
k- 최근접 이웃 알고리즘, k-Nearest Neighbour (KNN)에 대해서 설명합니다.
마지막 업데이트 2019. 2. 9
KNN은 지도학습(supervised learning)을 위해 사용할 수 있는 간단한 분류(classification) 알고리즘 중 하나입니다.
새로운 데이터가 주어질 때 기존 클래스중 어느 쪽에 속할지 결정합니다.
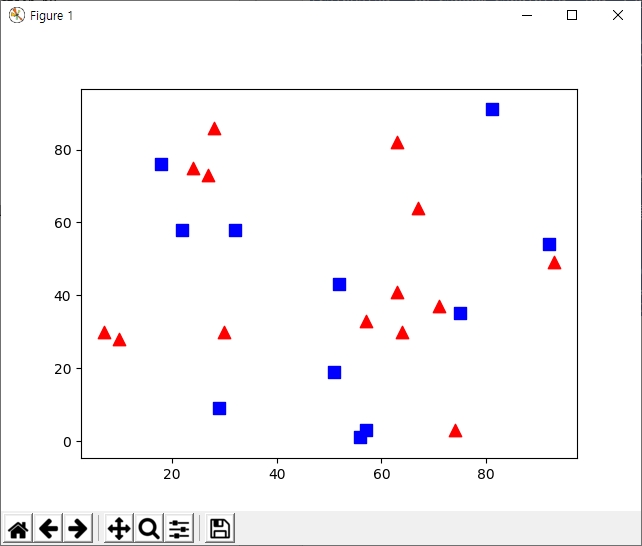
파란색 사각형과 빨간색 삼각형 두가지 클래스의 데이터가 존재할 때, 초록색 원이 추가되었습니다.
초록색 원은 파란색 사각형과 빨간색 삼각형 중 어느 쪽에 포함시켜야 할까요?

초록색 원과 거리가 가까운 이웃을 찾아서 해당 클래스에 초록색 원을 추가할 수 있습니다. 여기에서는 빨간색 삼각형 클래스입니다.
이 방법을 최근접 이웃 알고리즘(Nearest Neighbour)이라고 부릅니다. 가장 거리가 가까운 이웃으로만 판단하는 알고리즘이다.
하지만 이 방법에 문제가 있습니다. 빨간색 삼각형보다 파란색 사각형이 새로 추가된 초록색 원 주변에 더 많기 때문입니다.
작은 원 안에는 똑같은 수의 빨간색 삼각형과 파란색 사각형이 포함되어 있지만 그보다 큰 원 내부에는 파란색 사각형이 더 많습니다.
이 문제를 해결하려면 k 개의 이웃과의 거리를 체크해야 합니다.
만약 k=3, 즉 3개의 이웃과의 거리를 체크한다면 두 개의 빨간 삼각형과 하나의 파란 사각형이 이웃에 있습니다. 따라서 빨간색 삼각형 클래스에 속하게 됩니다.
k=7이라면 5개의 파란색 사각형과 2개의 빨간색 삼각형이 이웃에 있기 때문에 초록색 원은 파란색 사각형 클래스에 속하게 됩니다.
어느 쪽 클래스에 속한 데이터에 더 가까이 있느냐를 체크하는게 아니라 이웃에 어느쪽 클래스의 데이터가 더 많은지를 체크합니다.
만약 k=4라면 파란색 사각형과 빨간색 삼각형은 똑같이 두 개입니다. 똑같기 때문에 어느 쪽에 속한다 결정하기 어렵습니다. 그렇기 때문에 k는 홀수로 정하는 것이 낫습니다.
새로 추가된 데이터와 기존의 데이터 사이의 거리를 재서 가장 근접한 이웃을 찾는 방법이기 때문에 많은 메모리가 필요하고 오랜 계산 시간이 필요합니다.
이제 OpenCV로 KNN을 사용하는 방법을 설명합니다.
빨간색 삼각형 클래스를 0, 파란색 사각형 클래스를 1로 이름을 붙여 사용합니다.
import numpy as np
# 하니의 데이터당 (x,y) 좌표를 갖기 때문에 배열은 (25, 2) 크기를 갖습니다. response = np.random.randint(0, 2, (25, 1)).astype(np.float32) |
임의의 수를 발생시켜 데이터가 출력되는 좌표와 어느쪽에 속하는지 라벨을 붙였기 때문에 실행할때마다 결과가 달라진다. 사용하는 데이터의 크기는 훈련 데이터 수 X 특징 개수 이다. 여기에서는 25 x 2 크기의 float32 배열이 메모리에 올라가게 된다.
import cv2
|
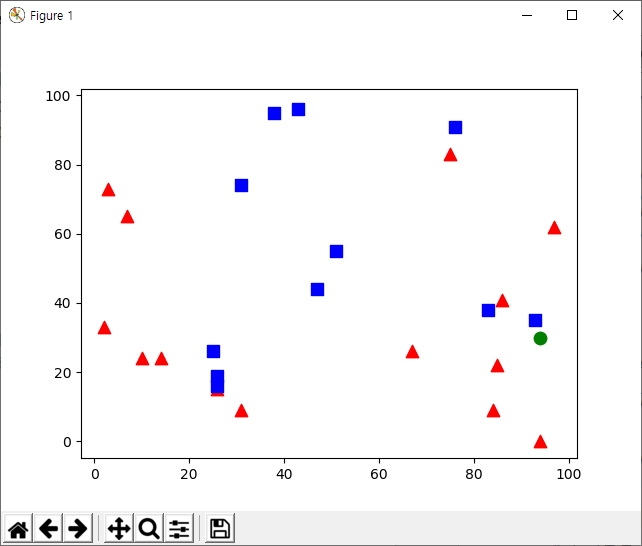
[0.] [97. 62.]
[0.] [31. 9.]
[1.] [47. 44.]
[1.] [76. 91.]
[0.] [67. 26.]
[0.] [ 3. 73.]
[1.] [83. 38.]
[1.] [31. 74.]
[0.] [85. 22.]
[0.] [ 2. 33.]
[0.] [14. 24.]
[1.] [93. 35.]
[1.] [43. 96.]
[0.] [75. 83.]
[0.] [94. 0.]
[0.] [10. 24.]
[1.] [25. 26.]
[1.] [51. 55.]
[0.] [26. 15.]
[0.] [84. 9.]
[0.] [86. 41.]
[0.] [ 7. 65.]
[1.] [26. 16.]
[1.] [38. 95.]
[1.] [26. 19.]
result: [[1.]] # 새로 추가된 데이터를 파란색 사각형으로 판정
neighbous [[1. 0. 1.]] # 이웃에 두 개의 파란색 사각형과 하나의 빨간색 삼각형이 있었음
distance [[ 26. 145. 185.]] # 각각 데이터로부터의 거리
실행해 본 결과 새로 추가된 초록색 원 주변에 두 개의 파란색 사각형과 1개의 빨간색 삼각형이 존재하기때문에 파란색 사각형 클래스에 속하는 것으로 결정되었다.
새로 추가되는 데이터의 수를 10개로 늘려보면
newdata = np.random.randint(0, 100, (10, 2)).astype(np.float32) |

새로 추가된 데이터(초록색 원)별로 이웃점을 찾아줍니다.
[1.] [75. 45.]
[0.] [31. 20.]
[0.] [42. 12.]
[1.] [91. 4.]
[0.] [72. 91.]
[0.] [ 1. 44.]
[1.] [29. 4.]
[0.] [17. 46.]
[1.] [63. 84.]
[1.] [81. 98.]
[0.] [1. 8.]
[1.] [44. 9.]
[0.] [86. 10.]
[0.] [94. 45.]
[0.] [29. 26.]
[0.] [35. 72.]
[0.] [ 4. 58.]
[0.] [34. 53.]
[0.] [81. 49.]
[1.] [56. 18.]
[1.] [48. 58.]
[1.] [60. 1.]
[0.] [95. 81.]
[1.] [79. 28.]
[1.] [99. 49.]
result: [[1.]
[1.]
[1.]
[0.]
[0.]
[0.]
[0.]
[1.]
[0.]
[1.]]
neighbous [[1. 0. 1.]
[1. 1. 1.]
[0. 1. 1.]
[0. 0. 1.]
[1. 0. 0.]
[0. 0. 1.]
[0. 0. 1.]
[1. 1. 1.]
[0. 0. 0.]
[1. 0. 1.]]
distance [[ 113. 185. 425.]
[ 205. 250. 296.]
[ 145. 260. 314.]
[ 232. 1114. 1145.]
[ 530. 706. 820.]
[ 36. 52. 272.]
[ 41. 128. 164.]
[ 82. 277. 349.]
[ 148. 234. 250.]
[ 80. 136. 185.]]
'OpenCV > OpenCV 강좌' 카테고리의 다른 글
| OpenCV SURF로 이미지 매칭 테스트 (84) | 2019.05.11 |
|---|---|
| OpenCV Python 예제 - 컨투어 내부의 색 검출하기(Detect color inside contour area) (6) | 2019.04.10 |
| OpenCV에서 바이너리 이미지를 파일로 저장하기 (18) | 2019.01.28 |
| OpenCV에서 1비트 이미지 저장하기 (6) | 2019.01.28 |
| OpenCV Python 강좌 - 10. Harris Corner Detection (4) | 2019.01.26 |
문제 발생시 지나치지 마시고 댓글 남겨주시면 가능한 빨리 답장드립니다.
도움이 되셨다면 토스아이디로 후원해주세요.
https://toss.me/momo2024
제가 쓴 책도 한번 검토해보세요 ^^

