

Google Cloud Speech-to-Text API 서비스 계정 키를 발급받아서 샘플 코드를 실행하는 방법을 설명합니다.
결제 신용카드를 등록해야 할 수 있습니다.
2018. 9. 21 최초작성
2020. 11. 3 최종작성
1. Cloud Speech API 키 발급 받기 2. Cloud SDK 설치 3. 파이썬 예제 테스트 해보기 4. 참고 |
1. Cloud Speech API 키 발급 받기
1. 다음 사이트에 접속하여 프로젝트를 생성 후, Cloud Speech API를 위한 API 키를 발급받아야 합니다.
https://console.cloud.google.com/apis/dashboard
2. 오른쪽 상단에 보이는 프로젝트 만들기를 선택합니다.

3. 프로젝트 이름을 적어주고 만들기를 선택합니다. 프로젝트 생성될 때까지 잠시 기다려야 합니다.

4. API 및 서비스 사용 설정을 선택합니다.

5. Cloud Speech-to-Text API를 검색하여 선택합니다.

6. 사용을 선택합니다.

7. 이제 Cloud Speech API가 활성화 되었습니다. 왼쪽 항목에서 사용자 인증 정보 만들기를 선택합니다.

8. 서비스 계정을 선택합니다.

9. 서비스 계정 만들기를 클릭합니다.

10. 적당한 서비스 계정 이름을 적고 만들기를 클릭합니다.
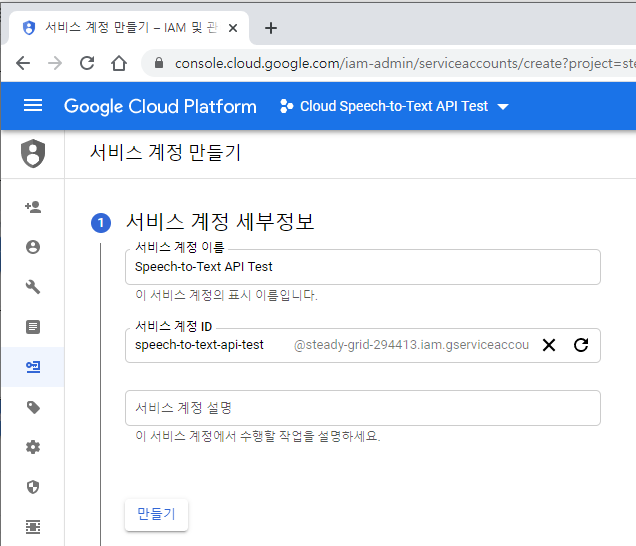
10. 적당한 서비스 계정 이름을 입력하고 역할 선택에서 Project > 소유자를 선택합니다.
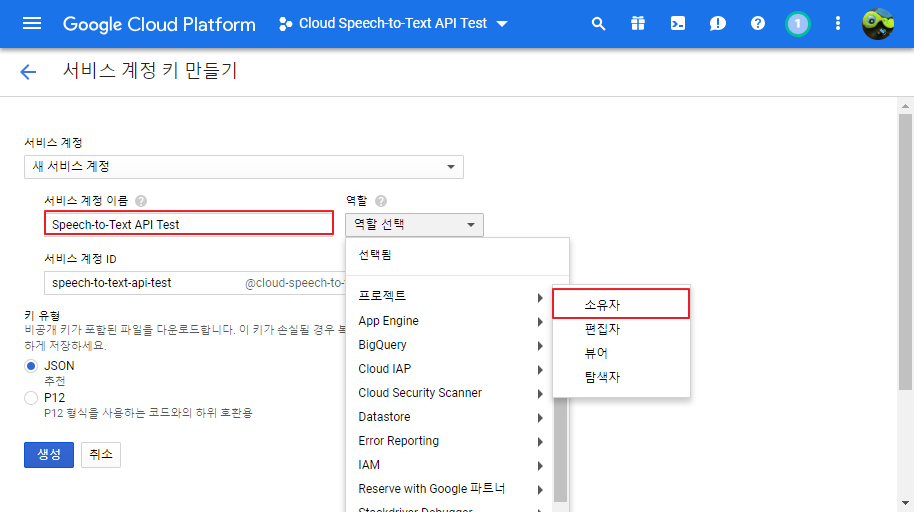
11. 역할을 클릭하고 소유자를 선택한 후, 계속을 클릭합니다.
전체 리소스에 접근이 가능하기 때문에 이후 배포를 고려할 때에는 바꿔야할지도 모르겠습니다.


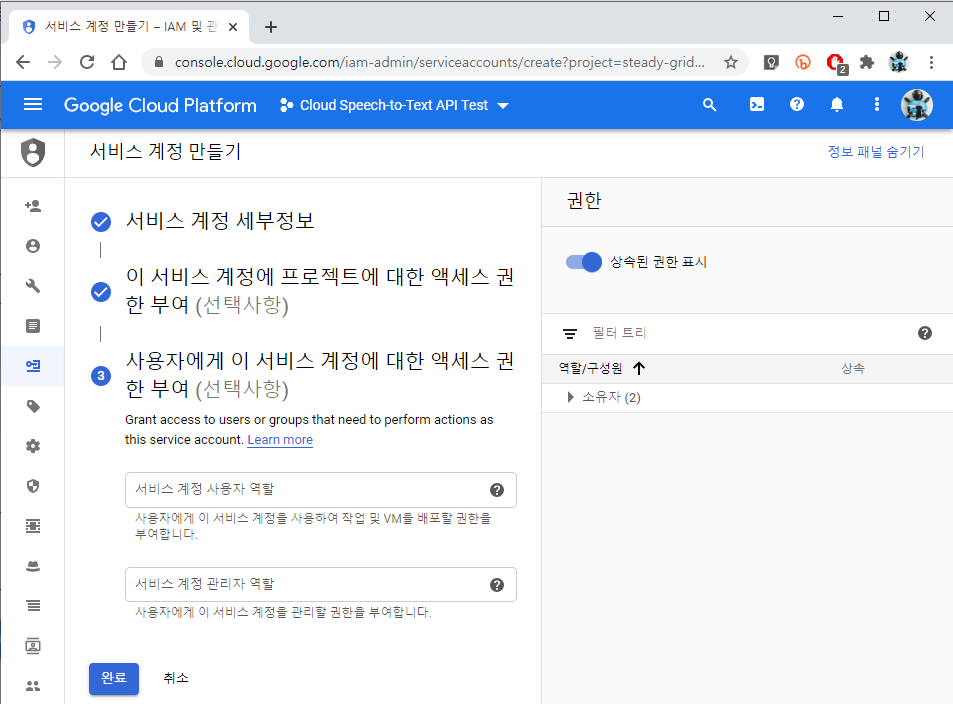
12. 완료를 클릭합니다. 여기에서 서비스에 사용할 계정을 추가하는 듯합니다.
13. 작업에 있는 점점점을 클릭한 후, 키 만들기를 선택합니다.
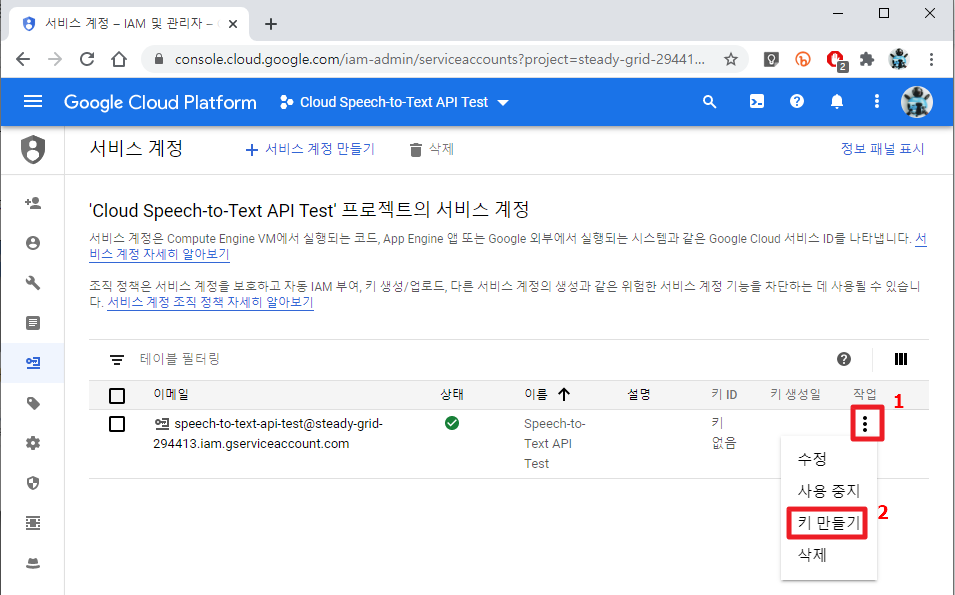
14. JSON을 선택하고 만들기를 클릭합니다.
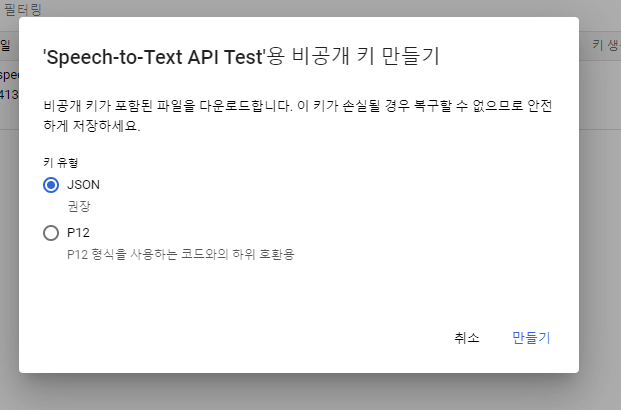
비공개 키가 컴퓨터에 저장됩니다.
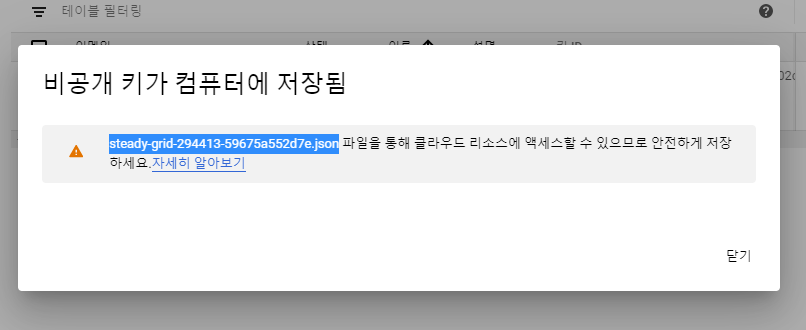
15. 윈도우의 경우 파일은 다음 위치에 다운로드 됩니다. 서비스계정키이름은 바로 위에 보이는 스크린샷에 있는 파일이름입니다.
| C:\Users\사용자이름\Downloads\서비스계정키이름.json |
명령 프롬프트에서 다음처럼 입력하여 서비스 계정 키를 위한 환경 변수를 등록합니다.
| set GOOGLE_APPLICATION_CREDENTIALS=C:\Users\사용자이름\Downloads\서비스계정키이름.json |
매번 입력하는게 번거로우면 시스템 속성의 환경 변수에 등록하면 됩니다.
이후 API 테스트시 필요하므로 반드시 등록해줘야 합니다.
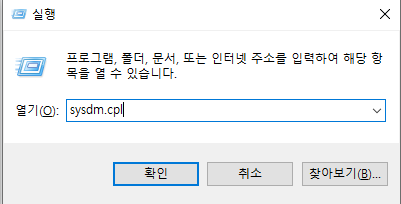
윈도우키 + R을 누른 후, sysdm.cpl를 실행합니다.
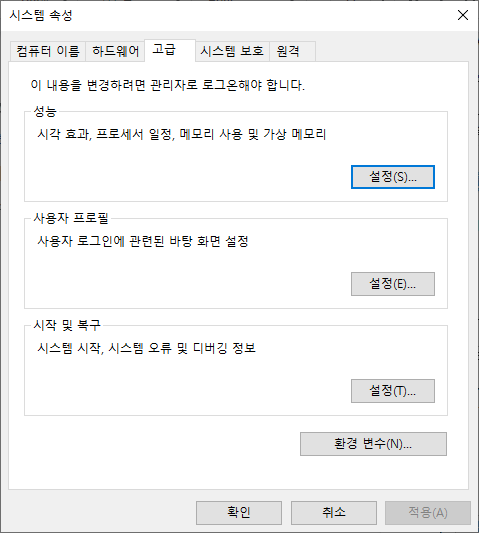
고급 탭을 선택한 후, 환경 변수 버튼을 클릭합니다.
시스템 변수에 있는 새로 만들기 버튼을 클릭합니다.
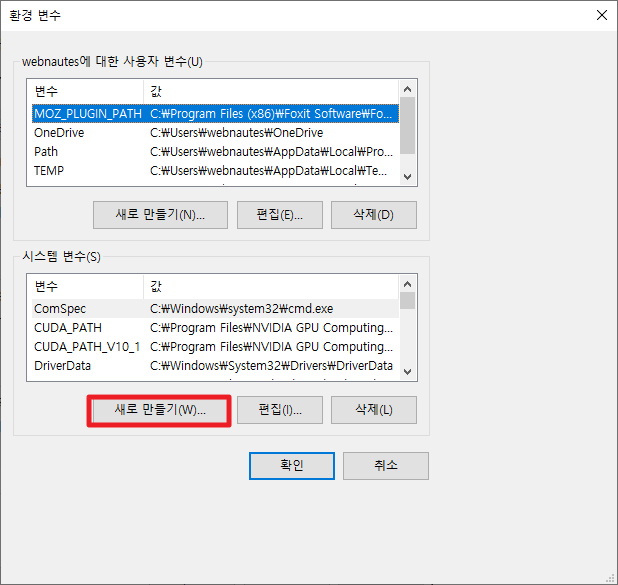
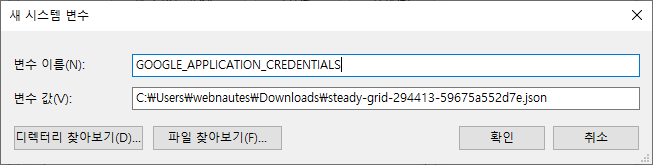
다음 처럼 값을 입력하고 확인을 클릭합니다.
변수 이름
GOOGLE_APPLICATION_CREDENTIALS
변수 값 ( 앞에서 다운로드 받은 json 파일의 위치와 이름으로 대체하세요 )
C:\Users\webnautes\Downloads\steady-grid-294413-59675a552d7e.json
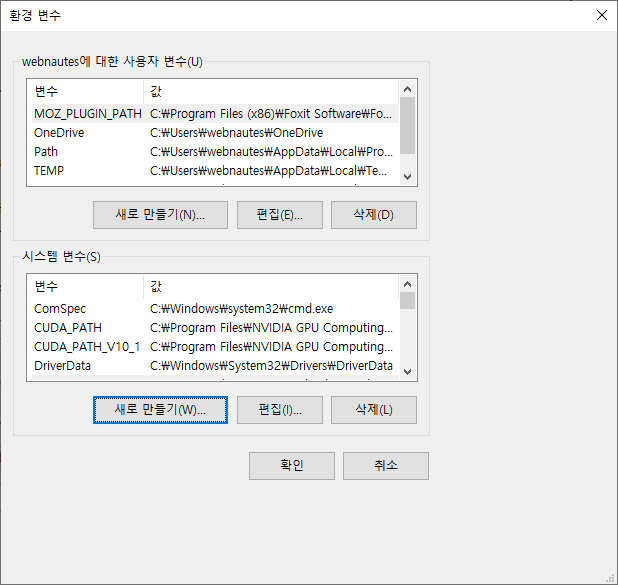
확인을 클릭합니다.
2. Cloud SDK 설치
1. 아래 링크에 접속합니다.
https://cloud.google.com/sdk/docs/downloads-versioned-archives
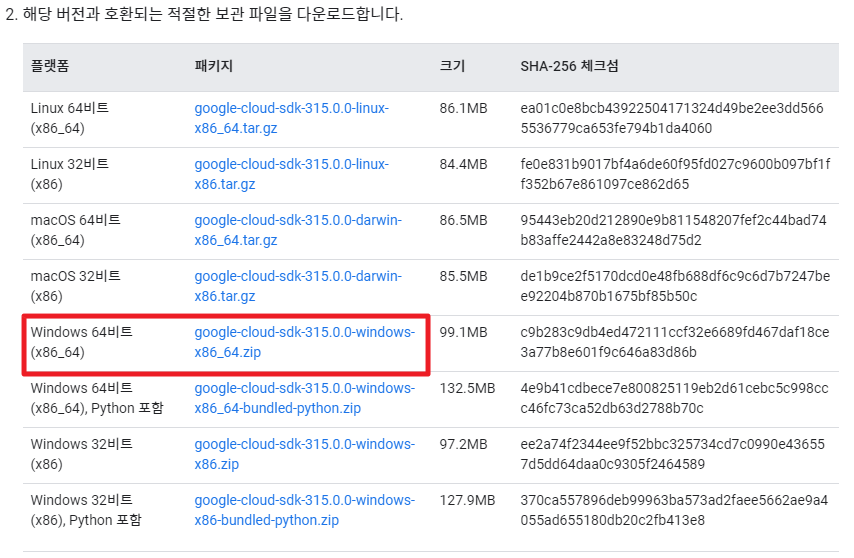
2. WINDOWS 64비트용을 다운로드합니다. Python이 설치 안되어 있는 경우에는 바로 아래에 있는 Python 포함버전을 다운로드 받습니다.
3. 시작버튼을 누른 후, 사용하는 압축 프로그램을 검색하여 관리자 권한으로 실행을 선택합니다.
압축을 푸는 과정에서 심볼릭 링크의 경우 관리자 권한이 필요하다는 메시지가 보여서 이렇게 진행했습니다.

4. 반디집을 기준으로 설명합니다. 압축 파일 열기를 선택한 후, 다운로드 받은 파일을 선택합니다.
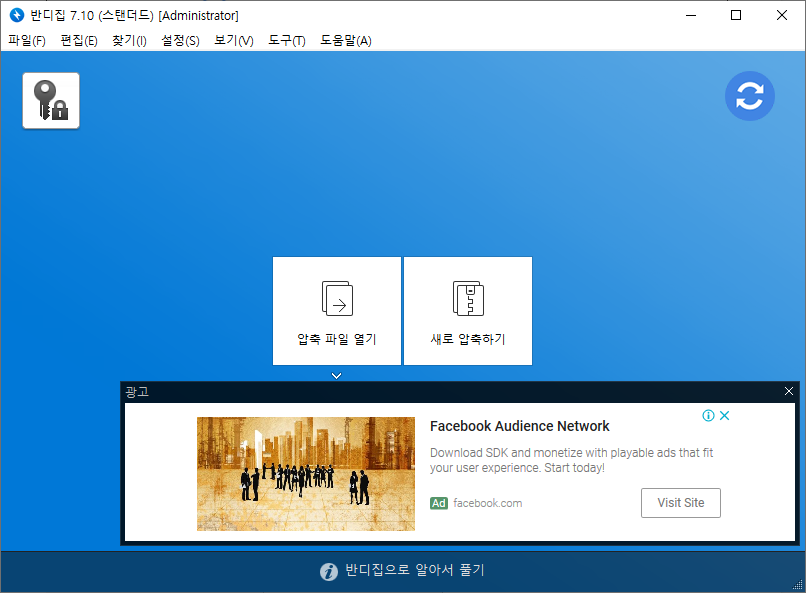
5. 풀기를 선택합니다.
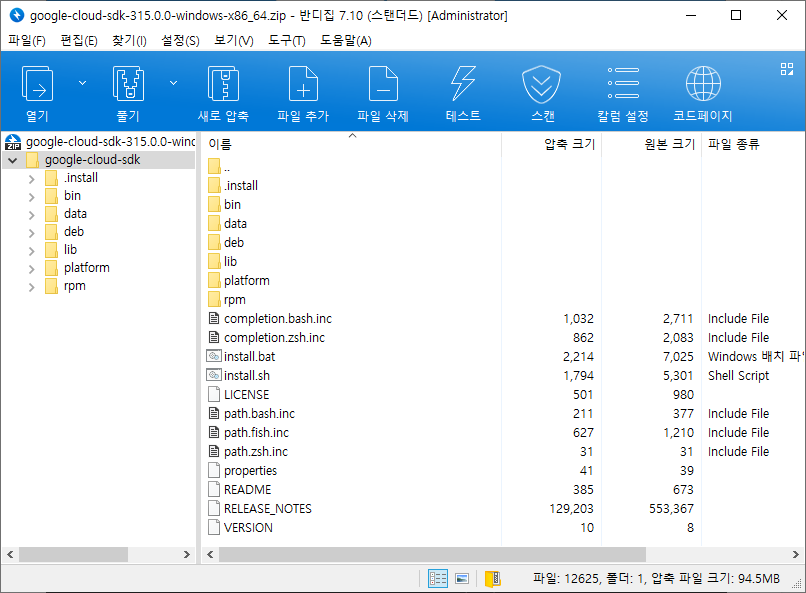
6. 로컬 디스크 (C:)를 선택하면 대상 폴더가 C:\가 됩니다. 확인을 클릭하면 압축이 풀립니다.
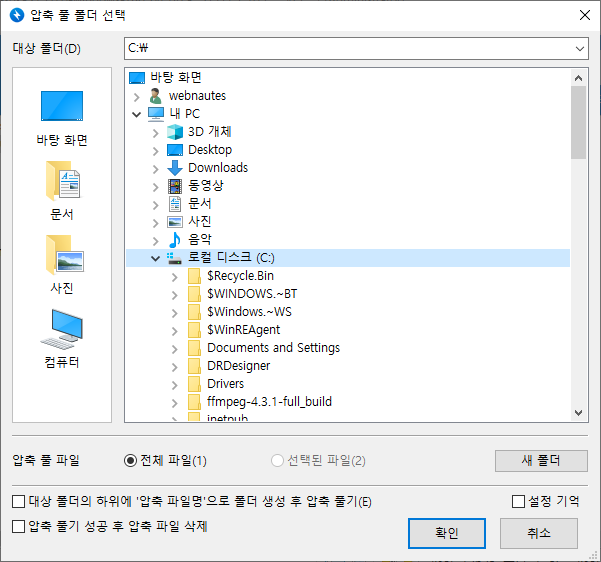
파일 하나가 다음처럼 에러가 났는데 텍스트 파일이라 무시하고 계속 진행했습니다.
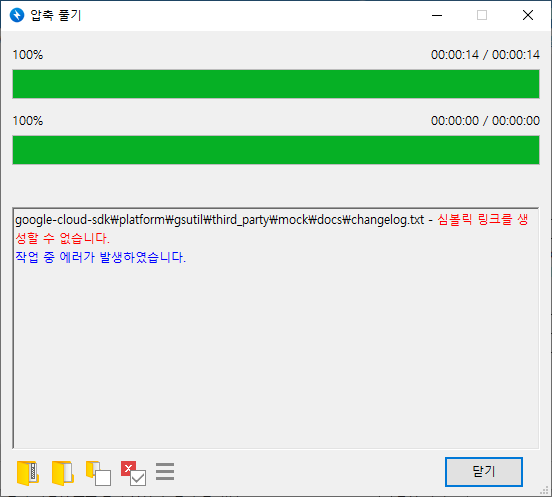
7. 다음 위치에 압축이 풀립니다.
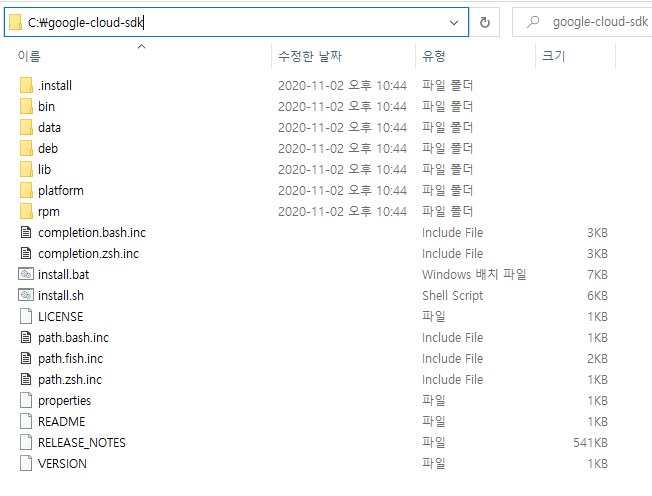
8. 윈도우 키 + R을 누른후, cmd를 실행하여 클라우드 도구를 경로를 추가하기 위해 다음 명령을 실행합니다.( 실제로 해보면 경로가 추가안됩니다 )
c:\google-cloud-sdk\install.bat
엔터키를 누릅니다.
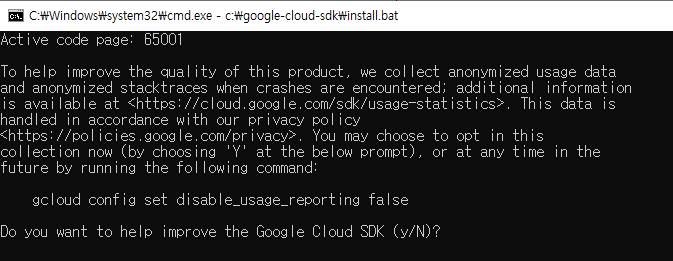
Y를 입력 후, 엔터키를 누릅니다.
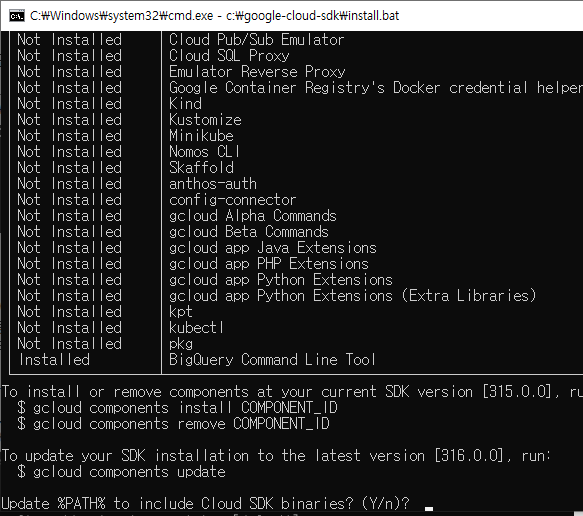
잠시 후, 다음 화면이 보입니다.
9. 명령 프롬프트에서 다음 명령을 실행합니다.
c:\google-cloud-sdk\bin\gcloud init
기존 설정을 지우려면 C:\Users\webnautes\AppData\Roaming에 있는 gcloud 폴더를 삭제하세요.
Y를 입력하고 엔터키를 누릅니다.

웹브라우저를 선택하고 확인을 클릭합니다.

10. 구글 계정을 선택합니다.

11. 허용을 선택합니다.
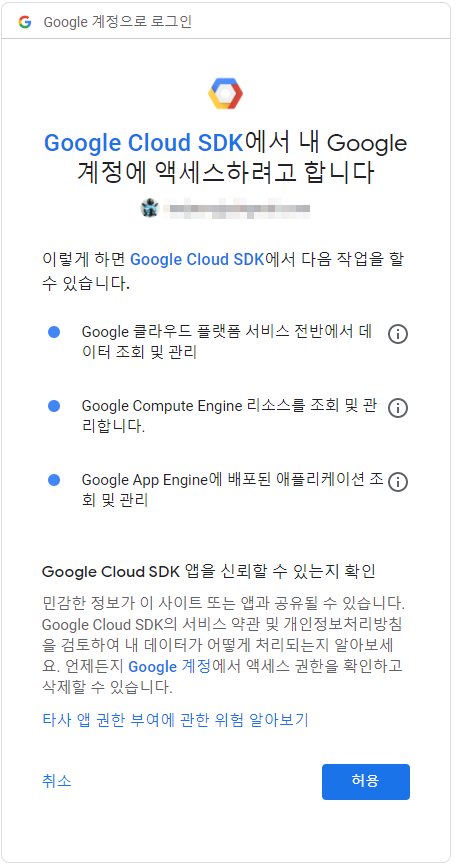
6. 다시 명령 프롬프트를 확인해보면 다음처럼 사용할 프로젝트를 선택하라고 물어봅니다.
Cloud Speech API를 위해 만든 프로젝트 번호를 입력하고 엔터키를 입력합니다.

7. 설정이 완료되었습니다.

3. 파이썬 예제 테스트 해보기
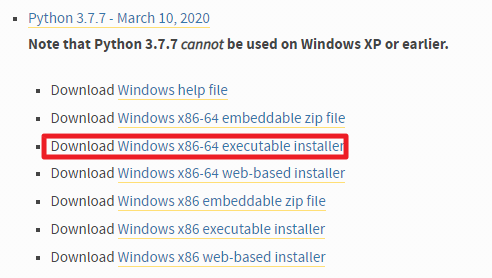
1. 파이썬 3를 설치합니다. 본 글에서는 Python 3.7.7로 진행했습니다.
https://www.python.org/downloads/windows/
2. 명령 프롬프트에서 다음처럼 virtualenv를 설치합니다.
(참고. http://timmyreilly.azurewebsites.net/python-pip-virtualenv-installation-on-windows/ )
| pip install virtualenv pip install virtualenvwrapper-win |
3. 가상환경을 위한 디렉토리를 생성하고 이동합니다.
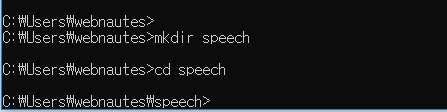
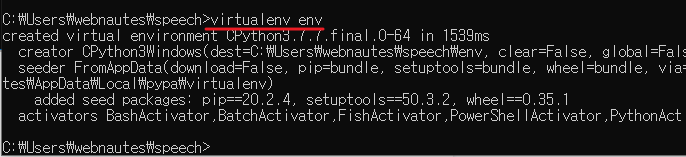
4. 다음 명령으로 가상환경을 만듭니다.
virtualenv env
5. 다음 명령으로 가상환경을 활성화 합니다.
현재 디렉토리 경로명 앞에 앞에서 지정한 이름 (env)가 붙습니다.

6. 가상환경에서 빠져나오려면 다음 명령을 사용합니다.
7. 다시 가상환경을 활성화하고 Google Cloud Client Library for Python를 설치합니다.

8. Visual Studio가 설치안되어 있다면 진행하기 전에 Visual C++ 2015 Build Tools를 아래 링크에서 다운로드 받아 설치해줘야 합니다.
http://landinghub.visualstudio.com/visual-cpp-build-tools

9. Cloud Speech API Client Library를 설치합니다.

10. 서비스 계정을 활성화합니다. 한번 해주면 이후 해줄 필요가 없습니다.
c:\google-cloud-sdk\bin\gcloud auth activate-service-account --key-file="C:\Users\webnautes\Downloads\steady-grid-294413-59675a552d7e.json"

11. 마이크 사용을 위해 필요한 패키지를 설치합니다.
https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio 에서 파이썬 버전에 맞는 파일을 다운로드합니다.
Python 3.7.7의 경우 PyAudio‑0.2.11‑cp37‑cp37m‑win_amd64.whl를 다운로드합니다.
다음처럼 다운로드 받은 파일 위치를 지정하여 설치합니다.
pip install ..\Downloads\PyAudio-0.2.11-cp37-cp37m-win_amd64.whl


12. 먼저 실시간으로 음성인식을 테스트합니다.
다음 주소에 있는 마이크를 이용한 스트림 코드를 가져와 transcribe_streaming_mic.py 이름으로 저장합니다.
크롬에서 위 링크로 이동한 후, Raw를 클릭한 후, Ctrl + S를 눌러 저장하면 됩니다.
현재 사용중인 c:\Users\사용자이름\speech 경로에 저장하세요.

코드에서 167번째 줄의 다음 부분을 인식 시킬 언어로 변경합니다.
변경시 들여쓰기가 변하지 않도록 조심하세요.
language_code = 'en-US' # a BCP-47 language tag
여기에서는 ko-KR로 변경하겠습니다.
language_code = 'ko-KR' # a BCP-47 language tag
실행하고 마이크에 말을 하면 다음 줄에 실시간으로 스크립트를 출력해줍니다.

13. 이번엔 녹음을 하여 음성파일을 생성해서 음성인식을 테스트합니다.
다음 코드를 실행하여 녹음을 하면 현재 디렉토리에 file.wav 파일이 생성됩니다.

| # https://gist.github.com/mabdrabo/8678538 import pyaudio import wave FORMAT = pyaudio.paInt16 CHANNELS = 1 #only mono RATE = 16000 CHUNK = 1024 #확인 필요 RECORD_SECONDS = 10 #10초 녹음 WAVE_OUTPUT_FILENAME = "file.wav" audio = pyaudio.PyAudio() # start Recording stream = audio.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK) print ("recording...") frames = [] for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): data = stream.read(CHUNK) frames.append(data) print ("finished recording") # stop Recording stream.stop_stream() stream.close() audio.terminate() waveFile = wave.open(WAVE_OUTPUT_FILENAME, 'wb') waveFile.setnchannels(CHANNELS) waveFile.setsampwidth(audio.get_sample_size(FORMAT)) waveFile.setframerate(RATE) waveFile.writeframes(b''.join(frames)) waveFile.close() |
다음 파이썬 코드를 실행하면 현재 디렉토리에 있는 file.wav에 대한 스크립트를 출력해줍니다.
(env) C:\Users\webnautes\speech>python quickstart.py
| #!/usr/bin/env python # Copyright 2016 Google Inc. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. def run_quickstart(): # [START speech_quickstart] import io import os # Imports the Google Cloud client library # [START speech_python_migration_imports] from google.cloud import speech # [END speech_python_migration_imports] # Instantiates a client # [START speech_python_migration_client] client = speech.SpeechClient() # [END speech_python_migration_client] # The name of the audio file to transcribe file_name = os.path.join(os.path.dirname(__file__), ".", "file.wav") # Loads the audio into memory with io.open(file_name, "rb") as audio_file: content = audio_file.read() audio = speech.RecognitionAudio(content=content) config = speech.RecognitionConfig( encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16, sample_rate_hertz=16000, language_code="ko-KR", ) # Detects speech in the audio file response = client.recognize(config=config, audio=audio) for result in response.results: print("Transcript: {}".format(result.alternatives[0].transcript)) # [END speech_quickstart] if __name__ == "__main__": run_quickstart() |
14. 추가 예제들은 아래 깃허브에 있습니다. 테스트를 해보면 좋을듯합니다.
https://github.com/googleapis/python-speech/tree/master/samples
4. 참고
https://cloud.google.com/speech/docs/quickstart?hl=ko
https://cloud.google.com/docs/authentication/getting-started?hl=ko
https://cloud.google.com/sdk/docs/quickstart-windows
https://cloud.google.com/speech/docs/reference/libraries
'Python > TTS' 카테고리의 다른 글
| meloTTS +pyQT5 테스트 (0) | 2024.11.16 |
|---|---|
| TTS 라이브러리 MeloTTS로 한국어 음성 합성해보기 (4) | 2024.11.14 |
| pyttsx를 이용하여 python에서 text to speech (2) | 2016.05.24 |
| 안드로이드 TTS 예제 프로그램 (4) | 2015.12.03 |
시간날때마다 틈틈이 이것저것 해보며 블로그에 글을 남깁니다.
블로그의 문서는 종종 최신 버전으로 업데이트됩니다.
여유 시간이 날때 진행하는 거라 언제 진행될지는 알 수 없습니다.
영화,책, 생각등을 올리는 블로그도 운영하고 있습니다.
https://freewriting2024.tistory.com
제가 쓴 책도 한번 검토해보세요 ^^


