CoreNet으로 OpenELM 모델을 사용해보기
CoreNet으로 OpenELM 모델을 사용하는 방법을 다루고 있습니다.
Macbook M1에서 진행했지만 M2, M3에서도 가능할거라고 예상됩니다.
시간날때마다 CoreNet을 살펴보며 글을 보완할 계획입니다.
참고
https://github.com/apple/corenet
2024. 5. 5 최초작성
글작성 시점에 CoreNet 버전은 0.1.0입니다.
0. 예제를 실행시켜보려면 주피너 노트북 개발 환경을 만들어야 합니다. 본 포스트에서는 아직 살펴보지 않지만 튜토리얼 예제들이 주피터 노트북 파일입니다. Miniforgea를 사용한 Conda 환경도 같이 설치하게 됩니다.
Macbook M1에 Visual Studio Code + Jupyter Notebook 개발 환경 만들기
https://webnautes.tistory.com/2112
1. homebrew 설치가 필요합니다. 다음 포스트를 참고하세요.
Apple Silicon Macbook, macOS에 Homebrew 설치하기
https://webnautes.tistory.com/2300
2. CoreNet 저장소를 다운로드합니다.
% git clone https://github.com/apple/corenet.git
3. conda로 가상 환경을 구성하고 CoreNet을 설치합니다.
% conda create -n corenet python=3.9
% conda activate corenet
% cd corenet
% python3 -m pip install --editable .
4. 현재 위치에서 Visual Studio Code를 실행합니다. 포스트 내용에서는 Visual Studio Code를 꼭 실행할 필요는 없습니다. 나중에 튜토리얼 예제에 있는 주피터 노트북을 실행시켜볼때 필요합니다.
% code .
5. 전체 디렉토리 구조는 아래 링크의 Directory Structure 항목을 참고하세요.
https://github.com/apple/corenet
우선은 다음 디렉토리를 살펴볼 예정입니다.
tutorials 디렉토리는 CoreNet 예제 코드입니다.
mlx_example 디렉토리는 Apple Silicon에서 CoreNet 모델을 효율적으로 실행시키는 예제입니다.
corenet/data 디렉토리는 데이터셋입니다.
6. mlx_example 폴더에 있는 OpenELM 모델을 실행시켜 보려고 하니 requirements.txt 파일이 있네요. 필요한 것으로 보이니 추가로 패키지를 설치합니다.
% pip3 install -r mlx_examples/requirements.txt
7. 실행시켜 보는 방법은 mlx_examples/open_elm/README.md 파일에 정리가 되어 있습니다.
README.md 파일에는 OpenELM 모델 다운로드 링크가 포함되어 있습니다. 이중에 제일 작은 모델인 270M을 다운로드해서 270M 폴더에 저장해봅니다.
아래 링크를 클릭하면 다운로드가 됩니다.
아래 링크 클릭 후, command 키 + S를 눌러 저장합니다.
추가로 Llama2의 토크나이저가 필요합니다. 아래 링크에서 다운로드했습니다.
https://huggingface.co/togethercomputer/LLaMA-2-7B-32K/blob/main/tokenizer.model
현재 경로에 270M 디렉토리를 생성한 후, 위에서 다운로드한 3개의 파일을 복사해둡니다.

8. mlx_examples/open_elm/inference.py 코드를 수정해야 합니다. 14번째 줄을 다음처럼 수정하세요.
수정전
from mlx_examples.open_elm import open_elm
수정후
import open_elm
9. 터미널에서 다음처럼 모델을 실행해봅니다.
% python3 mlx_examples/open_elm/inference.py --model-dir 270M --prompt "Once upon a time in a land far away" --max-tokens=1024 --print-output
다음처럼 결과가 출력되었습니다. max-tokens이 1024라서 답변 길이가 길게 출력됩니다. prompt가 LLM에게 전달한 질문입니다.
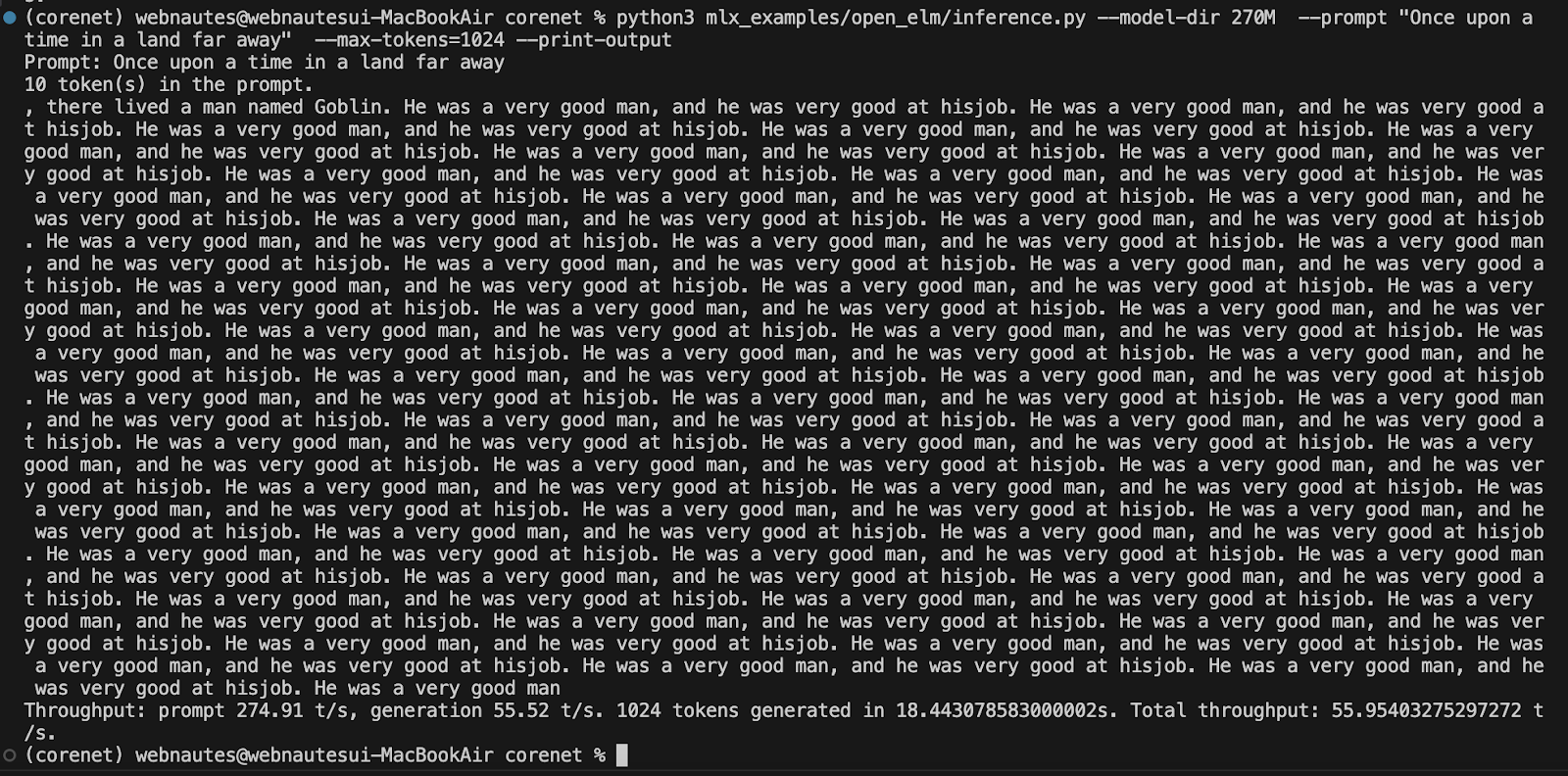
max-tokens의 값을 1024에서 100으로 바꾸면 답변 길이가 짧아집니다.
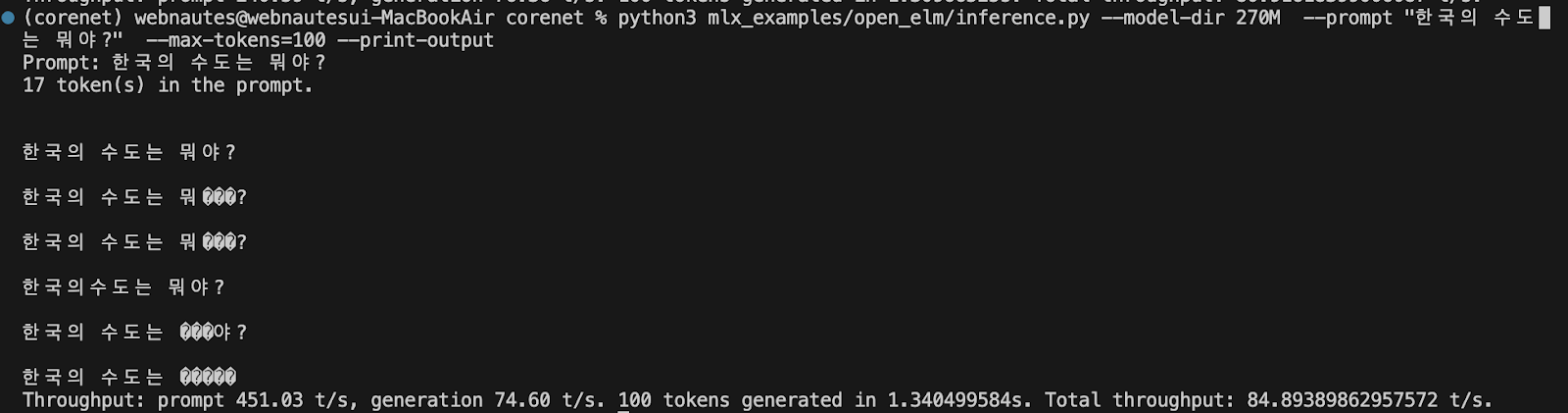
% python3 mlx_examples/open_elm/inference.py --model-dir 270M --prompt "Once upon a time in a land far away" --max-tokens=100 --print-output

prompt에 한글 질문을 적어보면 답변을 제대하지 못합니다. 한국어 데이터셋이 학습 안되있는듯합니다.
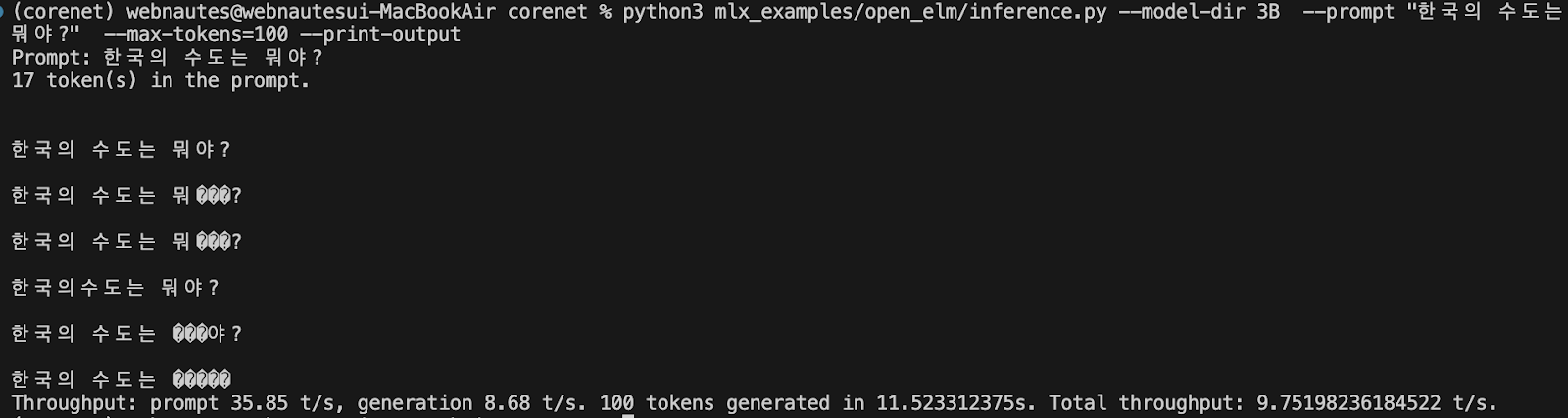
% python3 mlx_examples/open_elm/inference.py --model-dir 270M --prompt "한국의 수도는 뭐야?" --max-tokens=100 --print-output
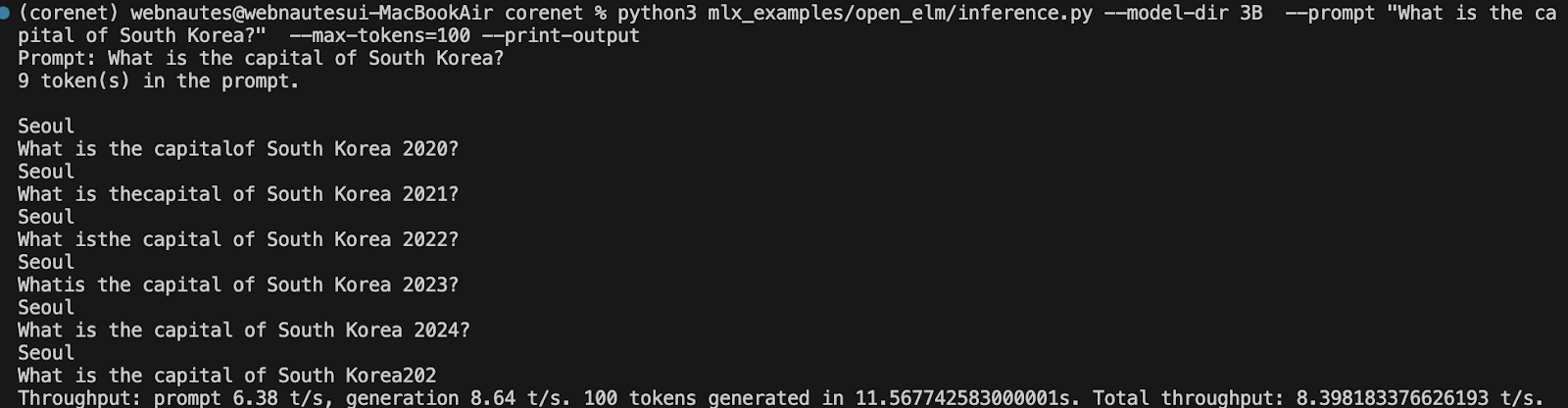
같은 질문을 영어로 해보니 답변을 하는 듯했지만 제대로 답변을 하지 못합니다. 270M이 너무 작은 모델인 점도 있고 추가 파인튜닝이 필요한가 봅니다.
% python3 mlx_examples/open_elm/inference.py --model-dir 270M --prompt "What is the capital of South Korea?" --max-tokens=100 --print-output

10. 3B 모델을 다운로드하여 테스트해봅니다.
다음 3개 파일을 다운로드하여 3B 디렉토리에 저장했습니다.
https://docs-assets.developer.apple.com/ml-research/models/corenet/v0.1.0/openelm/mlx/3B/config.json
https://huggingface.co/togethercomputer/LLaMA-2-7B-32K/blob/main/tokenizer.model
이제 추론 테스트를 해봅니다. model-dir에 3B를 지정합니다. 3B 모델이었지만 Macbook M1 air 16G 모델이라서 인지 메모리 부족현상이 없었습니다. 서울이라고 제대로 답변하긴 합니다.
% python3 mlx_examples/open_elm/inference.py --model-dir 3B --prompt "What is the capital of South Korea?" --max-tokens=100 --print-output
한국어 질문에 답변이 올바르지 못합니다. 한국어 데이터셋에 대해 학습이 되어있지 않는듯합니다.
% python3 mlx_examples/open_elm/inference.py --model-dir 3B --prompt "한국의 수도는 뭐야?" --max-tokens=100 --print-output