
괜찮은 파이토치 강좌 - 02. 파이토치 워크플로 살펴보기
괜찮은 파이토치 강좌를 찾아서 나름 다시 정리해본 결과를 공유합니다.
최초작성 2024. 11. 24
다음 포스트에 이어지는 내용입니다.
괜찮은 파이토치 강좌 - 01. 파이토치 기초
https://webnautes.tistory.com/2409
다음 문서를 기반으로 작성되었습니다. 코랩에서 실행한 결과를 정리했습니다.
https://www.learnpytorch.io/01_pytorch_workflow/
1. 데이터 준비
데이터를 학습 및 테스트 세트로 분할
2. 모델 구축
파이토치 모델 구축 필수 요소
파이토치 모델의 내용 확인하기
torch.inference_mode()를 사용하여 예측하기
3. 학습 모델
파이토치에서 손실 함수 및 옵티마이저 생성하기
파이토치에서 최적화 루프 생성하기
파이토치 학습(Training) 루프
파이토치 테스트 루프
4. 학습된 PyTorch 모델로 예측하기(추론)
5. 파이토치 모델 저장 및 불러오기
전체 모델 저장하기
모델의 상태 딕셔너리(state dict) 저장하기
GPU/CPU 간 모델 이동
파이토치 모델의 state_dict() 저장하기
저장된 PyTorch 모델의 state_dict() 로드하기
6. 모든 것을 종합하기
Data
PyTorch 선형 모델 구축하기
학습하기
예측하기
모델 저장 및 불러오기
머신러닝과 딥러닝의 핵심은 신경망을 사용하여 과거의 데이터에서 패턴을 발견하고, 발견된 패턴을 사용하여 미래의 데이터를 예측하는 것입니다.
본 글에서는 파이토치로 만든 모델을 사용하여 과거의 데이터로부터 직선의 패턴을 학습하고 새로운 데이터를 예측하는 과정을 살펴봅니다.
이제 필요한 모듈을 임포트합니다.
torch, torch.nn(nn은 신경망(neural network)을 의미하며 이 패키지에는 파이토치에서 신경망을 생성하기 위한 빌딩 블록이 포함되어 있습니다) 및 matplotlib을 가져올 것입니다.
| import torch from torch import nn # import matplotlib.pyplot as plt # Check PyTorch version torch.__version__ |
2.5.1+cu121
1. 데이터 준비
머신러닝/딥러닝에서는 데이터를 숫자로 바꾸어 모델의 입력으로 사용합니다.
본 글에선 직선 패턴을 갖는 좌표 데이터를 가상으로 만들어 사용합니다.
미리 정해놓은 파라미터인 weight는 0.7, bias는 0.3을 선형 회귀식 y = weight * X + bias 에 대입하여 입력 X와 입력 X에 대응하는 출력 y로 구성된 데이터를 생성한 다음 파이토치로 만든 모델을 사용해 X와 y의 관계를 학습하여 파라미터 weight와 bias를 추정하는 모델을 만들어 봅니다.
| # 파라미터를 미리 정해놓습니다. 보통은 파라미터를 미리 알 수 없습니다. weight = 0.7 bias = 0.3 # 데이터를 생성합니다. 0에서 1사이 범위내에서 간격 0.02로 X값을 생성합니다. start = 0 end = 1 step = 0.02 X = torch.arange(start, end, step).unsqueeze(dim=1) # 주어진 X값들에 대한 y값을 계산합니다. y = weight * X + bias # 10개의 데이터만 출력하면 텐서 데이터타입으로 출력됩니다. X[:10], y[:10] |
(tensor([[0.0000],
[0.0200],
[0.0400],
[0.0600],
[0.0800],
[0.1000],
[0.1200],
[0.1400],
[0.1600],
[0.1800]]),
tensor([[0.3000],
[0.3140],
[0.3280],
[0.3420],
[0.3560],
[0.3700],
[0.3840],
[0.3980],
[0.4120],
[0.4260]]))
데이터를 학습 및 테스트 세트로 분할
데이터가 준비되었으면 이제 데이터를 분할해야 합니다. 각 데이터 세트별로 다음과 같은 목적이 있습니다.
Train set
모델은 Train 데이터 세트를 통해 학습합니다.(학기중 수업자료). 전체 데이터 크기의 60~80%을 사용합니다. 항상 필요한 데이터 세트입니다.
Validation set
모델은 Validation 데이터 세트를 기반으로 조정됩니다(기말고사 전에 치르는 모의고사). 전체 데이터 크기의 10~20%를 사용합니다. 선택사항인 데이터 세트입니다.
Test set
모델은 Test 데이터 세트를 사용하여 학습한 내용을 평가합니다(학기 말에 치르는 기말고사). 전체 데이터 크기의 10~20%를 사용합니다. 항상 필요한 데이터 세트입니다.
본 글에서는 Train 데이터 세트와 Test 데이터 세트만 사용합니다.
앞에서 준비한 텐서 데이터 타입의 X와 y를 분할하여 Train 데이터 세트와 Test 데이터 세트를 만들 수 있습니다.
Test 데이터 세트를 Train 데이터 세트나 Validation 데이터 세트 용도로 사용하면 안됩니다. 학습에 사용하지 않은 Test 데이터 세트를 사용하여 학습된 모델이 얼마나 잘 일반화되는지 파악하게 됩니다. 즉 학습에 사용한 데이터 세트에서만 잘 동작하는 모델이 아닌지 확인합니다.
| # train/test 데이터 세트를 분리합니다. 전체 데이터의 80%는 Train 데이터 세트로 사용하고 나머지 20%는 Test 데이터 세트로 사용합니다. train_split = int(0.8 * len(X)) X_train, y_train = X[:train_split], y[:train_split] X_test, y_test = X[train_split:], y[train_split:] len(X_train), len(y_train), len(X_test), len(y_test) |
(40, 40, 10, 10)
Train 데이터 세트 샘플 40개(X_train & y_train)와 Test 데이터 세트 샘플 10개(X_test & y_test)가 준비되었습니다.
X_train과 y_train 사이의 관계를 학습한 모델을 X_test와 y_test를 사용하여 평가합니다.
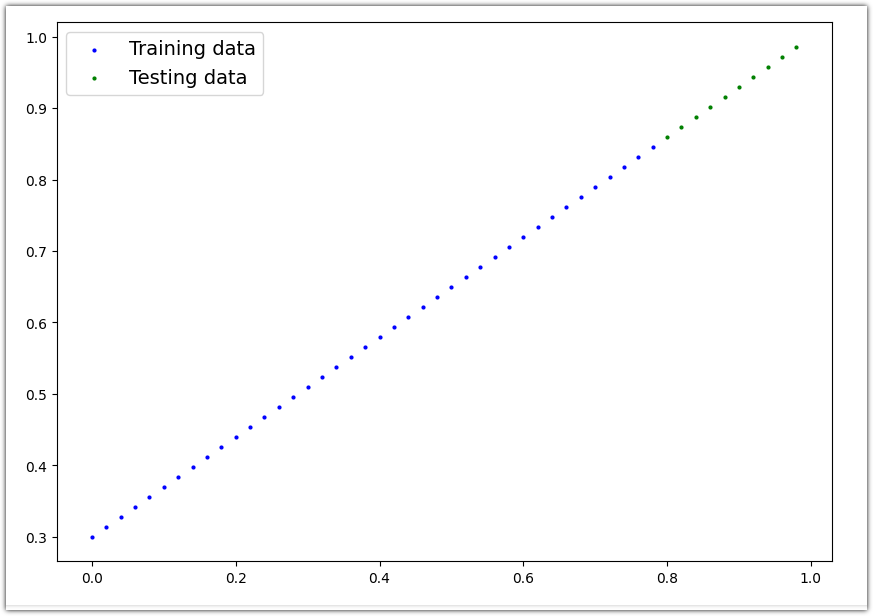
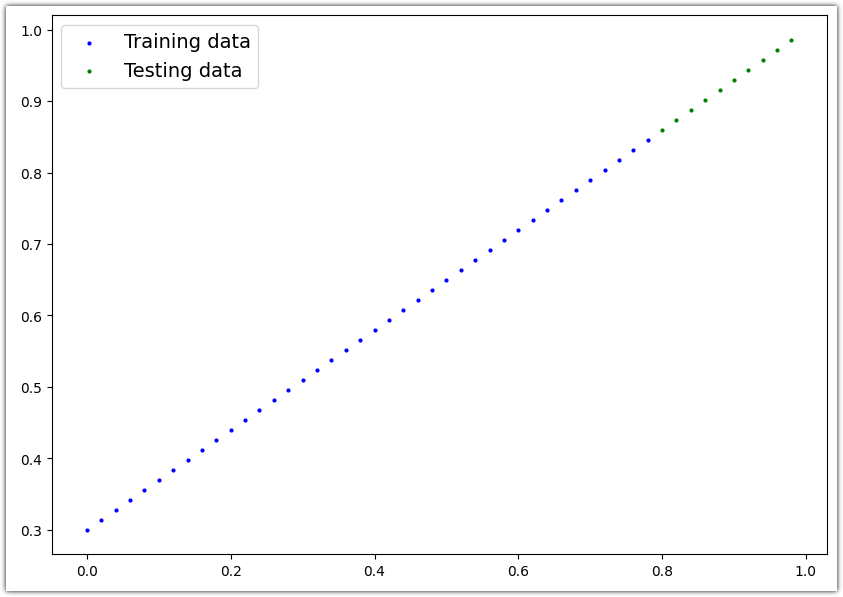
데이터를 그래프로 그려보면 아래 코드의 실행 결과처럼 데이터가 직선으로 그려지는 것을 볼 수 있습니다.
Train 데이터 세트는 파란색 점으로 표현되며 Test 데이터 세트는 녹색 점으로 표현됩니다.
| def plot_predictions(train_data=X_train, train_labels=y_train, test_data=X_test, test_labels=y_test, predictions=None): """ Plots training data, test data and compares predictions. """ plt.figure(figsize=(10, 7)) # Plot training data in blue plt.scatter(train_data, train_labels, c="b", s=4, label="Training data") # Plot test data in green plt.scatter(test_data, test_labels, c="g", s=4, label="Testing data") if predictions is not None: # Plot the predictions in red (predictions were made on the test data) plt.scatter(test_data, predictions, c="r", s=4, label="Predictions") # Show the legend plt.legend(prop={"size": 14}); |
| plot_predictions(); |
2. 모델 구축
이제 데이터를 확보했으니 파란색 점(Train 데이터 세트)을 모델의 입력으로 사용하여 파란점의 직선 패턴을 모델이 학습하도록 합니다. 주어진 Train 데이터 세트의 X값을 모델에 입력하여 추론된 y값이 실제 Train 데이터 세트의 y값과 일치하도록 모델이 학습됩니다.
Test 데이터 세트의 X값을 학습된 모델에 전달하여 예측한 y의 값이 Test 데이터 세트의 y값과 일치하도록 하는 것이 목표입니다. 즉 예측된 모델의 값이 녹색점과 일치해야 합니다.
파이토치를 사용하여 선형 회귀 모델을 작성해봅니다.
| # 선형 회귀(Linear Regression) 모델 클래스 class LinearRegressionModel(nn.Module): # 파이토치의 대부분의 모델은 nn.Module을 상속받습니다. # 모델에서 사용할 컴포넌트를 정의합니다. def __init__(self): super().__init__() self.weights = nn.Parameter(torch.randn(1, # 무작위 가중치 weights로 초기화합니다. (모델이 학습하면서 이 가중치를 조정합니다.) dtype=torch.float), # 데이터 타입은 float32입니다. requires_grad=True) # 경사 하강법(gradient descent)으로 가중치 값을 업데이트합니다. self.bias = nn.Parameter(torch.randn(1, # 무작위 바이어스 bias로 초기화합니다. (모델이 학습하면서 이 바이어스를 조정합니다.) dtype=torch.float), # 데이터 타입은 float32입니다. requires_grad=True) # 경사 하강법(gradient descent)으로 가중치 값을 업데이트합니다. # forward 함수는 모델에서 계산해야 하는 것을 정의합니다. # y = weights * X + bias def forward(self, x: torch.Tensor) -> torch.Tensor: # x는 모델에 제공되는 입력 데이터입니다. return self.weights * x + self.bias # 선형회귀(linear regression formula) 공식입니다. y = m * x + b |
파이토치 모델 구축 필수 요소
torch.nn
torch.nn은 딥러닝 모델을 만드는데 필요한 모든 기본 구성 요소(층, 활성화 함수, 손실 함수 등)를 제공하는 핵심 모듈입니다. 신경망을 쌓는데 필요한 레고 블록과 같은 역할을 하며, Linear, Conv2d, ReLU 등의 다양한 층과 함수들을 포함하고 있습니다.
torch.nn.Parameter
torch.nn.Parameter는 모델이 학습을 통해 자동으로 업데이트해야 하는 가중치(weight)나 편향(bias) 같은 학습 가능한 파라미터를 저장하고 관리하는 특별한 텐서입니다. 이 파라미터들은 자동으로 모델의 parameters() 목록에 포함되어 학습 과정에서 기울기가 계산되고 최적화됩니다.
torch.nn.Module
torch.nn.Module은 모든 신경망 모델의 기본이 되는 클래스로, 모델의 구조와 파라미터를 관리하고 GPU 이동, 학습/평가 모드 전환 등의 기본 기능을 제공합니다. 쉽게 말해, 딥러닝 모델을 만들 때 반드시 상속받아야 하는 기본 설계도와 같은 역할을 합니다.
torch.optim
torch.optim은 모델의 가중치(파라미터)를 학습 과정에서 어떻게 업데이트할지를 결정하는 다양한 옵티마이저(최적화 알고리즘)을 제공합니다. 손실(error)을 최소화하기 위해 SGD, Adam과 같은 옵티마이저 알고리즘을 통해 모델의 가중치를 자동으로 조정해주는 역할을 합니다.
torch.utils.data.Dataset
커스텀 데이터셋을 만들기 위한 추상 클래스입니다.
Dataset은 데이터를 어떤 형식으로 준비하고 불러올지 정의하는 클래스입니다. 데이터의 전체 개수(len)와 특정 위치의 데이터를 어떻게 가져올지(getitem)를 지정하여 DataLoader가 효율적으로 데이터를 로드할 수 있게 해줍니다.
torch.utils.data.DataLoader
DataLoader는 Dataset에서 정의된 데이터를 실제 학습에 사용할 수 있도록 미니배치로 묶어주고, 데이터를 섞거나 여러 프로세스를 사용해 빠르게 불러오는 기능을 제공합니다.
forward 메서드
forward() 메서드는 모델에 입력된 데이터가 어떤 순서와 방식으로 처리되어 결과가 나올지를 정의하는 핵심적인 함수입니다. 쉽게 말해, 데이터가 모델의 각 층을 통과하면서 어떻게 변환될지를 지정하는 설계도와 같은 역할을 합니다.
파이토치 모델의 내용 확인하기
이제 만든 클래스로 모델 인스턴스를 생성하고 .parameters()를 사용하여 매개변수를 확인해 보겠습니다.
| # nn.Parameter가 무작위로 초기화되므로 수동 시드를 설정합니다. torch.manual_seed(42) # 앞에서 정의한 모델의 인스턴스를 생성합니다 model_0 = LinearRegressionModel() # 생성한 LinearRegressionModel 모델 내에 정의된 파라미터를 출력하여 확인해봅니다. list(model_0.parameters()) |
[Parameter containing:
tensor([0.3367], requires_grad=True),
Parameter containing:
tensor([0.1288], requires_grad=True)]
모델의 .state_dict()를 출력하여 모델의 상태(모델에 포함된 파라미터)를 확인할 수 있습니다.
| model_0.state_dict() |
OrderedDict([('weights', tensor([0.3367])), ('bias', tensor([0.1288]))])
model_0.state_dict()의 값을 출력해보면 weights와 bias 값은 무작위 값입니다. 앞에서 파라미터 생성시 torch.randn()을 사용하여 무작위값으로 초기화했기 때문입니다.
무작위 파라미터에서 시작하여 데이터를 잘 설명할 수 있는 최적 파라미터(직선 데이터를 생성할 때 설정한 하드코딩된 weight 및 bias 값)를 찾도록 모델을 학습시켜야 합니다.
초기 모델은 무작위 값으로 시작하기 때문에 지금은 주어진 X에 대한 예측값 y가 정확하지 않습니다.
torch.inference_mode()를 사용하여 예측하기
아직 학습을 하지 않았지만 새로 만든 모델이 Test 데이터 세트를 얼마나 잘 예측하는지 확인해봅니다.
입력 특징 X_test를 모델에 전달하여 입력 레이블 y_test를 얼마나 가깝게 예측하는지 확인해봅니다.
모델에 데이터를 전달하면 모델의 forward() 메서드에서 우리가 정의한 선형회귀 계산식을 사용하여 결과를 생성합니다.
예측을 해보겠습니다.
예측을 하기 위해 torch.inference_mode()를 다음처럼 컨텍스트 관리자로 사용한 것을 보셨을 것입니다.
with torch.inference_mode():
torch.inference_mode()는 추론을 위해 모델을 사용할 때 사용되며 forward 메소드에 데이터를 통과시키는 포워드 패스가 더 빠르게 동작하도록 만들기 위해 학습에는 필요하지만 추론에는 필요하지 않은 기울기 추적, 메모리 캐싱, 중간 결과값 저장과 같은 여러 가지 기능을 비활성화합니다. 이를 통해 추론 속도를 향상시키고 메모리 사용량을 줄일 수 있습니다.
예측한 결과를 출력해봅니다.
| # Check the predictions print(f"Number of testing samples: {len(X_test)}") print(f"Number of predictions made: {len(y_preds)}") print(f"Predicted values:\n{y_preds}") |
Number of testing samples: 10
Number of predictions made: 10
Predicted values:
tensor([[0.3982],
[0.4049],
[0.4116],
[0.4184],
[0.4251],
[0.4318],
[0.4386],
[0.4453],
[0.4520],
[0.4588]])
Test 데이터 세트의 X값 하나당 하나의 예측값이 출력됩니다. 모델을 사용하여 예측하려고 하는 것이 주어진 X값에 대한 직선상의 y의 값이기 때문입니다.
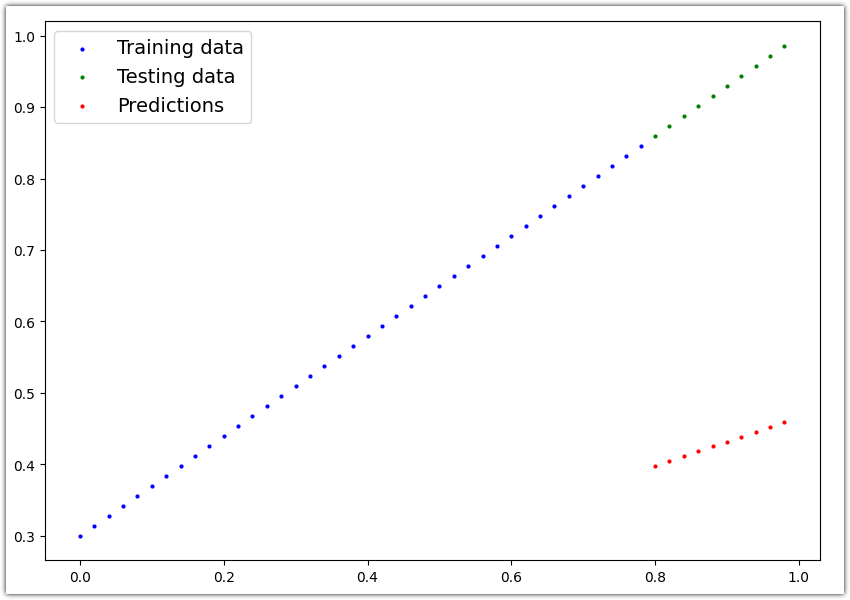
앞에서 숫자로 출력된 예측값을 시각해보겠겠습니다.
| plot_predictions(predictions=y_preds) |
| y_test - y_preds |
tensor([[0.4618],
[0.4691],
[0.4764],
[0.4836],
[0.4909],
[0.4982],
[0.5054],
[0.5127],
[0.5200],
[0.5272]])
빨간점으로 모델이 예측한 점이 표현되었습니다. 현재 모델은 무작위 파라미터 값을 사용하여 예측을 하기 때문에 결과가 좋지 않습니다. 모델의 성능이 좋아지려면 빨간점이 초록색 점위치가 되어야 합니다.
아직 결과가 좋지 않은 것은 파란색점(Train 데이터 세트)를 사용하여 학습을 하지 않았기 때문입니다.
3. 학습 모델
아직은 모델이 무작위 파라미터를 사용하여 예측을 하고 있기 때문에 결과가 좋지 않습니다.
이 문제를 해결하려면 내부 파라미터, nn.Parameter()로 정의한 weight, bias가 Train 데이터 세트의 특성(직선 패턴)을 학습하여 Train 데이터 세트의 특성을 설명할 수 있도록 weight와 bais가 조정되어야 합니다.
여기에선 모델을 위한 최적 파라미터 정답이 weight=0.7과 bias=0.3이라는 것은 알고 있지만 대부분의 경우 모델을 위한 최적 파라미터가 무엇인지 알 수 없습니다. 만든 모델이 최적 파라미터를 스스로 알아낼 수 있도록 해야합니다.
파이토치에서 손실 함수 및 옵티마이저 생성하기
모델이 자체적으로 최적 파라미터를 찾으려면 손실 함수와 옵티마이저가 필요합니다.
손실 함수는 모델의 예측(y_preds)이 실제 레이블(y_test)과 비교하여 얼마나 틀렸는지를 측정합니다. 이 손실값이 낮을수록 모델의 에측이 좋습니다.
파이토치에는 torch.nn에 다양한 손실 함수가 내장되어 있습니다. 예를 들어 회귀 문제에 사용하는 평균 절대 오차(MAE, torch.nn.L1Loss()), 이진 분류 문제에 사용하는 이진 교차 엔트로피(torch.nn.BCELoss())가 있습니다.
옵티마이저(Optimizer)는 손실을 낮추기 위해 모델의 내부 파라미터를 업데이트하는 방법을 결정합니다. 예를 들어 확률적 경사 하강(torch.optim.SGD()), 아담 옵티마이저(torch.optim.Adam())가 있습니다.
어떤 종류의 문제를 다루고 있는지에 따라 어떤 손실 함수와 옵티마이저를 사용할지는 달라집니다.
직선 패턴을 예측하는 이번 문제의 경우에는 입력으로 주어지는 숫자를 사용하여 출력되는 숫자를 예측하는 것이므로 MAE(torch.nn.L1Loss())를 손실 함수로 사용하겠습니다.
옵티마이저로는 SGD - torch.optim.SGD(params, lr)를 사용합니다:
여기서 params는 최적화하려는 대상 모델 파라미터입니다(앞에서 임의로 설정한 weights 및 bias 값)
lr은 옵티마이저가 파라미터를 업데이트할 학습률로, 학습률이 높으면 옵티마이저가 큰 업데이트를 시도하며(업데이트가 너무 크면 옵티마이저가 작동하지 않을 수 있음), 학습률이 낮으면 작은 업데이트를 시도합니다.(너무 작으면 옵티마이저가 이상적인 값을 찾는 데 너무 오래 걸릴 수 있음).
학습률은 머신 러닝 엔지니어가 설정하기 때문에 하이퍼파라미터로 간주됩니다. 학습 속도의 일반적인 시작 값은 0.01, 0.001, 0.0001이지만 학습이 진행됨에 따라 학습률을 조정할 수 있는 학습 속도 스케줄링도 있습니다.
| # MAE 손실 함수 loss_fn = nn.L1Loss() # SGD 옵티마이저 optimizer = torch.optim.SGD(params=model_0.parameters(), # 최적화할 모델의 파라미터 lr=0.01) # 학습률(learning rate) |
파이토치에서 최적화 루프 생성하기
손실 함수와 옵티마이저를 골랐으니 이제 학습 루프와 테스트 루프를 만들 차례입니다.
학습 루프는 모델이 Train 데이터 세트를 통해 특징(X)과 레이블(y) 사이의 관계를 학습하는 과정을 포함합니다.
테스트 루프는 테스트 데이터 세트를 모델의 입력으로 사용하여 모델이 학습 데이터 세트에서 학습한 파라미터(=패턴)값이 얼마나 좋은지 평가합니다. 모델은 학습 중에 테스트 데이터 세트를 사용하지 않습니다.
모델이 각 데이터 세트의 각 샘플을 반복적으로 살펴보기 때문에 각각을 “루프”라고 부릅니다.
루프를 생성하기 위해 for를 사용합니다.
파이토치 학습(Training) 루프
학습 루프는 다음 5 단계로 구성됩니다.
1. Forward pass
입력 데이터를 모델에 제공하여 예측값을 생성합니다.
모델은 모든 학습 데이터를 한 번씩 검토하여 forward() 함수 계산을 수행합니다.
y_pred = model(x_train)
2. 손실(loss) 계산
모델의 출력인 예측값 실제 데이터값(ground truth)과 비교하여 얼마나 차이가 나는지 평가합니다. 차이인 손실이 적을수록 예측이 정확함을 의미합니다.
loss = loss_fn(y_pred, y_train)
3. 그레디언트 초기화(Zero gradients)
기존에 계산된 그래디언트를 초기화하여 이전 단계의 그래디언트가 현재 계산에 영향을 주지 않도록 합니다. 파이토치는 기본적으로 그래디언트를 누적하므로 매 단계마다 초기화가 필요합니다.
optimizer.zero_grad()
4. Backpropagation (역전파)
손실에 대한 그래디언트를 계산하여 역전파합니다.
손실값을 기준으로 각 파라미터가 손실에 기여한 정도(그래디언트) 계산
계산된 그래디언트는 각 파라미터에 저장
학습이 필요한 파라미터(requires_grad=True)에 대해서만 계산
loss.backward()
5. Parameter 업데이트 - 경사하강법(gradient descent)
계산된 그래디언트를 사용하여 모델의 파라미터를 업데이트합니다.
학습률(learning rate)에 따라 파라미터 조정 크기 결정
최적화 알고리즘(SGD, Adam 등)에 따라 구체적인 업데이트 방식 결정
optimizer.step()
위 과정을 여러 번 반복하면서 모델은 점진적으로 더 나은 예측을 할 수 있도록 학습됩니다.
위는 단계의 순서나 방법은 한 예일 뿐입니다. 파이토치 학습 루프를 유연하게 만들 수도 있습니다.
파이토치 테스트 루프
모델을 평가하기 위한 테스트 루프는 다음 3단계로 구성됩니다.
1. 순전파(Forward pass)
테스트 데이터를 모델에 통과시키는 단계입니다. 모델에 입력하면 예측값이 나옵니다
모델은 모든 테스트 데이터를 한 번씩 검토하여 forward() 함수 계산을 수행합니다.
y_pred = model(x_test)
2. 손실을 계산
모델의 예측값과 실제 정답을 비교해서 얼마나 틀렸는지 계산합니다
loss = loss_fn(y_pred, y_test)
3. 평가 지표 계산 (선택사항)
정확도 같은 추가적인 평가 지표를 계산할 수 있습니다
테스트 루프에는 역전파(loss.backward())나 옵티마이저를 사용한 가중치 업데이트가 (optimizer.step()) 포함되어 있지 않은 것은 테스트 중에 모델의 파라미터가 변경되지 않고 학습된 파라미터를 그대로 사용하기 때문입니다.
테스트 루프는 단순히 모델의 현재 성능을 측정하는 것이 목적입니다
이렇게 테스트를 통해 학습된 모델이 새로운 데이터에 대해 얼마나 잘 예측하는지 확인할 수 있습니다.
위의 모든 사항을 종합하여 100개의 에포크(데이터를 순방향으로 통과)에 대해 모델을 훈련하고 10개의 에포크마다 평가해 보겠습니다.
| torch.manual_seed(42) # 에포크 수, 1 에포크는 Train 데이터 세트를 한번 다 보는걸 의미합니다. epochs = 100 train_loss_values = [] test_loss_values = [] epoch_count = [] for epoch in range(epochs): ### 학습 루프 # Train 모드로 설정합니다. model_0.train() # 1. 모델 내에 있는 forward 메소드를 사용하여 Train 데이터에 대한 Forward pass를 진행하여 추론 결과를 얻습니다. y_pred = model_0(X_train) # print(y_pred) # 2. 손실을 계산합니다. 손실은 모델의 예측과 Train 데이터의 y값의 차이입니다. loss = loss_fn(y_pred, y_train) # 3. 그레디언트를 초기화합니다. optimizer.zero_grad() # 4. 역전파를 수행합니다. loss.backward() # 5. 모델의 파라미터를 업데이트합니다. optimizer.step() ### 테스트 루프 # 평가 모드로 설정합니다. model_0.eval() # 추론에 필요없는 기능을 끄도록 추론 모드 컨텍스트 관리자를 사용합니다. with torch.inference_mode(): # 1. 모델 내에 있는 forward 메소드를 사용하여 Test 데이터에 대한 Forward pass를 진행하여 추론 결과를 얻습니다. test_pred = model_0(X_test) # 2. 손실을 계산합니다. 손실은 모델의 예측과 Test 데이터의 y값의 차이입니다. test_loss = loss_fn(test_pred, y_test.type(torch.float)) # 10 에포크 마다 loss 로그를 출력합니다. if epoch % 10 == 0: epoch_count.append(epoch) train_loss_values.append(loss.detach().numpy()) test_loss_values.append(test_loss.detach().numpy()) print(f"Epoch: {epoch} | MAE Train Loss: {loss} | MAE Test Loss: {test_loss} ") |
Epoch: 0 | MAE Train Loss: 0.31288138031959534 | MAE Test Loss: 0.48106518387794495
Epoch: 10 | MAE Train Loss: 0.1976713240146637 | MAE Test Loss: 0.3463551998138428
Epoch: 20 | MAE Train Loss: 0.08908725529909134 | MAE Test Loss: 0.21729660034179688
Epoch: 30 | MAE Train Loss: 0.053148526698350906 | MAE Test Loss: 0.14464017748832703
Epoch: 40 | MAE Train Loss: 0.04543796554207802 | MAE Test Loss: 0.11360953003168106
Epoch: 50 | MAE Train Loss: 0.04167863354086876 | MAE Test Loss: 0.09919948130846024
Epoch: 60 | MAE Train Loss: 0.03818932920694351 | MAE Test Loss: 0.08886633068323135
Epoch: 70 | MAE Train Loss: 0.03476089984178543 | MAE Test Loss: 0.0805937647819519
Epoch: 80 | MAE Train Loss: 0.03132382780313492 | MAE Test Loss: 0.07232122868299484
Epoch: 90 | MAE Train Loss: 0.02788739837706089 | MAE Test Loss: 0.06473556160926819
위 로그를 보면 에포크마다 손실이 줄어들고 있습니다.
그래프를 그려서 확인해봅니다.
| plt.plot(epoch_count, train_loss_values, label="Train loss") plt.plot(epoch_count, test_loss_values, label="Test loss") plt.title("Training and test loss curves") plt.ylabel("Loss") plt.xlabel("Epochs") plt.legend(); |
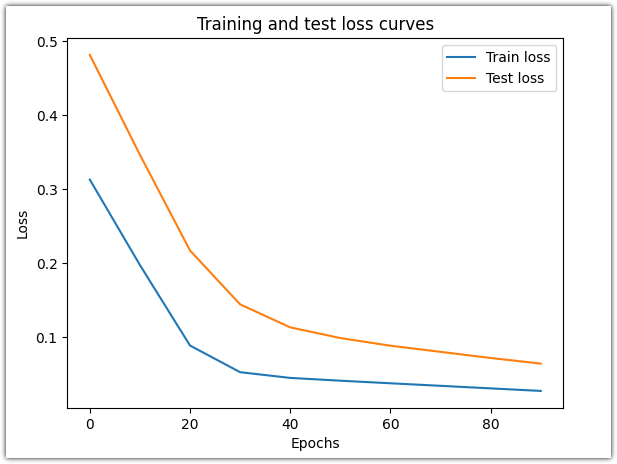
손실 곡선은 시간이 지남에 따라 손실이 감소하는 것을 보여줍니다. 손실은 모델이 얼마나 오류를 범했는지를 나타내는 척도이므로 낮을수록 좋습니다.
손실이 감소한 것은 손실 함수와 옵티마이저 덕분에 모델의 내부 파라미터(weight, bias)가 Train 데이터 세트의 패턴을 더 잘 반영하도록 업데이트되었기 때문입니다.
모델의 '.state_dict()`를 출력하여 모델이 추정한 weights, bias 값이 원래 데이터 만들때 정한 값에 얼마나 근접했는지 확인해 보겠습니다.
| # Find our model's learned parameters print("The model learned the following values for weights and bias:") print(model_0.state_dict()) print("\nAnd the original values for weights and bias are:") print(f"weights: {weight}, bias: {bias}") |
The model learned the following values for weights and bias:
OrderedDict([('weights', tensor([0.5784])), ('bias', tensor([0.3513]))])
And the original values for weights and bias are:
weights: 0.7, bias: 0.3
모델이 추정한 weights와 bias 값이 원래 값과 똑같지는 않지만 가까워졌습니다
4. 학습된 PyTorch 모델로 예측하기(추론)
모델을 학습시킨 후에 모델을 사용하여 예측할때 다음 단계로 이루어집니다.
모델을 평가 모드로 설정합니다(model.eval()).
필요없는 기능을 끄도록 하는 추론 모드 컨텍스트 관리자를 사용하여 예측을 수행합니다(with torch.inference_mode(): ...).
데이터와 모델이 둘다 GPU 또는 CPU에 있도록 해야 합니다.
| # 1. 모델을 평가 모드로 설정합니다. model_0.eval() # 2. 추론에 필요없는 기능을 끄도록 추론 모드 컨텍스트 관리자를 사용합니다. with torch.inference_mode(): # 모델과 데이터가 같은 장치에 있도록 보통 다음과 같은 방법을 사용합니다. device의 값은 코드 초반에 결정하도록 코드가 작성됩니다. # model_0.to(device) # X_test = X_test.to(device) # 테스트 데이터 세트에 대해 추론을 진행합니다. y_preds = model_0(X_test) y_preds |
tensor([[0.8141],
[0.8256],
[0.8372],
[0.8488],
[0.8603],
[0.8719],
[0.8835],
[0.8950],
[0.9066],
[0.9182]])
추론 결과를 그래프로 그려봅니다.
plot_predictions(predictions=y_preds)
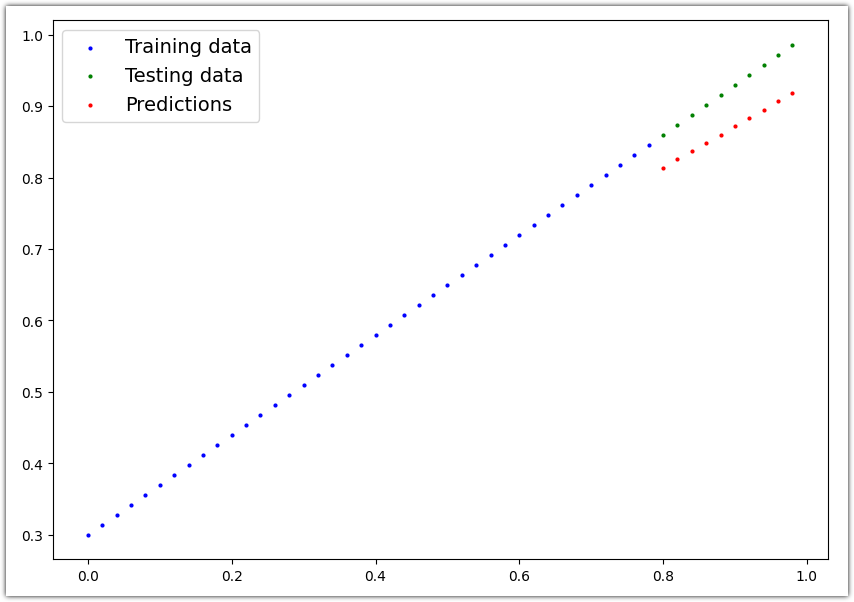
모델을 사용하여 예측한 빨간 점들이 학습에 사용한 파란점에 이전보다 훨씬 가까워졌습니다. 처음 해볼땐 무작위 값으로 파라미터가 설정된 모델을 사용했었기 때문에 결과가 너무 안좋았지만 지금은 Train 데이터 세트를 사용하여 모델의 파라미터를 학습한 이후라 결과가 좋아졌습니다.
5. 파이토치 모델 저장 및 불러오기
학습이 완료된 모델을 파일로 저장하고 나중에 다시 불러와 사용할 수 있습니다. 파이토치에서는 보통 다음 두 가지 방식으로 모델을 저장하고 로드할 수 있습니다:
전체 모델 저장하기
전체 모델 구조와 파라미터를 모두 저장합니다. 하지만 모델 클래스의 구조가 코드에 정의되어 있어야 하며, 직렬화 방식에 의존하기 때문에 유연성이 떨어질 수 있습니다.
| # 모델 저장하기 torch.save(model, 'model.pth') # 모델 불러오기 model = torch.load('model.pth') model.eval() # 평가 모드로 설정 |
전체 모델 저장 방식에는 제한사항이 있습니다.
모델을 불러올 때 원본 모델과 동일한 클래스 정의가 필요합니다
전체 모델 저장에 사용되는 Python의 pickle을 사용한 직렬화는 다음과 같은 문제가 있습니다:
코드 변경에 취약: 클래스 구조가 조금만 바뀌어도 로딩 실패
버전 의존성: Python 버전이나 PyTorch 버전이 다르면 호환성 문제 발생
플랫폼 의존성: 다른 운영체제나 환경에서 로딩할 때 문제 발생 가능
전체 모델 저장은 불필요한 정보도 함께 저장되어 파일 크기가 큽니다.
모델 구조를 수정하거나 일부만 재사용하기 어렵습니다.
다른 딥러닝 프레임워크와의 호환성이 떨어집니다.
모델의 상태 딕셔너리(state dict) 저장하기
모델의 파라미터만 저장합니다.
| # 모델의 상태 딕셔너리 저장하기 torch.save(model.state_dict(), 'model_state_dict.pth') # 모델 구조 정의 후 상태 딕셔너리 불러오기 model = YourModelClass() model.load_state_dict(torch.load('model_state_dict.pth')) model.eval() # 평가 모드로 설정 |
GPU/CPU 간 모델 이동
다른 디바이스에서 학습된 모델을 불러올 때는 다음과 같이 처리할 수 있습니다:
| # GPU에서 학습된 모델을 CPU로 불러오기 model = torch.load('model.pth', map_location=torch.device('cpu')) # CPU에서 학습된 모델을 GPU로 불러오기 model = torch.load('model.pth', map_location=torch.device('cuda')) |
주의사항
pickle 모듈은 안전하지 않으므로, 신뢰할 수 있는 출처의 모델만 불러와야 합니다.
PyTorch 버전이 다르면 호환성 문제가 발생할 수 있습니다.
state_dict를 불러올 때는 정확히 같은 모델 구조가 정의되어 있어야 합니다.
모델을 불러온 후에는 model.eval()을 호출하여 평가 모드로 설정하는 것이 좋습니다.
파이토치 모델의 state_dict() 저장하기
추론을 위해 모델을 저장하고 로드하는 데 권장되는 방법은 모델의 state_dict()를 저장하고 로드하는 것입니다.
몇 가지 단계를 통해 이를 수행하는 방법을 살펴보겠습니다:
- Python의 pathlib 모듈을 사용하여 models라는 모델을 저장할 디렉터리를 만듭니다.
- 모델을 저장할 파일 경로를 생성합니다.
- 여기서 obj는 대상 모델의 state_dict(), f는 모델을 저장할 위치의 파일명인 torch.save(obj, f)를 호출합니다.
파이토치 저장 모델이나 오브젝트는 saved_model_01.pth와 같이 .pt 또는 .pth로 끝나는 것이 일반적인 관례입니다.
| from pathlib import Path # 1. 모델이 저장될 폴더를 생성합니다. MODEL_PATH = Path("models") MODEL_PATH.mkdir(parents=True, exist_ok=True) # 2. 모델이 저장될 경로를 생성합니다. MODEL_NAME = "01_pytorch_workflow_model_0.pth" MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME # 3. 모델을 저장합니다. print(f"Saving model to: {MODEL_SAVE_PATH}") torch.save(obj=model_0.state_dict(), # only saving the state_dict() only saves the models learned parameters f=MODEL_SAVE_PATH) |
Saving model to: models/01_pytorch_workflow_model_0.pth
| # Check the saved file path !ls -l models/01_pytorch_workflow_model_0.pth |
-rw-r--r-- 1 root root 1680 Nov 20 08:10 models/01_pytorch_workflow_model_0.pth
저장된 PyTorch 모델의 state_dict() 로드하기
이제 models/01_pytorch_workflow_model_0.pth에 저장된 모델 state_dict()가 있으므로 이제 torch.nn.Module.load_state_dict(torch.load(f))를 사용하여 로드할 수 있으며 여기서 f는 저장된 모델 state_dict()의 파일 경로를 의미합니다.
torch.nn.Module.load_state_dict() 안에서 torch.load()를 호출하는 이유는 전체 모델이 아닌 학습된 파라미터의 사전인 모델의 state_dict()만 저장했기 때문에 먼저 torch.load()로 state_dict()를 로드한 다음 그 state_dict()를 모델의 새 인스턴스(nn.Module의 서브클래스)에 전달해야 하기 때문입니다.
이제 torch.nn.Module의 서브클래스이므로 load_state_dict() 메서드가 내장된 LinearRegressionModel()의 다른 인스턴스를 생성하여 테스트해 보겠습니다.
| # 모델의 인스턴스를 생성합니다. loaded_model_0 = LinearRegressionModel() # 모델에 state_dict를 로드합니다. loaded_model_0.load_state_dict(torch.load(f=MODEL_SAVE_PATH)) |
:5: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
loaded_model_0.load_state_dict(torch.load(f=MODEL_SAVE_PATH))
<All keys matched successfully>
이제 로드된 모델을 테스트하기 위해 테스트 데이터에 대해 추론을 수행해 보겠습니다.
모델을 평가 모드로 설정합니다(model.eval()).
추론 모드 컨텍스트 관리자를 사용하여 예측을 수행합니다(with torch.inference_mode(): ...).
모든 예측은 동일한 디바이스의 오브젝트로 수행해야 합니다(예: 데이터와 모델만 GPU에 있거나 데이터와 모델만 CPU에 있는 경우).
| # 1. 모델을 평가모드로 설정합니다. loaded_model_0.eval() # 2. 추론에 필요없는 기능을 끄도록 추론 모드 컨텍스트 관리자를 사용합니다. with torch.inference_mode(): # 추론을 수행합니다. loaded_model_preds = loaded_model_0(X_test) |
이제 로드된 모델로 예측한 결과가 모델 저장전의 예측과 동일한지 확인해 보겠습니다.
| # Compare previous model predictions with loaded model predictions (these should be the same) y_preds == loaded_model_preds |
tensor([[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True]])
모두 True로 출력되는 것으로 봐서 로드된 모델 예측이 저장하기 전에 만든 예측과 동일합니다. 이는 모델이 예상대로 저장 및 로드되고 있음을 나타냅니다.
6. 모든 것을 종합하기
지금까지 한 모든 것을 종합해 보겠습니다.
| import torch from torch import nn import matplotlib.pyplot as plt torch.__version__ |
2.5.1+cu121
GPU를 사용할 수 있는 경우 device="cuda"로 설정하고, GPU를 사용할 수 없는 경우에는 device="cpu"로 설정하도록 합니다. device의 값이 모델과 데이터가 GPU 쪽 메모리 혹은 CPU쪽 메모리에 있을 지를 결정합니다.
| # Setup device agnostic code device = "cuda" if torch.cuda.is_available() else "cpu" print(f"Using device: {device}") |
Using device: cuda
GPU에 액세스할 수 있는 경우 아래 내용이 출력되었을 것입니다:
Using device: cuda
GPU를 사용할 수 없다면 아래처럼 CPU를 사용하게 됩니다. CPU를 사용하는 것은 작은 데이터 세트에는 괜찮지만 큰 데이터 세트에서는 학습하는데 걸리는 시간이 더 오래 걸립니다.
Using device: cuda
Data
앞에서 했듯이 가상의 데이터셋을 생성하기 위해 weight와 bias를 정합니다. 그런 다음 X값을 위해 0과 1 사이의 숫자 범위 내에서 0.02 간격으로 생성합니다.
X 값과 weight 및 bias 값을 선형 회귀 공식(y = weight * X + bias)에 대입하여 y를 생성합니다.
| # Create weight and bias weight = 0.7 bias = 0.3 # Create range values start = 0 end = 1 step = 0.02 # Create X and y (features and labels) X = torch.arange(start, end, step).unsqueeze(dim=1) # without unsqueeze, errors will happen later on (shapes within linear layers) y = weight * X + bias X[:10], y[:10] |
(tensor([[0.0000],
[0.0200],
[0.0400],
[0.0600],
[0.0800],
[0.1000],
[0.1200],
[0.1400],
[0.1600],
[0.1800]]),
tensor([[0.3000],
[0.3140],
[0.3280],
[0.3420],
[0.3560],
[0.3700],
[0.3840],
[0.3980],
[0.4120],
[0.4260]]))
이제 데이터를 Train 세트와 Test 세트로 분할해 보겠습니다. 80%의 Train 데이터와 20%의 Test 데이터 분할을 사용하겠습니다.
| train_split = int(0.8 * len(X)) X_train, y_train = X[:train_split], y[:train_split] X_test, y_test = X[train_split:], y[train_split:] len(X_train), len(y_train), len(X_test), len(y_test) |
(40, 40, 10, 10)
시각화해서 데이터를 확인해보면 직선 패턴입니다. Train 데이터 세트는 파란점으로, Test 데이터 세트는 초록점으로 그려집니다.
| # Note: If you've reset your runtime, this function won't work, # you'll have to rerun the cell above where it's instantiated. plot_predictions(X_train, y_train, X_test, y_test) |
PyTorch 선형 모델 구축하기
데이터를 확보했으니 이제 모델을 만들 차례입니다. 이전과 동일한 스타일의 모델을 만들되, 이번에는 nn.Parameter()를 사용하여 모델의 가중치와 바이어스 파라미터를 수동으로 정의하는 대신 nn.Linear(in_features, out_features)를 사용하여 이를 자동으로 수행하도록 하겠습니다. 여기서 in_features는 입력 데이터에 있는 차원 수이고 out_features는 출력하려는 차원 수입니다. 이 경우 데이터에는 레이블(y) 당 1개의 입력 특징(X)이 있으므로 이 두 값은 모두 1입니다.
| # nn.Module을 상속받아 모델 클래스를 생성합니다. class LinearRegressionModelV2(nn.Module): def __init__(self): super().__init__() # 모델 파라미터를 생성하기 위해 nn.Linear()을 사용합니다. self.linear_layer = nn.Linear(in_features=1, out_features=1) # forward 함수를 정의합니다. 입력 데이터 x가 nn.Linear()를 통과하여 출력을 얻습니다. def forward(self, x: torch.Tensor) -> torch.Tensor: return self.linear_layer(x) # 항상 일정한 결과를 얻기 위해 시드를 설정합니다. torch.manual_seed(42) model_1 = LinearRegressionModelV2() model_1, model_1.state_dict() |
(LinearRegressionModelV2(
(linear_layer): Linear(in_features=1, out_features=1, bias=True)
),
OrderedDict([('linear_layer.weight', tensor([[0.7645]])),
('linear_layer.bias', tensor([0.8300]))]))
model_1.state_dict()의 출력을 보면 nn.Linear() 레이어가 임의의 weight 및 bias 파라미터를 생성한 것을 확인할 수 있습니다.
이제 모델을 GPU에 배치해 보겠습니다.
.to(device)`를 사용하여 파이토치 객체가 있는 장치를 변경할 수 있습니다. 우선 현재 모델이 있는 장치가 어디인지 확인해 보겠습니다.
| # Check model device next(model_1.parameters()).device |
device(type='cpu')
모델이 기본적으로 CPU에 있는 것 같습니다. 가능한 경우 GPU에서 사용하도록 변경해 보겠습니다.
model_1.to(device)
next(model_1.parameters()).device
device(type='cuda', index=0)
위 코드는 GPU 사용 가능 여부에 관계없이 작동합니다.
GPU에 액세스할 수 있는 경우 다음과 같은 출력이 표시될 것입니다:
device(type='cuda', index=0)
학습하기
이제 훈련 및 테스트 루프를 구축할 차례입니다. 손실 함수와 옵티마이저가 필요합니다.
앞서 사용했던 손실함수 nn.L1Loss()와 옵티마이저 torch.optim.SGD()를 사용하겠습니다.
새로운 모델의 파라미터(model.parameters())를 옵티마이저에 전달하여 학습 중에 파라미터를 조정할 수 있도록 해야 합니다.
학습률은 0.01을 사용해봅니다.
| # 손실함수 loss_fn = nn.L1Loss() # 옵티마이저 optimizer = torch.optim.SGD(params=model_1.parameters(), lr=0.01) |
손실 함수와 옵티마이저가 준비되었으니 이제 훈련 및 테스트 루프를 사용하여 모델을 훈련하고 평가해 보겠습니다.
이 단계에서 이전 훈련 루프와 다른 점은 데이터를 대상 장치에 넣는 것뿐입니다. 이미 model_1.to(device)를 사용하여 대상 device에 모델을 배치했습니다. 데이터에 대해서도 똑같이 할 수 있습니다. 이렇게 하면 모델과 데이터가 모두 GPU에 있게 됩니다. 만약 하나는 GPU에 있고 하나는 CPU에 있으면 에러가 발생합니다.
이번에는 Train 데이터셋을 더 많이 학습에 사용하도록 epochs=1000으로 설정하면 앞서했을때보다 학습이 진행되는 시간이 길어집니다.
| torch.manual_seed(42) # 에포크 개수 epochs = 1000 # 데이터 세트를 GPU(GPU를 사용할 수없는 경우 CPU)로 옮깁니다. X_train = X_train.to(device) X_test = X_test.to(device) y_train = y_train.to(device) y_test = y_test.to(device) for epoch in range(epochs): ### 학습 루프 # Train 모드로 설정합니다. model_1.train() # 1. 모델 내에 있는 forward 메소드를 사용하여 Train 데이터에 대한 Forward pass를 진행하여 추론 결과를 얻습니다. y_pred = model_1(X_train) # 2. 손실을 계산합니다. 손실은 모델의 예측과 Train 데이터의 y값의 차이입니다. loss = loss_fn(y_pred, y_train) # 3. 그레디언트를 초기화합니다. optimizer.zero_grad() # 4. 역전파를 수행합니다. loss.backward() # 5. 모델의 파라미터를 업데이트합니다. optimizer.step() ### 테스트 루프 # 평가 모드로 설정합니다. model_1.eval() # 추론에 필요없는 기능을 끄도록 추론 모드 컨텍스트 관리자를 사용합니다. with torch.inference_mode(): # 1. 모델 내에 있는 forward 메소드를 사용하여 Test 데이터에 대한 Forward pass를 진행하여 추론 결과를 얻습니다. test_pred = model_1(X_test) # 2. 손실을 계산합니다. 손실은 모델의 예측과 Test 데이터의 y값의 차이입니다. test_loss = loss_fn(test_pred, y_test) # 100 에포크 마다 loss 로그를 출력합니다. if epoch % 100 == 0: print(f"Epoch: {epoch} | Train loss: {loss} | Test loss: {test_loss}") |
Epoch: 0 | Train loss: 0.5551779866218567 | Test loss: 0.5739762187004089
Epoch: 100 | Train loss: 0.006215683650225401 | Test loss: 0.014086711220443249
Epoch: 200 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882
Epoch: 300 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882
Epoch: 400 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882
Epoch: 500 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882
Epoch: 600 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882
Epoch: 700 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882
Epoch: 800 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882
Epoch: 900 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882
주: 머신 러닝의 무작위적 특성으로 인해 모델이 CPU에서 학습되었는지 또는 GPU에서 학습되었는지에 따라 약간 다른 결과(다른 손실 및 예측 값)가 나올 수 있습니다. 이는 두 기기에서 동일한 무작위 시드를 사용하더라도 마찬가지입니다. 차이가 크다면 오류를 찾아볼 수 있지만, 그 차이가 작다면(이상적으로는) 무시해도 됩니다. 좋네요! 손실이 꽤 적어 보입니다. 모델이 학습한 파라미터를 확인하고 하드코딩한 원래 파라미터와 비교해 보겠습니다.
| from pprint import pprint print("The model learned the following values for weights and bias:") pprint(model_1.state_dict()) print("\nAnd the original values for weights and bias are:") print(f"weights: {weight}, bias: {bias}") |
The model learned the following values for weights and bias:
OrderedDict([('linear_layer.weight', tensor([[0.6968]], device='cuda:0')),
('linear_layer.bias', tensor([0.3025], device='cuda:0'))])
And the original values for weights and bias are:
weights: 0.7, bias: 0.3
이제 미리 정해놓았던 파라미터에 근접했습니다.
주의할 점은 실제로 정답 파라미터를 미리 알 수 있는 경우는 거의 없다는 점을 기억하세요.
모델이 파라미터를 알아낼 수 있도록해야 합니다.
예측하기
이제 학습된 모델이 생겼으니 평가 모드를 켜고 몇 가지 예측을 해보겠습니다.
| # 평가 모드로 설정합니다. model_1.eval() # 추론에 필요없는 기능을 끄도록 추론 모드 컨텍스트 관리자를 사용합니다. with torch.inference_mode(): # 모델 내에 있는 forward 메소드를 사용하여 Test 데이터에 대한 Forward pass를 진행하여 추론 결과를 얻습니다. y_preds = model_1(X_test) y_preds |
tensor([[0.8600],
[0.8739],
[0.8878],
[0.9018],
[0.9157],
[0.9296],
[0.9436],
[0.9575],
[0.9714],
[0.9854]], device='cuda:0')
GPU의 데이터로 예측을 하는 경우, 위 출력의 마지막에 `device='cuda:0'이 있는 것을 볼 수 있습니다. 이는 데이터가 CUDA 장치 0(제로 인덱싱으로 인해 시스템에서 가장 먼저 액세스할 수 있는 GPU)에 있다는 것을 의미합니다.
이제 모델의 예측결과를 그래프로 그려보겠습니다.
참고로 pandas, matplotlib, NumPy와 같은 많은 데이터 과학 라이브러리는 GPU에 저장된 데이터를 사용할 수 없습니다. 따라서 CPU에 저장되지 않은 텐서 데이터로 이러한 라이브러리 중 하나의 함수를 사용하려고 할 때 문제가 발생할 수 있습니다. 이 문제를 해결하려면 대상 텐서에서 .cpu()를 호출하여 CPU에 대상 텐서의 복사본을 만들 수 있습니다.
| # plot_predictions(predictions=y_preds) # -> won't work... data not on CPU # Put data on the CPU and plot it plot_predictions(predictions=y_preds.cpu()) |

이제 예측한 빨간점이 녹색점(Ttest 데이터세트)과 거의 완벽하게 일치합니다.
모델 저장 및 불러오기
이제 나중에 모델을 사용할 수 있도록 파일에 저장해 보겠습니다.
| from pathlib import Path # 1. Create models directory MODEL_PATH = Path("models") MODEL_PATH.mkdir(parents=True, exist_ok=True) # 2. Create model save path MODEL_NAME = "01_pytorch_workflow_model_1.pth" MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME # 3. Save the model state dict print(f"Saving model to: {MODEL_SAVE_PATH}") torch.save(obj=model_1.state_dict(), # only saving the state_dict() only saves the models learned parameters f=MODEL_SAVE_PATH) |
Saving model to: models/01_pytorch_workflow_model_1.pth
저장한 모델이 제대로 작동하는지 확인하기 위해 모델을 다시 로드해 보겠습니다.
LinearRegressionModelV2()` 클래스의 새 인스턴스를 생성합니다.
모델 상태 딕셔너리를 torch.nn.Module.load_state_dict()를 사용하여 로드합니다.
모델의 새 인스턴스를 대상 장치로 전송합니다
| # LinearRegressionModelV2 클래스의 인스턴스를 생성합니다. loaded_model_1 = LinearRegressionModelV2() # Load model state dict loaded_model_1.load_state_dict(torch.load(MODEL_SAVE_PATH)) # 모델이 존재하는 장치를 변경합니다. 데이터가 GPU에 있다면 모델도 GPU에 있어야 합니다. loaded_model_1.to(device) print(f"Loaded model:\n{loaded_model_1}") print(f"Model on device:\n{next(loaded_model_1.parameters()).device}") |
Loaded model:
LinearRegressionModelV2(
(linear_layer): Linear(in_features=1, out_features=1, bias=True)
)
Model on device:
cuda:0
:5: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
loaded_model_1.load_state_dict(torch.load(MODEL_SAVE_PATH))
이제 로드된 모델을 평가하여 저장하기 전에 예측한 내용과 일치하는지 확인할 수 있습니다.
| # Evaluate loaded model loaded_model_1.eval() with torch.inference_mode(): loaded_model_1_preds = loaded_model_1(X_test) y_preds == loaded_model_1_preds |
tensor([[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True]], device='cuda:0')