
이미지에서 히스토그램을 구하는 방법과 응용으로 Histogram Equalization, CLAHE을 설명합니다.
다음 OpenCV Python 튜토리얼을 참고하여 강좌를 비정기적로 포스팅하고 있습니다. https://docs.opencv.org/4.0.0/d6/d00/tutorial_py_root.html |
최초작성 2018. 12. 13
1. 히스토그램이란?

히스토그램은 이미지를 구성하는 픽셀값 분포에 대한 그래프입니다. X축은 픽셀값으로 범위는 0 ~ 255 사이입니다. Y축은 이미지에서 해당 픽셀값을 가진 픽셀의 개수입니다.
히스토그램의 왼쪽에는 가장 어두운 검은색 픽셀(0)의 갯수를 보여주며 오른쪽으로 갈 수록 밝은 픽셀의 갯수를 보여줍니다.
히스토그램을 보면 이미지 촬영시 빛의 노출이 제대로 되었는지 알 수 있습니다.
어두운 이미지의 경우 히스토그램이 왼쪽에 몰려있으며

밝은 이미지의 경우 히스토그램이 오른쪽에 몰려있습니다.

보통 조명이 알맞은 이미지의 경우 히스토그램이 중앙에서 좌우로 고루 퍼져있습니다.

1.1. 히스토그램 구하기
히스토그램을 구할때 다음 3가지 파라미터를 고려해야 합니다.
픽셀 강도 범위(RANGE)
이미지에서 히스토그램을 찾을 픽셀값 범위를 결정합니다. 예를 들어 0 ~ 15으로 결정합니다.
막대 개수(DIMS)
앞에서 정한 범위내에서 계산하게될 히스토그램 막대(bin)의 개수입니다. 예를 들어 16개로 결정합니다.
막대의 범위(BINS)
하나의 막대로 보여줄 픽셀값의 의 범위입니다. 예를 들어 1입니다.
위에서 정한 파라미터를 사용하여 히스토그램을 그려보았습니다.
픽셀값 0 ~ 15 범위 내에서 해당 픽셀값을 가진 픽셀의 개수를 표로 그린 후, 오른쪽처럼 막대 그래프로 그렸습니다.


막대 개수를 4, 막대의 범위를 4로 변경하면 다음처럼 그려집니다.


OpenCV에서는 히스토그램을 구하기 위해 cv.calcHist() 함수를 제공합니다.
hist = cv.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate]]) |
images
uint8 또는 float32 타입의 이미지를 사용해야 하며 대괄호 [ ] 안에 입력해야 합니다. 예) [img]
channels
히스토그램을 계산할 채널의 인덱스입니다. 대괄호 [ ] 안에 입력해야 합니다.
예를 들어 그레이스케일 이미지라면 [0] 입니다.
컬러 이미지라면 [0], [1], [2] 중 하나를 사용할 수 있습니다. 각각 파란색, 녹색, 빨간색 채널을 의미합니다.
mask
마스크 이미지. 전체 이미지에대한 히스토그램을 구할 거라면 None을 사용해야 합니다.
이미지 일부분에 대한 히스토그램을 구하려고 한다면 마스크 이미지를 생성하여 제공해야 합니다.
histSize
계산할 히스토그램 막대(BIN)의 개수입니다. 대괄호 [ ]안에 입력해야 합니다. 전체 영역을 계산한다면 [256]입니다.
ranges
히스토그램을 계산할 범위입니다. 전체 픽셀 강도 범위를 계산 한다면 [0, 256] 입니다.
포스팅에서 사용한 코드입니다.
# 원본코드 - https://github.com/opencv/opencv/blob/master/samples/python/hist.py |
실행결과입니다.

2. Histogram Equalization
콘트라스트는 밝은 부분과 어두운 부분의 밝기 차이입니다. 사진의 선명도와 디테일한 묘사에 영향을 줍니다.
왼쪽은 콘트라스트를 점점 약하게 한 경우로 아래로 갈수록 점점 밝은 부분과 어두운 부분의 차이가 줄어들어 사진의 공간감이 떨어지고 있습니다.
오른쪽은 콘트라스트를 점점 강하게 한 경우로 아래로 갈수록 바위 부분의 디테일한 묘사가 점점 사라지고 있습니다.

이미지 출처 - https://en.wikipedia.org/wiki/Contrast_(vision)
특정 영역에 픽셀값이 집중되어 있는 이미지를 생각해봅시다.
예를 들어, 밝은 이미지는 픽셀값이 높은 쪽에 몰려있고

어두운 이미지는 픽셀값이 낮은 쪽에 몰려있습니다.

알맞은 밝기의 이미지라면 전체 영역에 필셀값이 분포해야 합니다.

알맞은 밝기의 이미지가 되려면 히스토그램이 전체 영역을 차지하도록 늘려야 합니다. 히스토그램 평활화(Histogram Equalization)라고 부릅니다. 결과적으로 이미지의 콘트라스트를 향상시킵니다.

이미지 출처 - https://en.wikipedia.org/wiki/Histogram_equalization
다음은 히스토그램 평활화를 적용하기 전 후의 결과 이미지입니다. 히스토그램 평활화를 적용한 후 히스토그램이 0 ~ 255 사이의 범위에 고루 퍼지게 되며 옆에 있는 누적 히스토그램이 직선이 됩니다.
결과 이미지를 비교해보면 콘트라스트가 향상되어 밝은 부분과 어두운 부분의 구분이 확실해졌습니다.


우선 NumPy를 사용하여 히스토그램 평활화를 구해봅니다.
이미지를 1차원 배열로 변환 후 히스토그램을 구합니다.
hist, bin = np.histogram(img.flatten(), 256, [0, 256]) |
히스토그램의 누적합을 구합니다.
cdf = hist.cumsum() |
누적합의 최대값, 최소값을 이용하여 히스토그램이 넓게 분포되도록 만들어해주는 룩업 테이블( look-up table)을 만듭니다.
cdf = np.uint8((cdf - cdf.min())*255/(cdf.max()-cdf.min())) |
룩업 테이블을 그레이스케일 이미지에 적용하여 히스토그램 평활화가 적용된 이미지를 얻습니다.
equ = cdf[gray] |
속도 개선을 위해 추가로 NumPy의 masked array를 적용합니다. 마스크를 씌운 부분만 계산에서 제외시키는 방법입니다
hist, bin = np.histogram(img.flatten(), 256, [0, 256]) |
OpenCV에서는 히스토그램 평활화를 위해서 cv.equalizeHist() 함수를 제공합니다.
입력으로 그레이스케일 이미지를 사용해야 히스토그램 평활화된 이미지를 얻을 수 있습니다.
# 다음 6줄을 1줄로 바꿀 수 있음 # hist, bin = np.histogram(img.flatten(), 256, [0, 256]) equ = cv.equalizeHist(gray) |
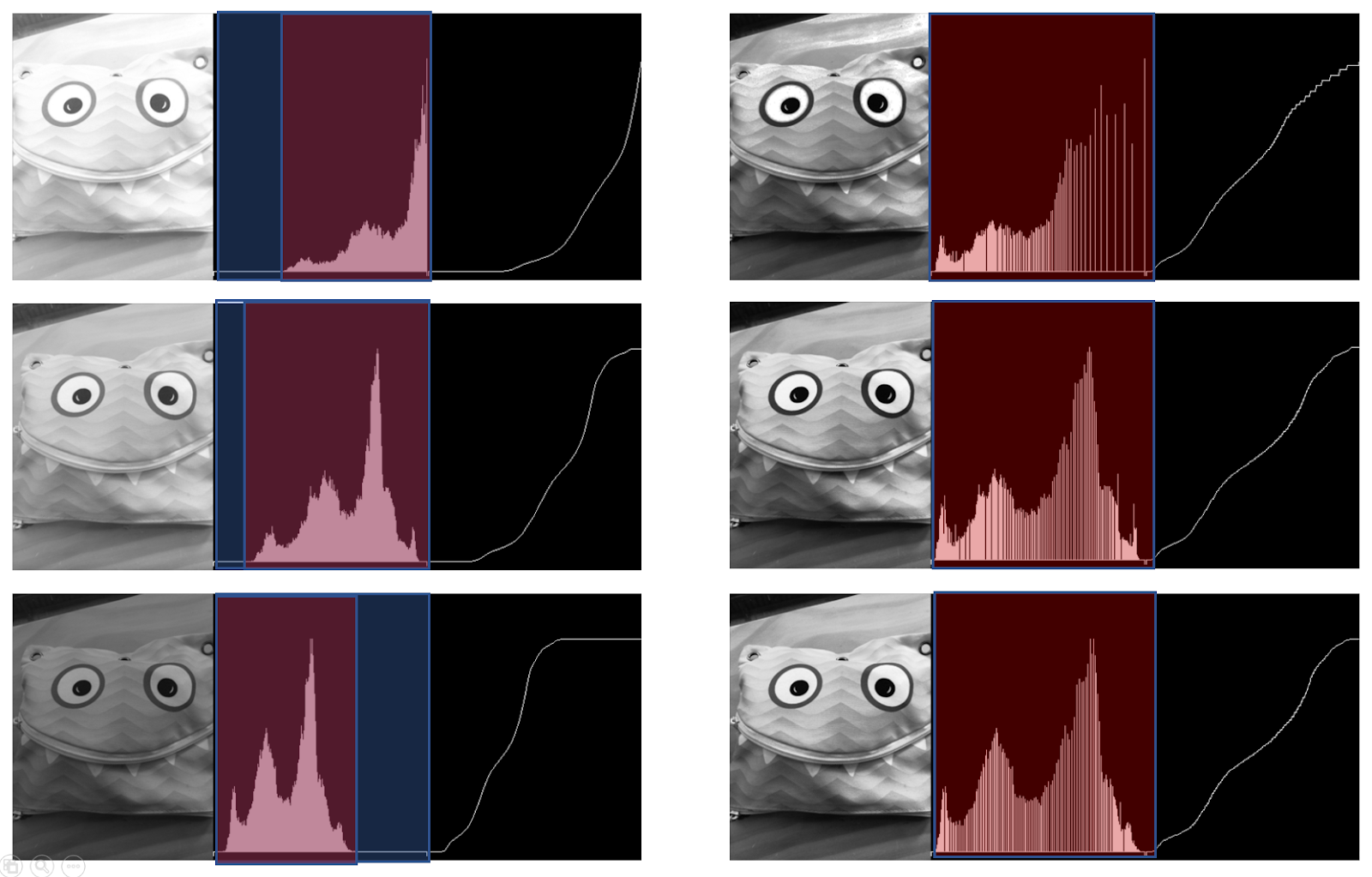
히스토그램 평활화는 많은 경우에 유용합니다.
어두운 이미지 또는 밝은 이미지에 이미지 평활화를 적용하면 이미지를 똑같은 조명상태로 만들어줍니다.
예를 들어 얼굴인식에서 얼굴 데이터를 훈련시키기 전에 같은 조명 상태로 만들기 위해 사용할 수 있습니다.
왼쪽 이미지처럼 다양한 밝기의 이미지에 히스토그램 평활화를 적용하면 오른쪽처럼 거의 같은 밝기, 대비의 이미지가 얻어집니다.
포스팅에 사용한 코드입니다.
# 원본 코드 - https://github.com/opencv/opencv/blob/master/samples/python/hist.py |
히스토그램이 특정 영역에 집중되어 있는 경우 히스토그램 평활화는 좋은 결과를 보여줍니다.
하지만 밝은 픽셀과 어두운 픽셀이 같이 존재하는 경우처럼 히스토그램이 넓은 영역에 걸쳐있어서 픽셀 강도의 변화가 큰 경우에는 좋은 결과를 보여주지 못합니다.
첫번째 이미지는 히스토그램 평활화를 적용하기 전 입니다. 어두운 부분(파란색)과 밝은 부분(석고상)이 같이 있습니다.
두번째 이미지는 히스토그램 평활화를 적용 후 입니다. 석고상의 얼굴(빨간색)이 너무 밝아져서 이목구비를 구별하기 어렵게 되었습니다. 히스토그램 평활화 결과 히스토그램이 전체 영역에 고루 분배되면서 배경이 되는 영역은 전체적으로 밝아졌지만 석고상의 경우에는 필요이상으로 히스토그램 평활화가 적용되었습니다.
히스토그램 평활화를 전역적으로 적용해서 생기는 문제입니다. 이 부분을 개선하기 위해 CLAHE (Contrast Limited Adaptive Histogram Equalization)를 사용할 수 있습니다.

2.1. CLAHE (Contrast Limited Adaptive Histogram Equalization)
앞에서 살펴본 히스토그램 평활화는 이미지의 전체에 콘트라스트를 향상시키기 때문에 밝은 부분과 어두운 부분이 같이 있는 이미지에서는 좋지 못한 결과를 보여주었습니다.


이 문제를 해결하기 위해서 적응형 히스토그램 평활화( adaptive histogram equalization )를 적용합니다.
이미지를 작은 블럭으로 나눕니다. OpenCV에서 사용하는 디폴트 블럭의 크기는 8x8 입니다. 그리고나서 히스토그램 평활화를 적용합니다. 그 결과 히스토그램이 작은 영역에 한정될 것입니다.
노이즈가 있다면 증폭되는데 이것을 방지하기 위해서 콘트라스트를 제한적으로 적용합니다.
히스토그램의 특정 막대(bin)가 미리 정한 콘트라스트 값보다 크다면(OpenCV에서는 디폴트로 40) 히스토그램 평활화를 적용하기 전에 해당 막대은 다른 히스토그램 막대에 균일하게 분배합니다.
히스토그램 평활화를 적용한 후에 블럭으로 나누었던 것의 효과를 줄이기 위해서 Bilinear Interpolation 보간법을 적용합니다.
CLAHE를 적용해보면 배경과 석고상 모두 콘트라스트가 향상된 것을 볼 수 있습니다.

포스팅에서 사용한 코드입니다.
# 원본코드 - https://github.com/opencv/opencv/blob/master/samples/python/hist.py # 수정 - webnautes import cv2 as cv |
'OpenCV > OpenCV 강좌' 카테고리의 다른 글
| 성능 좋은 얼굴 인식(Face Recognition) 라이브러리 테스트 (0) | 2018.12.23 |
|---|---|
| OpenCV Python 강좌 - 2차원 히스토그램과 Histogram Backprojection (0) | 2018.12.15 |
| OpenCV Python강좌 - 컨투어(Contour) 검출 및 특성 사용하기 (24) | 2018.11.28 |
| OpenCV 강좌 - Canny Edge Detector 이론 및 사용 예제 (6) | 2018.11.15 |
| OpenCV Python 강좌 - 마우스 클릭으로 HSV 색공간에서 특정색 추출하기 (37) | 2018.10.23 |
시간날때마다 틈틈이 이것저것 해보며 블로그에 글을 남깁니다.
블로그의 문서는 종종 최신 버전으로 업데이트됩니다.
여유 시간이 날때 진행하는 거라 언제 진행될지는 알 수 없습니다.
블로그 글과 유튜브 영상을 만드는 것은 전문가라서라기보단 공부한 내용을 함께 공유하는 게 좋아서입니다.
제가 쓴 책도 한번 검토해보세요 ^^

