
괜찮은 파이토치 강좌 - 01. 파이토치 기초
괜찮은 파이토치 강좌를 찾아서 나름 다시 정리해본 결과를 공유합니다.
최초작성 2024. 11. 19
다음 문서를 기반으로 작성되었습니다. 코랩에서 실행한 결과를 정리했습니다.
https://www.learnpytorch.io/00_pytorch_fundamentals/
1. PyTorch 코드 실행하기
2.텐서 소개
3.텐서 생성하기
난수로 채워진 텐서 생성하기
0 또는 1로 채워진 텐서 생성하기
범위 값으로 채워진 텐서 생성하기
다른 텐서와 크기가 동일한 텐서 생성하기
4.텐서 데이터 타입
특정 데이터 타입의 텐서 생성하기
5.텐서 정보 얻기
6.텐서 조작하기
기본 연산
행렬 곱셈(Matrix multiplication)
요소별 곱셈과 행렬 곱셈의 차이
행렬곱셈과 신경망
min, max, mean, sum
Positional min/max
텐서 데이터 타입 변경
텐서의 내부의 값 변경없이 형태나 차원 변경하기
인덱싱(Indexing)
7.파이토치 텐서와 넘파이 배열간의 변환
8.재현성
9.GPU에서 텐서 사용하기
9-1. GPU 사용하기
9-2. GPU 상에서 파이토치가 동작하도록 만들기
9-2.1 애플 실리콘(Apple Silicon) GPU에서 파이토치 실행하기
9-3. 텐서(또는 모델)을 GPU로 옮기기
9-4. 텐서를 GPU에서 CPU로 옮기기
PyTorch는 오픈 소스 머신 러닝 및 딥 러닝 프레임워크입니다.
2022년 2월 기준으로 머신 러닝 연구 논문과 논문을 구현한 코드 저장소를 추적하는 웹사이트인 Papers With Code에서 가장 많이 사용되는 딥 러닝 프레임워크입니다.
1. PyTorch 코드 실행하기
설치되어 있는 파이토치를 첨 사용시 가장 먼저하는 것은 파이토치의 버전을 확인하는 것입니다. 현재 코랩에 기본 설치되어있는 파이토치 패키지의 버전이 출력됩니다.
| import torch torch.__version__ |
2.5.0+cu121
2.텐서 소개
파이토치에선 데이터를 텐서(Tensor)에 저장합니다.
예를 들어, 이미지를 나타내는 텐서는 색상 채널, 높이, 너비의 세 가지 차원을 갖습니다.
컬러 이미지의 채널이 빨강, 초록, 파랑으로 3개이고 이미지의 높이가 224 픽셀, 이미지의 너비가 224 픽셀인 경우 [3, 224, 224] 형태의 텐서로 나타낼 수 있습니다.

3.텐서 생성하기
텐서를 구성하는 차원에 따라 0차원은 스칼라, 1차원은 벡터, 2차원은 행렬, 3차원 이상은 텐서라고 나눠 부르지만 일반적으로 이 모두를 텐서라고 부릅니다.
숫자 하나로 생성되는 스칼라(scalar)는 0차원 텐서입니다.
| scalar = torch.tensor(7) scalar |
tensor(7)
스칼라는 단일 숫자이지만 torch.Tensor 타입입니다.
| type(scalar) |
torch.Tensor
ndim 속성을 사용하면 스칼라의 차원은 0인 것을 확인할 수 있습니다.
| scalar.ndim |
0
item() 메서드를 사용하면 스칼라 텐서를 파이썬 정수로 바꿀 수 있습니다.
| scalar.item() |
7
텐서가 int 데이터 타입으로 바뀐걸 볼 수 있습니다.
| type(scalar.item()) |
int
1차원 구조로 생성하는 텐서를 벡터(Vector)라고 부릅니다.
| vector = torch.tensor([7, 7]) vector |
tensor([7, 7])
스칼라와 동일하게 벡터는 torch.Tensor 데이터 타입입니다.
| type(vector) |
torch.Tensor
len을 사용하여 벡터에 포함된 원소의 개수를 확인할 수 있습니다. 여기에선 벡터가 2개의 원소를 가지고 있습니다.
| len(vector) |
2
ndim 속성을 사용하여 벡터의 차원을 확인해보면 1차원입니다.
| vector.ndim |
1
텐서의 shape 속성을 출력하여 텐서 안의 요소들이 어떻게 배열되어 있는지 확인할 수 있습니다. 여기에선 벡터의 shape가 [2]입니다. 텐서의 인덱스 0차원의 원소 개수가 2개라는 의미입니다.
| vector.shape |
torch.Size([2])
텐서를 구성하는 차원이 2차원이면 행렬이라고 부릅니다.
| MATRIX = torch.tensor([[7, 8, 9], [10, 11, 12]]) MATRIX |
tensor([[ 7, 8, 9],
[10, 11, 12]])
스칼라, 벡터와 동일하게 행렬의 데이터타입은 torch.Tensor입니다.
| type(MATRIX) |
torch.Tensor
dim 속성을 사용하여 차원을 확인해보면 MATRIX의 차원은 2차원입니다.
| MATRIX.ndim |
2
'shape'속성을 출력해봅니다. MATRIX는 2개의 행과 3개의 열을 가진 2차원 텐서이므로 shape이 torch.Size([2, 3])입니다. 인덱스 0차원의 크기가 2이고 인덱스 1차원의 크기가 3입니다.
| MATRIX.shape |
torch.Size([2, 3])
3차원 이상 구조를 갖고 있으면 따로 구분하여 부르는 이름은 없고 텐서(Tensor)라고 부릅니다.
| TENSOR = torch.tensor([[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]]) TENSOR |
tensor([[[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]]])
shape 속성을 출력합니다.
3차원 텐서는 2차원 행렬들이 쌓여있는 구조입니다. 3개의 행과 4개의 열을 가진 2차원 행렬이 1개 쌓여있어서 shape가 [1, 3, 4]가 됩니다. 인덱스 0차원의 크기는 1이고 인덱스 1차원의 크기는 3, 인덱스 2차원의 크기는 4입니다.
| TENSOR.shape |
torch.Size([1, 3, 4])
스칼라, 벡터, 행렬과 동일하게 텐서의 데이터 타입은 torch.Tensor입니다.
| type(TENSOR) |
torch.Tensor
dim을 사용하여 차원을 출력해보면 3차원입니다.
| TENSOR.ndim |
3
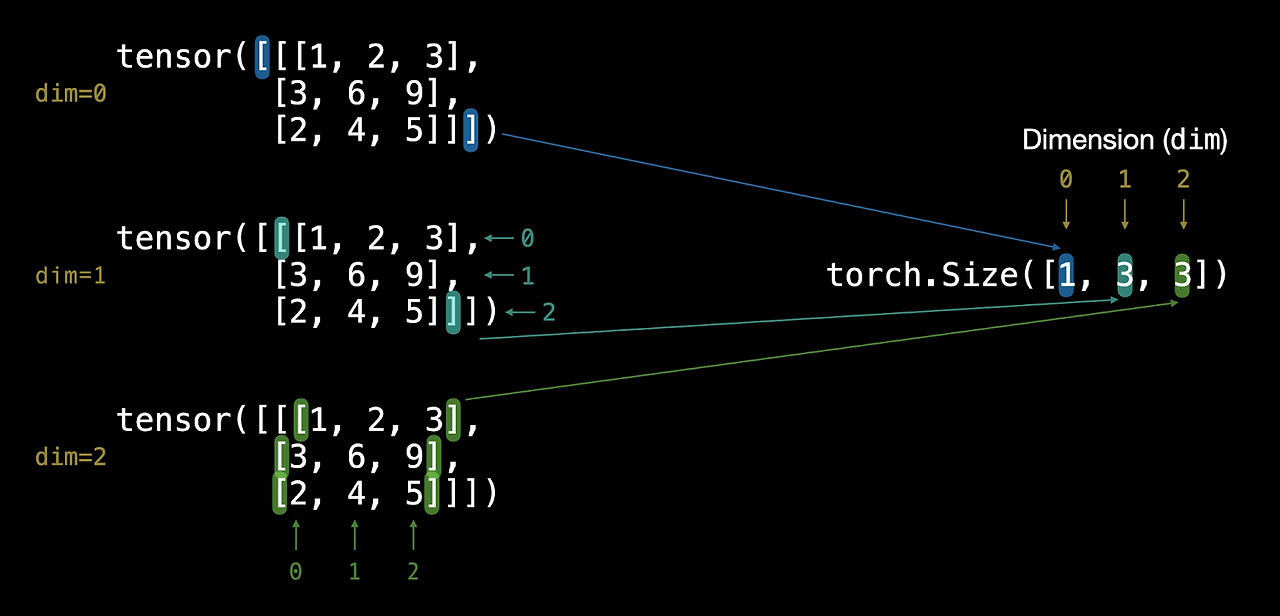
Note: '스칼라'와 '벡터'는 y 또는 a와 같은 소문자를, '행렬'과 '텐서'는 X 또는 W와 같은 대문자를 사용합니다.
난수로 채워진 텐서 생성하기
무작위 데이터로 채워진 텐서로 신경망을 구성하고 주어지는 입력,출력 텐서로부터 패턴을 찾아 신경망 내 텐서의 값을 업데이트합니다.
수많은 입력,출력 텐서를 신경망에 제공하여 위 작업을 반복하면 신경망 내에 있는 텐서는 주어진 입력 텐서에 대해 주어진 출력 텐서를 신경망의 결과물로 내놓을 수 있게 됩니다.
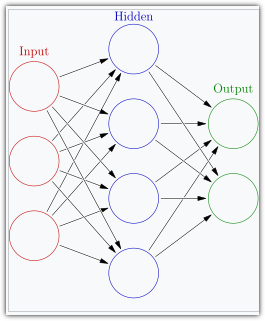
이미지 출처 : https://en.wikipedia.org/wiki/Neural_network_(machine_learning)
torch.rand()를 시용하여 크기 3 x 4의 텐서에 무작위 난수를 채워 생성합니다.
| random_tensor = torch.rand(size=(3, 4)) random_tensor, random_tensor.dtype |
(tensor([[0.5351, 0.0324, 0.4873, 0.2349],
[0.0756, 0.5896, 0.5819, 0.5215],
[0.6155, 0.5651, 0.7866, 0.5647]]),
torch.float32)
난수를 채운 크기 224 x 224 x 3의 3차원 텐서를 생성합니다.
| random_image_size_tensor = torch.rand(size=(224, 224, 3)) random_image_size_tensor.shape, random_image_size_tensor.ndim |
(torch.Size([224, 224, 3]), 3)
0 또는 1로 채워진 텐서 생성하기
torch.zeros()를 사용하여 0으로 채워진 크기 3 x 4인 2차원 텐서를 생성합니다.
| zeros = torch.zeros(size=(3, 4)) zeros, zeros.dtype |
(tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]),
torch.float32)
torch.ones()를 사용하여 1로 채워진 크기 3 x 4인 2차원 텐서를 생성합니다.
| ones = torch.ones(size=(3, 4)) ones, ones.dtype |
(tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]),
torch.float32)
범위 값으로 채워진 텐서 생성하기
텐서에 1에서 10까지 숫자와 같은 범위를 채워야 할 필요가 있을 수 있습니다. 이를 위해 torch.arange(start, end, step)를 사용하면 됩니다.
Where:
start = 범위의 시작(예: 0)
end = 범위의 끝(예: 10)
step = 각 값 사이의 단계 수(예: 1)
| zero_to_ten = torch.arange(start=0, end=10, step=1) zero_to_ten |
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
다른 텐서와 크기가 동일한 텐서 생성하기
특정 텐서의 shape와 동일하면서 0 또는 1로 채워진 텐서를 생성하기 위해 torch.zeros_like(input) 또는 torch.ones_like(input)를 사용할 수 있습니다.
| # zero_to_ten 텐서와 동일한 크기의 텐서를 생성하여 0으로 채웁니다. ten_zeros = torch.zeros_like(input=zero_to_ten) ten_zeros |
tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
4.텐서 데이터 타입
파이토치의 텐서는 CPU 메모리와 GPU 메모리에 중 어느 쪽에 저장되는 지에 따라 데이터 타입이 다릅니다.
일반적으로 torch.cuda가 표시되면 텐서가 GPU용으로 사용되고 있는 것입니다
실수를 위한 데이터 타입으로는 32비트 값을 저장할 수 있는 torch.float32 또는 torch.float, 16비트 값을 저장할 수 있는 torch.float16 또는 torch.half, 64비트 값을 저장할 수 있는 torch.float64 또는 torch.double이 있습니다.
마찬가지로 정수를 위해 8비트, 16비트, 32비트, 64비트 값을 저장하기 위한 데이터 타입이 있습니다.
8, 16, 32, 64 비트로 표시되는 정밀도 값이 높을수록 숫자를 표현하는 데 사용되는 데이터가 더 세밀해집니다.
이는 딥 러닝과 수치 컴퓨팅에서 중요한데, 계산해야 할 세부 사항이 많을수록 더 많은 컴퓨팅을 사용해야 하기 때문입니다.
따라서 정밀도가 낮은 데이터 유형은 일반적으로 계산 속도가 빠르지만 정확도는 떨어집니다.
특정 데이터 타입의 텐서 생성하기
특정 데이터 타입을 가진 텐서를 만드는 방법을 살펴보겠습니다. 'dtype' 매개변수를 사용하면 됩니다.
| # 텐서 생성시 데이터 타입을 지정하지 않으면 디폴트 데이터 타입은 float32입니다. float_32_tensor = torch.tensor([3.0, 6.0, 9.0], dtype=None, # 디폴트 값은 None입니다, 데이터 타입이 torch.float32이 됩니다. device=None, # 텐서를 저장할 장치를 지정하지 않으면 cpu에 저장됩니다. requires_grad=False) # # False이면 텐서에 대한 연산들이 기록되지 않습니다. True로 설정하면 자동 미분을 위해 연산이 기록됩니다 float_32_tensor.shape, float_32_tensor.dtype, float_32_tensor.device |
(torch.Size([3]), torch.float32, device(type='cpu'))
5.텐서 정보 얻기
텐서에서 얻을 수 있는 정보입니다.
shape - 텐서의 형태
dtype - 데이터 타입
device - 텐서가 저장된 장치 이름
| # 텐서를 생성합니다. some_tensor = torch.rand(3, 4) # 텐서 정보를 출력합니다. print(some_tensor) print(f"Shape : {some_tensor.shape}") print(f"Datatype : {some_tensor.dtype}") print(f"Device : {some_tensor.device}") |
tensor([[0.3145, 0.6161, 0.6541, 0.4914],
[0.6259, 0.8966, 0.8038, 0.5009],
[0.9306, 0.9701, 0.7579, 0.2492]])
Shape : torch.Size([3, 4])
Datatype : torch.float32
Device : cpu
6.텐서 조작하기
파이토치에선 데이터를 텐서에 저장합니다. 신경망에 입력,출력 텐서를 제공하여 패턴을 찾는 과정에 다음과 같은 연산을 하게 됩니다. 이런 연산들을 하는 블록들을 쌓아서 신경망을 구성합니다.
- 덧셈
- 빼기
- 곱셈(요소 단위)
- 나누기
- 행렬 곱셈 등등
기본 연산
텐서의 덧셈 연산은 + 기호를 사용합니다.
텐서와 정수를 더합니다.
| tensor = torch.tensor([1, 2, 3]) tensor + 10 |
tensor([11, 12, 13])
연산을 수행했는데 tensor 텐서의 값이 변하지 않았습니다.
| tensor |
tensor([1, 2, 3])
tensor 변수의 값을 바꾸려면 재할당을 해야 합니다.
| tensor = tensor + 10 tensor |
tensor([11, 12, 13])
텐서 두개를 더합니다.
| tensor_A = torch.tensor([1, 2, 3]) tensor_B = torch.tensor([10, 20, 30]) tensor_A + tensor_B |
tensor([11, 22, 33])
기호 + 대신에 torch.add()를 사용할수도 있습니다.
| torch.add(tensor_A, tensor_B) |
tensor([11, 22, 33])
텐서의 곱셈 연산은 * 기호를 사용합니다.
텐서와 정수를 곱합니다.
| tensor * 10 |
tensor([110, 120, 130])
텐서 두개를 곱합니다.
| tensor_A = torch.tensor(2) tensor_B = torch.tensor(10) tensor_A * tensor_B |
tensor(20)
기호 * 대신에 torch.multiply를 사용할 수 있습니다.
| torch.multiply(tensor_A, tensor_B) |
tensor(20)
행렬 곱셈(Matrix multiplication)
머신 러닝과 딥 러닝 알고리즘(신경망 등)에서 가장 일반적인 연산 중 하나는 행렬 곱셈입니다. 파이토치는 torch.matmul() 메서드를 사용하여 행렬 곱셈을 할 수 있습니다.
기억해야 할 행렬 곱셈의 두 가지 규칙은 다음과 같습니다. 파이썬에서 “@”는 행렬 곱셈을 위한 기호입니다.
1.내부 차원이 일치해야 합니다. 앞에 주어진 텐서의 차원 1의 값과 뒤에 주어진 텐서의 차원 0의 값이 일치해야 합니다.
- (3, 2) @ (3, 2)는 작동하지 않습니다.
- (2, 3) @ (3, 2)는 작동합니다.
- (3, 2) @ (2, 3)은 작동합니다.
2.결과 행렬은 외부 차원의 모양을 갖습니다. 앞에 주어진 텐서의 차원 0의 값과 뒤에 주어진 텐서의 차원 1의 값을 형태로 하는 텐서가 생성됩니다.
- (2, 3) @ (3, 2) -> (2, 2)
- (3, 2) @ (2, 3) -> (3, 3)
요소별 곱셈과 행렬 곱셈의 차이
요소별 곱셈은 대응하는 원소끼리 곱하는 반면 행렬 곱셈은 내적을 계산합니다.
| import torch # 테스트에 사용할 텐서를 생성합니다. tensor = torch.tensor([1, 2, 3]) tensor.shape |
torch.Size([3])
| # 요소별 곱셈(Element-wise matrix multiplication) tensor * tensor |
tensor([1, 4, 9])
| # 행렬곱셈 torch.matmul(tensor, tensor) |
tensor(14)
행렬 곱셈은 수작업으로 할 수 있지만 권장하지 않습니다. 내장된 torch.matmul() 메서드가 더 빠릅니다.
| %%time value = 0 for i in range(len(tensor)): value += tensor[i] * tensor[i] value |
CPU times: user 777 µs, sys: 0 ns, total: 777 µs
Wall time: 3.83 ms
tensor(14)
| %%time torch.matmul(tensor, tensor) |
CPU times: user 37 µs, sys: 6 µs, total: 43 µs
Wall time: 46.3 µs
tensor(14)
행렬곱셈과 신경망
딥러닝의 대부분은 행렬을 곱하는 연산으로 이루어지는데 행렬 곱셈에는 엄격한 규칙이 있기때문에 이것을 맞춰줘야 합니다.
예를 들어 아래처럼 3 x 2 행렬과 3 x 2 행렬은 곱할 수 없기 때문에 에러가 발생합니다.
| tensor_A = torch.tensor([[1, 2], [3, 4], [5, 6]], dtype=torch.float32) tensor_B = torch.tensor([[7, 10], [8, 11], [9, 12]], dtype=torch.float32) torch.matmul(tensor_A, tensor_B) |
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-44-5893e600ebdf> in <cell line: 10>()
8 [9, 12]], dtype=torch.float32)
9
---> 10 torch.matmul(tensor_A, tensor_B) # (this will error)
RuntimeError: mat1 and mat2 shapes cannot be multiplied (3x2 and 3x2)
전치(transpose)를 사용하여 3 x 2 행렬과 2 x 3 행렬간의 곱셈으로 바꿔줘야 합니다.
| print(f"원래 shapes: tensor_A = {tensor_A.shape}, tensor_B = {tensor_B.shape}\n") print(f"전치 후 shapes: tensor_A = {tensor_A.shape} , tensor_B.T = {tensor_B.T.shape}\n") print() print(f"행렬곱셈 결과 : {tensor_A.shape} * {tensor_B.T.shape}\n") output = torch.matmul(tensor_A, tensor_B.T) print(output) print(f"\nOutput shape: {output.shape}") |
원래 shapes: tensor_A = torch.Size([3, 2]), tensor_B = torch.Size([3, 2])
전치 후 shapes: tensor_A = torch.Size([3, 2]) , tensor_B.T = torch.Size([2, 3])
행렬곱셈 결과 : torch.Size([3, 2]) * torch.Size([2, 3])
tensor([[ 27., 30., 33.],
[ 61., 68., 75.],
[ 95., 106., 117.]])
Output shape: torch.Size([3, 3])
신경망은 행렬 곱셈을 사용하여 구성되어 있습니다.
피드 포워드 레이어 또는 완전 연결 레이어라고도 하는 torch.nn.Linear() 모듈은 입력 x와 가중치 행렬 W 사이의 행렬 곱셈으로 구현합니다.
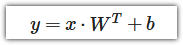
- 여기서 x는 레이어에 대한 입력입니다(딥러닝은 torch.nn.Linear()와 같은 레이어가 서로 겹쳐진 스택입니다).
- W는 레이어에서 생성된 가중치 행렬로, 처음에는 난수로 시작하여 신경망이 데이터의 패턴을 더 잘 표현하도록 학습하면서 조정됩니다. 가중치 행렬에 전치 적용하는 “T”를 주목하세요.
- b는 가중치와 입력을 약간 상쇄하는 데 사용되는 바이어스입니다.
- 'y'는 출력(입력 x에서 패턴을 발견하기 위해 주어지는 출력을 입력으로 제공합니다. )입니다.
이것은 선형 함수이며(y=mx+b), 좌표평면에서 선형함수는 직선을 그립니다.
선형 레이어를 테스트해봅니다.
| # 재현성을 위해 랜덤시드를 사용합니다. torch.manual_seed(42) # 선형 레이어는 행렬곱셈으로 구현됩니다. linear = torch.nn.Linear(in_features=2, # 입력의 차원 out_features=6) # 출력의 차원 x = torch.tensor([[1, 2], [3, 4], [5, 6]], dtype=torch.float32) output = linear(x) print(f"Input shape: {x.shape}\n") print(f"Output:\n{output}\n\nOutput shape: {output.shape}") |
Input shape: torch.Size([3, 2])
Output:
tensor([[2.2368, 1.2292, 0.4714, 0.3864, 0.1309, 0.9838],
[4.4919, 2.1970, 0.4469, 0.5285, 0.3401, 2.4777],
[6.7469, 3.1648, 0.4224, 0.6705, 0.5493, 3.9716]],
grad_fn=<AddmmBackward0>)
Output shape: torch.Size([3, 6])
min, max, mean, sum
텐서의 최대값, 최소값, 평균값, 합계를 구합니다.
| x = torch.arange(0, 100, 10) print('x\n', x) print() print(f"Minimum: {x.min()}") print(f"Maximum: {x.max()}") # print(f"Mean: {x.mean()}") # this will error print(f"Mean: {x.type(torch.float32).mean()}") # won't work without float datatype print(f"Sum: {x.sum()}") |
x
tensor([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
Minimum: 0
Maximum: 90
Mean: 45.0
Sum: 450
텐서의 최대값, 최소값, 평균값, 합계를 구하기 위해 파이토치 메소드를 사용할 수도 있습니다.
| torch.max(x), torch.min(x), torch.mean(x.type(torch.float32)), torch.sum(x) |
(tensor(90), tensor(0), tensor(45.), tensor(450))
Positional min/max
torch.argmax()와 torch.argmin()을 사용하여 각각 최대값 또는 최소값에 해당하는 텐서의 인덱스를 찾을 수 있습니다.
아래 예제에선 실제 값이 아니라 가장 높은 값 90과 가장 낮은 값 10이 있는 위치를 찾아줍니다. 나중에 softmax 사용시 이 기능을 사용합니다.
| tensor = torch.arange(10, 100, 10) print(f"Tensor: {tensor}") print(f"Index where max value occurs: {tensor.argmax()}") print(f"Index where min value occurs: {tensor.argmin()}") |
Tensor: tensor([10, 20, 30, 40, 50, 60, 70, 80, 90])
Index where max value occurs: 8
Index where min value occurs: 0
텐서 데이터 타입 변경
dtype 속성을 출력하여 텐서의 데이터타입을 확인할 수 있고 type 메소드를 사용하여 텐서의 데이터타입을 변경할 수 있습니다.
| tensor = torch.arange(10., 100., 10.) print(tensor.dtype) tensor_float16 = tensor.type(torch.float16) print(tensor_float16) tensor_int8 = tensor.type(torch.int8) print(tensor_int8) |
torch.float32
tensor([10., 20., 30., 40., 50., 60., 70., 80., 90.], dtype=torch.float16)
tensor([10, 20, 30, 40, 50, 60, 70, 80, 90], dtype=torch.int8)
데이터타입에 적힌 숫자, 비트수가 낮을수록(예: 32, 16, 8) 컴퓨터가 값을 저장하는 정확도가 떨어지는 대신 저장 용량이 줄어들며 계산 속도가 빨라지고 전체 모델 크기가 작아집니다.
모바일 기반 신경망은 8비트 정수로 작동하는 경우가 많은데, 이는 부동 소수점 32보다 더 작고 빠르게 실행되지만 정확도는 떨어집니다. 이에 대한 자세한 내용은 컴퓨팅의 정밀도에 대해 읽어보시기 바랍니다.
텐서의 내부의 값 변경없이 형태나 차원 변경하기
텐서 내부의 값을 실제로 변경하지 않고 텐서의 차원을 변경하거나 형태를 바꾸는 방법을 다룹니다.
| x = torch.arange(1., 8.) x, x.shape |
(tensor([1., 2., 3., 4., 5., 6., 7.]), torch.Size([7]))
torch.reshape()를 사용하여 0차원에 차원을 추가해줍니다.
| x_reshaped = x.reshape(1, 7) x_reshaped, x_reshaped.shape |
(tensor([[1., 2., 3., 4., 5., 6., 7.]]), torch.Size([1, 7]))
reshape를 사용하면 뷰를 생성하기 때문에 값을 변경시 원본에도 영향을 줍니다.
| z = x.reshape(1, 7) z[:, 0] = 5 z, x |
(tensor([[5., 2., 3., 4., 5., 6., 7.]]), tensor([5., 2., 3., 4., 5., 6., 7.]))
1차원 텐서를 5개 쌓으려면 torch.stack()을 사용하면 됩니다.
| x_stacked = torch.stack([x, x, x, x], dim=0) # dim에 지정한 차원에 따라 텐서를 쌓는 방법이 달라집니다. x_stacked.shape, x_stacked |
(torch.Size([4, 7]),
tensor([[5., 2., 3., 4., 5., 6., 7.],
[5., 2., 3., 4., 5., 6., 7.],
[5., 2., 3., 4., 5., 6., 7.],
[5., 2., 3., 4., 5., 6., 7.]]))
torch.squeeze()는 텐서를 1차원으로 만들어줍니다.
| print(f"Previous tensor: {x_reshaped}") print(f"Previous shape: {x_reshaped.shape}") x_squeezed = x_reshaped.squeeze() print(f"\nNew tensor: {x_squeezed}") print(f"New shape: {x_squeezed.shape}") |
Previous tensor: tensor([[5., 2., 3., 4., 5., 6., 7.]])
Previous shape: torch.Size([1, 7])
New tensor: tensor([5., 2., 3., 4., 5., 6., 7.])
New shape: torch.Size([7])
torch.unsqueeze()를 사용하여 특정 인덱스에 차원을 추가할 수 있습니다.
| print(f"Previous tensor: {x_squeezed}") print(f"Previous shape: {x_squeezed.shape}") x_unsqueezed = x_squeezed.unsqueeze(dim=0) print(f"\nNew tensor: {x_unsqueezed}") print(f"New shape: {x_unsqueezed.shape}") |
Previous tensor: tensor([5., 2., 3., 4., 5., 6., 7.])
Previous shape: torch.Size([7])
New tensor: tensor([[5., 2., 3., 4., 5., 6., 7.]])
New shape: torch.Size([1, 7])
torch.permute(input, dims)를 사용하여 축 값의 순서를 재정렬할 수 있습니다.
| x_original = torch.rand(size=(224, 224, 3)) x_permuted = x_original.permute(2, 0, 1) # 다음처럼 축을 바꿉니다. 0->1, 1->2, 2->0 print(f"Previous shape: {x_original.shape}") print(f"New shape: {x_permuted.shape}") |
Previous shape: torch.Size([224, 224, 3])
New shape: torch.Size([3, 224, 224])
인덱싱(Indexing)
인덱싱은 텐서에서 특정 열이나 특정 행의 데이터를 선택하는 방법입니다. 파이썬 리스트나 넘파이 배열에서 인덱싱 하던 방법과 유사합니다.
| x = torch.arange(1, 7).reshape(1, 2, 3) x, x.shape |
(tensor([[[1, 2, 3],
[4, 5, 6]]]),
torch.Size([1, 2, 3]))
인덱싱 값은 외부 차원 -> 내부 차원으로 이동합니다.
| print(f"First square bracket:\n{x[0]}") print(f"Second square bracket: {x[0][0]}") print(f"Third square bracket: {x[0][0][0]}") |
First square bracket:
tensor([[1, 2, 3],
[4, 5, 6]])
Second square bracket: tensor([1, 2, 3])
Third square bracket: 1
콜론 :를 사용하여 “이 차원의 모든 값”을 지정할 수 있으며 콤마 ,를 사용하여 여러개의 차원에 대한 인덱스를 추가할 수 있습니다.
0차원은 모든 값을 지정하며 1차원은 인덱스 0만 지정합니다.
| x[:, 0] |
tensor([[1, 2, 3]])
0차원과 1차원은 모든 값을 지정하며 2차원은 인덱스 1만 지정합니다.
| x[:, :, 1] |
tensor([[2, 5]])
0차원은 모든 값을 지정하며 1치원과 2차원은 인덱스 1만 지정합니다.
| x[:, 1, 1] |
tensor([5])
0차원과 1차원은 인덱스 0을 지정하며, 2차원은 모든 값을 지정합니다.
| x[0, 0, :] # same as x[0][0] |
tensor([1, 2, 3])
7.파이토치 텐서와 넘파이 배열간의 변환
파이토치 텐서와 넘파이 배열간에 상호 변환이 가능합니다.
torch.from_numpy()를 사용하여 넘파이 배열을 파이토치 텐서로 변환합니다.
| import numpy as np array = np.arange(1.0, 8.0) # float64 데이터 타입을 갖습니다. tensor = torch.from_numpy(array) # 넘파이 배열과 같은 데이터 타입을 갖습니다. array, tensor |
(array([1., 2., 3., 4., 5., 6., 7.]),
tensor([1., 2., 3., 4., 5., 6., 7.], dtype=torch.float64))
tensor.numpy()를 사용하여 파이토치 텐서를 NumPy 배열로 변환합니다.
| tensor = torch.ones(7) # float32의 데이터타입을 갖습니다. numpy_tensor = tensor.numpy() # 파이토치 텐서와 같은 데이터 타입을 갖습니다. tensor, numpy_tensor |
(tensor([1., 1., 1., 1., 1., 1., 1.]),
array([1., 1., 1., 1., 1., 1., 1.], dtype=float32))
8.재현성
신경망은 데이터의 패턴을 학습하기 위해 난수로 채워진 텐서에 대해 연산을 수행하여 패턴을 설명할수 있는 값을 텐서에 채웁니다.
여기서 중요한 점은 내 피시에서 실행한 학습 결과가 다른 피시에서도 동일한 학습 결과를 얼을 수 있으려면 초기에 텐서에 저장한 무작위 수에 대한 '재현성(reproducibility)'이 필요합니다. 학습 시작전 항상 동일한 무작위수를 텐서에 저장할 필요가 있다는 것입니다.
torch.rand()를 사용하여 두 개의 텐서를 생성해보면 값이 다릅니다.
| import torch # 무작위수로 채워진 텐서 2개를 생성합니다. random_tensor_A = torch.rand(3, 4) random_tensor_B = torch.rand(3, 4) print(f"Tensor A:\n{random_tensor_A}\n") print(f"Tensor B:\n{random_tensor_B}\n") print(f"두 개의 텐서가 동일한 값으로 구성되어 있는지 확인합니다.") random_tensor_A == random_tensor_B |
Tensor A:
tensor([[0.8016, 0.3649, 0.6286, 0.9663],
[0.7687, 0.4566, 0.5745, 0.9200],
[0.3230, 0.8613, 0.0919, 0.3102]])
Tensor B:
tensor([[0.9536, 0.6002, 0.0351, 0.6826],
[0.3743, 0.5220, 0.1336, 0.9666],
[0.9754, 0.8474, 0.8988, 0.1105]])
두 개의 텐서가 동일한 값으로 구성되어 있는지 확인합니다.
tensor([[False, False, False, False],
[False, False, False, False],
[False, False, False, False]])
torch.manual_seed(seed)를 사용하여 '동일한' 값을 가진 두 개의 무작위 텐서를 만들수 있습니다. 여기에선 seed 값으로 42를 지정하고 있습니다.
| import torch import random RANDOM_SEED=42 torch.manual_seed(seed=RANDOM_SEED) random_tensor_C = torch.rand(3, 4) torch.random.manual_seed(seed=RANDOM_SEED) # 10번째 줄을 주석처리하고 실행해보면 똑같은 무작위 텐서를 생성하지 않게됩니다. random_tensor_D = torch.rand(3, 4) print(f"Tensor C:\n{random_tensor_C}\n") print(f"Tensor D:\n{random_tensor_D}\n") print(f"Does Tensor C equal Tensor D? (anywhere)") random_tensor_C == random_tensor_D |
Tensor C:
tensor([[0.8823, 0.9150, 0.3829, 0.9593],
[0.3904, 0.6009, 0.2566, 0.7936],
[0.9408, 0.1332, 0.9346, 0.5936]])
Tensor D:
tensor([[0.8823, 0.9150, 0.3829, 0.9593],
[0.3904, 0.6009, 0.2566, 0.7936],
[0.9408, 0.1332, 0.9346, 0.5936]])
Does Tensor C equal Tensor D? (anywhere)
tensor([[True, True, True, True],
[True, True, True, True],
[True, True, True, True]])
파이토치 재현성 관련 내용은 시간을 내어 다음 문서를 읽어보세요.
https://pytorch.org/docs/stable/notes/randomness.html
9.GPU에서 텐서 사용하기
딥러닝 알고리즘은 많은 숫자 연산을 필요로 하며 기본적으로 이러한 연산은 CPU에서 수행되는 경우가 많습니다.
신경망에 필요한 행렬 곱셈 연산의 경우 CPU보다 GPU에서 훨씬 빠르게 동작하기 때문에 GPU를 사용하면 신경망 훈련 시간을 많이 단축할 수 있습니다.
파이토치에서 GPU를 사용하도록 하는 방법을 알아봅니다.
9-1. GPU 사용하기
Nvidia GPU에 액세스할 수 있는지 확인하려면 !nvidia-smi를 실행하세요.
| !nvidia-smi |

로컬 피시에서 실행시 위 화면이 보이지 않는다면 Nvidia GPU를 사용하기 위해 CUDA를 설치하는 방법을 확인하세요.
9-2. GPU 상에서 파이토치가 동작하도록 만들기
torch.cuda.is_available()을 사용하여 파이토치가 GPU를 액세스할 수 있는지 테스트할 수 있습니다. True가 보여야 파이토치에서 GPU를 사용할 수 있는 것입니다.
| import torch torch.cuda.is_available() |
True
사용 가능한 디바이스의 종류를 저장하기 위해 'device' 변수를 만들어 보겠습니다. “cuda”가 출력되면 파이토치 코드가 CUDA 장치(GPU)를 사용하도록 하며 “cpu”가 출력되면 파이토치 코드가 CPU를 사용하도록 합니다.
| device = "cuda" if torch.cuda.is_available() else "cpu" device |
cuda
파이토치에서 두개 이상의 GPU를 사용할 수도 있습니다. 'torch.cuda.device_count()'를 사용하여 파이토치에서 액세스할 수 있는 GPU 수를 계산할 수 있습니다.
| torch.cuda.device_count() |
1
특정 프로세스를 한 GPU에서 실행하고 다른 프로세스를 다른 GPU에서 실행하려는 경우 PyTorch가 액세스할 수 있는 GPU 수를 알면 유용합니다(PyTorch에는 모든 GPU에서 프로세스를 실행할 수 있는 기능도 있습니다).
9-2.1 애플 실리콘(Apple Silicon) GPU에서 파이토치 실행하기
Apple의 M1/M2/M3 GPU에서 파이토치를 실행할때 torch.backends.mps 모듈을 사용할 수 있습니다.
torch.backends.mps.is_available()`을 사용하여 파이토치가 GPU에 액세스할 수 있는지 테스트할 수 있습니다.코랩에서 실행한 결과라서 여기에선 False가 출력되었습니다.
| import torch torch.backends.mps.is_available() |
cpu
파이토치 코드에서 다음과 같은 코드를 종종 발견할 수 있습니다. NVidia나 Apple의 GPU를 먼저 시도해보고 사용할 수 없으면 CPU를 사용하도록 변수 device를 설정하기 위해 사용됩니다.
| if torch.cuda.is_available(): device = "cuda" # Use NVIDIA GPU (if available) elif torch.backends.mps.is_available(): device = "mps" # Use Apple Silicon GPU (if available) else: device = "cpu" # Default to CPU if no GPU is available |
9-3. 텐서(또는 모델)을 GPU로 옮기기
텐서(또는 모델)에 대해 to(device)를 호출하여 특정 디바이스에 텐서(또는 모델)를 배치할 수 있습니다. 여기서 장치는 텐서(또는 모델)가 이동하기를 원하는 대상 장치입니다.
GPU를 사용할 수 없는 경우 CPU에서 실행됩니다.
to(device)를 사용해 텐서를 GPU에 배치하면 해당 텐서의 복사본이 반환되며, 동일한 텐서가 CPU와 GPU에 존재하게 됩니다. 텐서를 덮어쓰려면 텐서를 재할당합니다:
텐서를 생성하여 GPU에 배치해 보겠습니다
| # 텐서를 생성하면 CPU 메모리에 저장됩니다. tensor = torch.tensor([1, 2, 3]) # Tensor not on GPU print(tensor, tensor.device) # 텐서를 GPU로 옮깁니다. tensor_on_gpu = tensor.to(device) tensor_on_gpu |
GPU를 사용할 수 있는 경우 위의 코드는 다음과 같이 출력됩니다:
tensor([1, 2, 3]) cpu
tensor([1, 2, 3], device='cuda:0')
두 번째 텐서에는 device='cuda:0'이 있는데, 이는 사용 가능한 0번째 GPU에 저장되어 있음을 의미합니다(GPU는 0 인덱싱되며, 두 개의 GPU를 사용할 수 있다면 각각'cuda:0'과 `'cuda:1'이 됩니다).
9-4. 텐서를 GPU에서 CPU로 옮기기
넘파이는 GPU의 메모리상에서 동작하지 않기 때문에 CPU 메모리로 옮길 필요가 있습니다. GPU 메모리에 있는 텐서에서 numpy()를 사용하면 다음처럼 에러가 발생합니다.
| # If tensor is on GPU, can't transform it to NumPy (this will error) tensor_on_gpu.numpy() |
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-86-53175578f49e> in <cell line: 2>()
1 # If tensor is on GPU, can't transform it to NumPy (this will error)
----> 2 tensor_on_gpu.numpy()
TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
텐서를 다시 CPU로 가져와 NumPy에서 사용하려면 Tensor.cpu()를 사용하면 됩니다. 이렇게 하면 텐서를 CPU 메모리로 복사하여 CPU에서 사용할 수 있습니다.
| # Instead, copy the tensor back to cpu tensor_back_on_cpu = tensor_on_gpu.cpu().numpy() tensor_back_on_cpu |
array([1, 2, 3])
GPU에 있던 텐서를 CPU 메모리로 복사한 복사본을 반환하므로 원본 텐서는 여전히 GPU에 있습니다.
| tensor_on_gpu |
tensor([1, 2, 3], device='cuda:0')