1.893565 [ 0/60000]
loss: 1.866656 [ 6400/60000]
loss: 1.740978 [12800/60000]
loss: 1.795369 [19200/60000]
loss: 1.665431 [25600/60000]
loss: 1.618827 [32000/60000]
loss: 1.651075 [38400/60000]
loss: 1.550941 [44800/60000]
loss: 1.584100 [51200/60000]
loss: 1.477529 [57600/60000]
Test Error:
Accuracy: 58.6%, Avg loss: 1.496144
Epoch 4
-------------------------------
loss: 1.563998 [ 0/60000]
loss: 1.534307 [ 6400/60000]
loss: 1.378796 [12800/60000]
loss: 1.460437 [19200/60000]
loss: 1.332959 [25600/60000]
loss: 1.329161 [32000/60000]
loss: 1.345111 [38400/60000]
loss: 1.273730 [44800/60000]
loss: 1.311046 [51200/60000]
loss: 1.212133 [57600/60000]
Test Error:
Accuracy: 62.0%, Avg loss: 1.240448
Epoch 5
-------------------------------
loss: 1.317685 [ 0/60000]
loss: 1.304294 [ 6400/60000]
loss: 1.133328 [12800/60000]
loss: 1.247648 [19200/60000]
loss: 1.121245 [25600/60000]
loss: 1.140379 [32000/60000]
loss: 1.160164 [38400/60000]
loss: 1.102852 [44800/60000]
loss: 1.143989 [51200/60000]
loss: 1.059066 [57600/60000]
Test Error:
Accuracy: 64.3%, Avg loss: 1.082479
Done!
학습이 완료된 모델을 파일로 저장했다가 다시 로드해서 사용해봅니다.
모델을 파일로 저장합니다.
| # 모델을 저장합니다. 모델을 저장했다가 로드해보기 위해서입니다. torch.save(model.state_dict(), "model.pth") print("Saved PyTorch Model State to model.pth") |
실행결과
Saved PyTorch Model State to model.pth
파일에 저장되어 있는 모델을 로드합니다.
| # 모델을 로드합니다. model = NeuralNetwork() model.load_state_dict(torch.load("model.pth")) |
실행결과
<All keys matched successfully>
로드한 모델을 예측하는데 사용합니다.
| # 클래스 이름 정의 classes = [ "T-shirt/top", "Trouser", "Pullover", "Dress", "Coat", "Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot", ] # 학습에 사용했던 dropout, batchnorm 등을 비활성화 하고 추론 모드로 바꿔줍니다. model.eval() # test 데이터셋에서 한 개의 샘플에 대한 추론을 해봅니다. for X, y in test_dataloader: print(X.shape, y.shape) # X, y 각각 64개의 샘플로 배치가 구성됩니다. # torch.Size([64, 1, 28, 28]) torch.Size([64]) # X, y는 텐서. 지정한 device로 보냅니다. X = X.to(device) y = y.to(device) # 배치에서 첫번째 샘플 선택 X = X[0] y = y[0] # 그레디언트를 계산해주는 autograd 엔진을 비활성화시킵니다. 그 결과 메모리 사용량이 줄어들고 연산 속도가 빨라집니다. with torch.no_grad(): # 예측합니다. pred = model(X) # 예측 결과 print(pred.shape) # torch.Size([1, 10]) # 예측 결과는 10개의 값으로 구성되어 있습니다. print(pred) # tensor([[-3.9056, -5.0756, -3.7454, -4.0897, -3.9336, 6.6377, -3.4197, 7.3002, 2.5242, 8.0658]]) # 10개중 가장 높은 것의 인덱스를 구합니다. 이 인덱스가 예측한 클래스입니다. print(pred.argmax(1)) # tensor([9]) print(y) # 예측한 클래스 이름과 실제 클래스 이름을 구하여 출력합니다. predicted, actual = classes[pred.argmax(1)], classes[y] print(f'Predicted: "{predicted}", Actual: "{actual}"') # Predicted: "Ankle boot", Actual: "Ankle boot" # 샘플하나만 사용하고 종료합니다. break |
test 데이터셋에서 가져온 이미지를 모델의 입력으로 넣어서 추론한 결과 정답과 똑같이 Ankle boot라고 올바르게 예측했습니다.
실행결과
torch.Size([64, 1, 28, 28]) torch.Size([64])
torch.Size([1, 10])
tensor([[-2.0715, -2.7138, -1.0020, -2.2221, -1.0372, 2.3749, -1.0614, 2.5343,
1.6493, 3.0849]])
tensor([9])
tensor(9)
Predicted: "Ankle boot", Actual: "Ankle boot"
'Deep Learning & Machine Learning > PyTorch' 카테고리의 다른 글
| 파이토치 튜토리얼 번역(quickstart) (1) | 2024.10.26 |
|---|
시간날때마다 틈틈이 이것저것 해보며 블로그에 글을 남깁니다.
블로그의 문서는 종종 최신 버전으로 업데이트됩니다.
여유 시간이 날때 진행하는 거라 언제 진행될지는 알 수 없습니다.
블로그 글과 유튜브 영상을 만드는 것은 전문가라서라기보단 공부한 내용을 함께 공유하는 게 좋아서입니다.
제가 쓴 책도 한번 검토해보세요 ^^

