
Keras Tuner를 사용하여 Keras 모델의 레이어, 학습률, 배치 크기 등에 대한 최적의 하이퍼파라미터를 찾는 예제 코드입니다.
2022. 02. 20 최초작성
아래 링크들을 참고하여 Red Wine Quality 데이터셋(https://www.kaggle.com/uciml/red-wine-quality-cortez-et-al-2009)을 위해 작성한 Keras classification 코드를 최적하는 코드를 작성해보았습니다.
Model을 구성하는 Dense 레이어의 units, Dropou의 rate, 학습률, 배치 크기 등의 하이퍼파라미터에 대한 최적값을 찾게됩니다.
https://www.tensorflow.org/tutorials/keras/keras_tuner?hl=ko
https://www.sicara.ai/blog/hyperparameter-tuning-keras-tuner
https://github.com/keras-team/keras-tuner/issues/122
실행 결과 로그와 그래프입니다. 원하는 수준의 결과를 얻을 수는 없었지만 Keras Tuner를 사용 방법을 간단하게나마 알게된 소득이 있었습니다.
자주 사용해보며 Keras Tuner를 좀 더 익혀봐야 겠습니다.
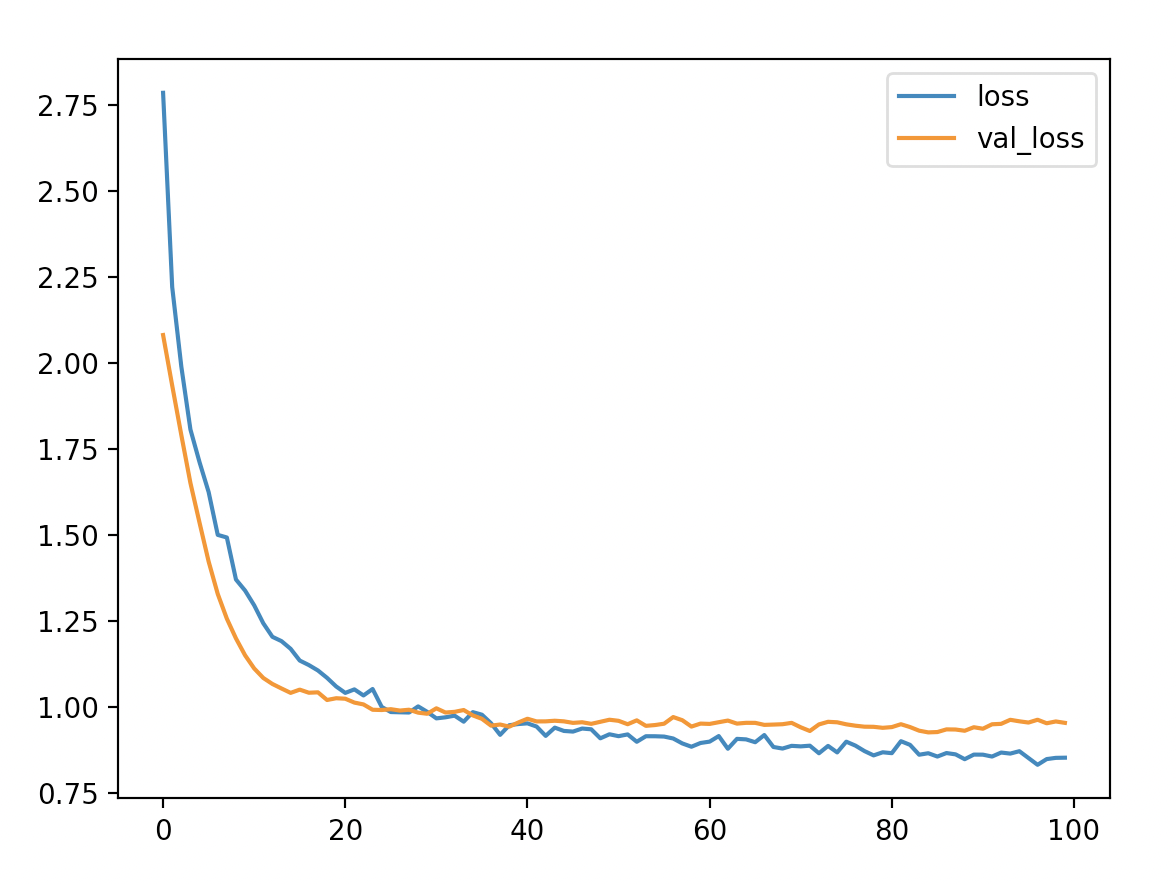

로그는 Keras Tuner 마지막 단계에서 실행된 최종 학습시 결과입니다.
최적 파라미터 값들
units_1 : 29
units_2 : 107
dropout_1 : 0.30000000000000004
dropout_2 : 0.25
learning_rate : 0.0005550246291195939
batch_size : 32
학습 로그
Epoch 1/100
2022-02-19 22:43:26.528003: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
32/32 [==============================] - ETA: 0s - loss: 2.7863 - accuracy: 0.14102022-02-19 22:43:31.225551: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
32/32 [==============================] - 6s 125ms/step - loss: 2.7863 - accuracy: 0.1410 - val_loss: 2.0815 - val_accuracy: 0.4554
Epoch 2/100
32/32 [==============================] - 2s 54ms/step - loss: 2.2213 - accuracy: 0.2810 - val_loss: 1.9345 - val_accuracy: 0.4554
Epoch 3/100
32/32 [==============================] - 1s 38ms/step - loss: 1.9900 - accuracy: 0.3793 - val_loss: 1.7907 - val_accuracy: 0.4821
Epoch 4/100
32/32 [==============================] - 1s 40ms/step - loss: 1.8068 - accuracy: 0.4767 - val_loss: 1.6511 - val_accuracy: 0.4821
Epoch 5/100
32/32 [==============================] - 1s 41ms/step - loss: 1.7116 - accuracy: 0.4777 - val_loss: 1.5355 - val_accuracy: 0.5268
Epoch 6/100
32/32 [==============================] - 1s 37ms/step - loss: 1.6246 - accuracy: 0.4846 - val_loss: 1.4224 - val_accuracy: 0.5625
Epoch 7/100
32/32 [==============================] - 1s 37ms/step - loss: 1.5000 - accuracy: 0.5253 - val_loss: 1.3281 - val_accuracy: 0.5625
Epoch 8/100
32/32 [==============================] - 1s 36ms/step - loss: 1.4924 - accuracy: 0.5362 - val_loss: 1.2561 - val_accuracy: 0.5804
Epoch 9/100
32/32 [==============================] - 1s 36ms/step - loss: 1.3701 - accuracy: 0.5641 - val_loss: 1.1988 - val_accuracy: 0.5714
Epoch 10/100
32/32 [==============================] - 1s 37ms/step - loss: 1.3380 - accuracy: 0.5561 - val_loss: 1.1497 - val_accuracy: 0.5714
Epoch 11/100
32/32 [==============================] - 1s 36ms/step - loss: 1.2951 - accuracy: 0.5541 - val_loss: 1.1113 - val_accuracy: 0.5714
Epoch 12/100
32/32 [==============================] - 1s 36ms/step - loss: 1.2427 - accuracy: 0.5412 - val_loss: 1.0836 - val_accuracy: 0.5804
Epoch 13/100
32/32 [==============================] - 1s 38ms/step - loss: 1.2034 - accuracy: 0.5581 - val_loss: 1.0662 - val_accuracy: 0.5625
Epoch 14/100
32/32 [==============================] - 1s 37ms/step - loss: 1.1908 - accuracy: 0.5740 - val_loss: 1.0530 - val_accuracy: 0.5714
Epoch 15/100
32/32 [==============================] - 1s 36ms/step - loss: 1.1685 - accuracy: 0.5561 - val_loss: 1.0403 - val_accuracy: 0.5804
Epoch 16/100
32/32 [==============================] - 1s 36ms/step - loss: 1.1344 - accuracy: 0.5641 - val_loss: 1.0497 - val_accuracy: 0.5714
Epoch 17/100
32/32 [==============================] - 1s 37ms/step - loss: 1.1212 - accuracy: 0.5899 - val_loss: 1.0407 - val_accuracy: 0.5625
Epoch 18/100
32/32 [==============================] - 1s 37ms/step - loss: 1.1054 - accuracy: 0.5730 - val_loss: 1.0418 - val_accuracy: 0.5714
Epoch 19/100
32/32 [==============================] - 1s 36ms/step - loss: 1.0839 - accuracy: 0.5809 - val_loss: 1.0195 - val_accuracy: 0.5804
Epoch 20/100
32/32 [==============================] - 1s 36ms/step - loss: 1.0589 - accuracy: 0.5889 - val_loss: 1.0247 - val_accuracy: 0.5536
Epoch 21/100
32/32 [==============================] - 1s 36ms/step - loss: 1.0402 - accuracy: 0.5809 - val_loss: 1.0233 - val_accuracy: 0.5625
Epoch 22/100
32/32 [==============================] - 1s 35ms/step - loss: 1.0504 - accuracy: 0.5740 - val_loss: 1.0120 - val_accuracy: 0.5625
Epoch 23/100
32/32 [==============================] - 1s 36ms/step - loss: 1.0328 - accuracy: 0.5631 - val_loss: 1.0067 - val_accuracy: 0.5625
Epoch 24/100
32/32 [==============================] - 1s 35ms/step - loss: 1.0515 - accuracy: 0.5760 - val_loss: 0.9912 - val_accuracy: 0.5804
Epoch 25/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9994 - accuracy: 0.5750 - val_loss: 0.9904 - val_accuracy: 0.5893
Epoch 26/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9845 - accuracy: 0.6008 - val_loss: 0.9928 - val_accuracy: 0.5893
Epoch 27/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9838 - accuracy: 0.5780 - val_loss: 0.9888 - val_accuracy: 0.5982
Epoch 28/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9831 - accuracy: 0.5859 - val_loss: 0.9912 - val_accuracy: 0.6071
Epoch 29/100
32/32 [==============================] - 1s 36ms/step - loss: 1.0010 - accuracy: 0.5789 - val_loss: 0.9827 - val_accuracy: 0.5982
Epoch 30/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9849 - accuracy: 0.5899 - val_loss: 0.9795 - val_accuracy: 0.5804
Epoch 31/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9661 - accuracy: 0.5938 - val_loss: 0.9953 - val_accuracy: 0.5714
Epoch 32/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9692 - accuracy: 0.6077 - val_loss: 0.9831 - val_accuracy: 0.5804
Epoch 33/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9740 - accuracy: 0.5789 - val_loss: 0.9850 - val_accuracy: 0.5982
Epoch 34/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9564 - accuracy: 0.5849 - val_loss: 0.9904 - val_accuracy: 0.5804
Epoch 35/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9842 - accuracy: 0.5819 - val_loss: 0.9747 - val_accuracy: 0.5804
Epoch 36/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9768 - accuracy: 0.5809 - val_loss: 0.9648 - val_accuracy: 0.6071
Epoch 37/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9520 - accuracy: 0.5938 - val_loss: 0.9449 - val_accuracy: 0.5982
Epoch 38/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9181 - accuracy: 0.6018 - val_loss: 0.9482 - val_accuracy: 0.5893
Epoch 39/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9461 - accuracy: 0.5998 - val_loss: 0.9420 - val_accuracy: 0.6071
Epoch 40/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9496 - accuracy: 0.5929 - val_loss: 0.9542 - val_accuracy: 0.6161
Epoch 41/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9516 - accuracy: 0.5948 - val_loss: 0.9650 - val_accuracy: 0.6071
Epoch 42/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9423 - accuracy: 0.6018 - val_loss: 0.9572 - val_accuracy: 0.5982
Epoch 43/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9152 - accuracy: 0.6107 - val_loss: 0.9574 - val_accuracy: 0.5893
Epoch 44/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9391 - accuracy: 0.5899 - val_loss: 0.9592 - val_accuracy: 0.5982
Epoch 45/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9295 - accuracy: 0.6058 - val_loss: 0.9574 - val_accuracy: 0.5982
Epoch 46/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9276 - accuracy: 0.6226 - val_loss: 0.9530 - val_accuracy: 0.6071
Epoch 47/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9365 - accuracy: 0.5998 - val_loss: 0.9548 - val_accuracy: 0.6071
Epoch 48/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9343 - accuracy: 0.6097 - val_loss: 0.9502 - val_accuracy: 0.6161
Epoch 49/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9080 - accuracy: 0.6286 - val_loss: 0.9561 - val_accuracy: 0.5982
Epoch 50/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9198 - accuracy: 0.6087 - val_loss: 0.9621 - val_accuracy: 0.5982
Epoch 51/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9143 - accuracy: 0.6028 - val_loss: 0.9590 - val_accuracy: 0.6071
Epoch 52/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9194 - accuracy: 0.6008 - val_loss: 0.9491 - val_accuracy: 0.6161
Epoch 53/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8980 - accuracy: 0.6207 - val_loss: 0.9603 - val_accuracy: 0.5982
Epoch 54/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9141 - accuracy: 0.6157 - val_loss: 0.9443 - val_accuracy: 0.5893
Epoch 55/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9140 - accuracy: 0.5869 - val_loss: 0.9466 - val_accuracy: 0.6071
Epoch 56/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9131 - accuracy: 0.6028 - val_loss: 0.9506 - val_accuracy: 0.5982
Epoch 57/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9075 - accuracy: 0.6197 - val_loss: 0.9699 - val_accuracy: 0.5893
Epoch 58/100
32/32 [==============================] - 1s 36ms/step - loss: 0.8932 - accuracy: 0.6266 - val_loss: 0.9607 - val_accuracy: 0.6071
Epoch 59/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8836 - accuracy: 0.6177 - val_loss: 0.9422 - val_accuracy: 0.6071
Epoch 60/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8945 - accuracy: 0.5948 - val_loss: 0.9509 - val_accuracy: 0.6161
Epoch 61/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8984 - accuracy: 0.6137 - val_loss: 0.9500 - val_accuracy: 0.5982
Epoch 62/100
32/32 [==============================] - 1s 36ms/step - loss: 0.9146 - accuracy: 0.5909 - val_loss: 0.9549 - val_accuracy: 0.5982
Epoch 63/100
32/32 [==============================] - 1s 36ms/step - loss: 0.8777 - accuracy: 0.6316 - val_loss: 0.9597 - val_accuracy: 0.6071
Epoch 64/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9064 - accuracy: 0.6147 - val_loss: 0.9508 - val_accuracy: 0.6161
Epoch 65/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9050 - accuracy: 0.6187 - val_loss: 0.9531 - val_accuracy: 0.6161
Epoch 66/100
32/32 [==============================] - 1s 36ms/step - loss: 0.8967 - accuracy: 0.6216 - val_loss: 0.9530 - val_accuracy: 0.6161
Epoch 67/100
32/32 [==============================] - 1s 35ms/step - loss: 0.9176 - accuracy: 0.6107 - val_loss: 0.9472 - val_accuracy: 0.5893
Epoch 68/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8828 - accuracy: 0.6246 - val_loss: 0.9480 - val_accuracy: 0.5893
Epoch 69/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8782 - accuracy: 0.6167 - val_loss: 0.9490 - val_accuracy: 0.5893
Epoch 70/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8861 - accuracy: 0.6087 - val_loss: 0.9530 - val_accuracy: 0.5804
Epoch 71/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8846 - accuracy: 0.6068 - val_loss: 0.9401 - val_accuracy: 0.6071
Epoch 72/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8866 - accuracy: 0.6266 - val_loss: 0.9293 - val_accuracy: 0.6071
Epoch 73/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8646 - accuracy: 0.6286 - val_loss: 0.9485 - val_accuracy: 0.6161
Epoch 74/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8859 - accuracy: 0.6137 - val_loss: 0.9561 - val_accuracy: 0.6161
Epoch 75/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8670 - accuracy: 0.6197 - val_loss: 0.9547 - val_accuracy: 0.5982
Epoch 76/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8983 - accuracy: 0.6266 - val_loss: 0.9488 - val_accuracy: 0.5982
Epoch 77/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8869 - accuracy: 0.6197 - val_loss: 0.9448 - val_accuracy: 0.5982
Epoch 78/100
32/32 [==============================] - 1s 36ms/step - loss: 0.8709 - accuracy: 0.6296 - val_loss: 0.9419 - val_accuracy: 0.6071
Epoch 79/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8584 - accuracy: 0.6475 - val_loss: 0.9415 - val_accuracy: 0.6071
Epoch 80/100
32/32 [==============================] - 1s 36ms/step - loss: 0.8674 - accuracy: 0.6445 - val_loss: 0.9386 - val_accuracy: 0.6071
Epoch 81/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8648 - accuracy: 0.6147 - val_loss: 0.9407 - val_accuracy: 0.6161
Epoch 82/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8997 - accuracy: 0.6197 - val_loss: 0.9491 - val_accuracy: 0.6250
Epoch 83/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8890 - accuracy: 0.6137 - val_loss: 0.9408 - val_accuracy: 0.6071
Epoch 84/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8603 - accuracy: 0.6236 - val_loss: 0.9302 - val_accuracy: 0.6339
Epoch 85/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8646 - accuracy: 0.6266 - val_loss: 0.9253 - val_accuracy: 0.6339
Epoch 86/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8550 - accuracy: 0.6395 - val_loss: 0.9263 - val_accuracy: 0.5982
Epoch 87/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8652 - accuracy: 0.6346 - val_loss: 0.9340 - val_accuracy: 0.5982
Epoch 88/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8613 - accuracy: 0.6356 - val_loss: 0.9337 - val_accuracy: 0.6250
Epoch 89/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8473 - accuracy: 0.6415 - val_loss: 0.9300 - val_accuracy: 0.5982
Epoch 90/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8607 - accuracy: 0.6395 - val_loss: 0.9403 - val_accuracy: 0.6071
Epoch 91/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8605 - accuracy: 0.6365 - val_loss: 0.9359 - val_accuracy: 0.6339
Epoch 92/100
32/32 [==============================] - 1s 36ms/step - loss: 0.8550 - accuracy: 0.6236 - val_loss: 0.9489 - val_accuracy: 0.6429
Epoch 93/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8666 - accuracy: 0.6356 - val_loss: 0.9502 - val_accuracy: 0.6071
Epoch 94/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8636 - accuracy: 0.6246 - val_loss: 0.9619 - val_accuracy: 0.6161
Epoch 95/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8706 - accuracy: 0.6147 - val_loss: 0.9575 - val_accuracy: 0.6161
Epoch 96/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8507 - accuracy: 0.6276 - val_loss: 0.9539 - val_accuracy: 0.5982
Epoch 97/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8310 - accuracy: 0.6356 - val_loss: 0.9621 - val_accuracy: 0.6161
Epoch 98/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8476 - accuracy: 0.6465 - val_loss: 0.9518 - val_accuracy: 0.6339
Epoch 99/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8512 - accuracy: 0.6375 - val_loss: 0.9571 - val_accuracy: 0.6250
Epoch 100/100
32/32 [==============================] - 1s 35ms/step - loss: 0.8517 - accuracy: 0.6316 - val_loss: 0.9530 - val_accuracy: 0.6429
2022-02-19 22:46:01.959095: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
테스트 데이터셋에 대한 추론 정확도
0.58125
전체 코드입니다.
| # 참고 # # https://www.sicara.ai/blog/hyperparameter-tuning-keras-tuner # https://www.tensorflow.org/tutorials/keras/keras_tuner?hl=ko # https://github.com/keras-team/keras-tuner/issues/122 from tensorflow import keras from tensorflow.keras import layers, optimizers from tensorflow.keras.utils import to_categorical from sklearn.metrics import accuracy_score import numpy as np import pandas as pd import matplotlib.pyplot as plt import os import kerastuner as kt # 하이퍼파리미터를 찾기 위해 모델에서 조정할 레이어의 값 범위를 지정해주고 추가로 학습률과 배치 크기의 값 범위를 추가로 지정해줍니다. class MyHyperModel(kt.HyperModel): def build(self, hp): hp_units1 = hp.Int('units_1', min_value = 16, max_value = 180) hp_units2 = hp.Int('units_2', min_value = 16, max_value = 180) hp_units4 = hp.Float('dropout_1', min_value=0.0, max_value=0.5, step=0.05) hp_units5 = hp.Float('dropout_2', min_value=0.0, max_value=0.5, step=0.05) model = keras.Sequential() model.add(layers.Dense(hp_units1, activation='relu', input_shape=[X_train.shape[1]])) model.add(layers.BatchNormalization()) model.add(layers.Dropout(hp_units4)) model.add(layers.Dense(hp_units2, activation='relu')) model.add(layers.BatchNormalization()) model.add(layers.Dropout(hp_units5)) model.add(layers.Dense(9, activation='softmax')) hp_learning_rate = hp.Float('learning_rate', min_value=1e-6, max_value=1e-3, sampling='LOG') model.compile(optimizer=optimizers.Adam(learning_rate=hp_learning_rate), loss='categorical_crossentropy', metrics=['accuracy']) return model def fit(self, hp, model, *args, **kwargs): return model.fit( *args, batch_size=hp.Int('batch_size', min_value = 16, max_value = 256, step = 16), **kwargs, ) # Red Wine Quality 데이터셋을 로드합니다. BASE_DIR = os.path.dirname(os.path.abspath(__file__)) red_wine = pd.read_csv(BASE_DIR + '/' + 'winequality-red.csv') red_wine = red_wine.dropna() # 7:3 비율로 training dataset과 Test dataset으로 분리합니다. df_train = red_wine.sample(frac=0.7, random_state=1234) df_test = red_wine.drop(df_train.index) # 특징과 라벨을 분리합니다. X_train = df_train.drop('quality', axis=1).values X_test = df_test.drop('quality', axis=1).values y_train = df_train['quality'].values y_test = df_test['quality'].values # min-max normalization를 적용하여 특징 값의 범위를 0 ~ 1 사이로 변경합니다. # 신경망은 입력이 공통 크기일 때 가장 잘 수행되는 경향이 있기 때문입니다. # 이때 특징별로 min,max를 구하여 min-max normalization를 적용합니다. X_train_max = X_train.max(axis=0) X_train_min = X_train.min(axis=0) X_train = (X_train - X_train_min) / (X_train_max - X_train_min) X_test = (X_test - X_train_min) / (X_train_max - X_train_min) # One-hot 인코딩을 합니다. y_train, y_test = to_categorical(y_train), to_categorical(y_test) # 최적 하이퍼파라미터를 찾는 작업을 진행합니다. tuner = kt.Hyperband(MyHyperModel(), objective = 'val_accuracy', max_epochs = 100, executions_per_trial = 3, overwrite = True, factor = 3) tuner.search(X_train, y_train, epochs = 100, validation_split = 0.1) # 최적 하이퍼파라미터를 가져옵니다. best_hps = tuner.get_best_hyperparameters()[0] # 최적 하이퍼파라미터를 출력합니다. print(f""" units_1 : {best_hps.get('units_1')} units_2 : {best_hps.get('units_2')} dropout_1 : {best_hps.get('dropout_1')} dropout_2 : {best_hps.get('dropout_2')} learning_rate : {best_hps.get('learning_rate')} batch_size : {best_hps.get('batch_size')} """) # 배치 크기는 따로 저장했다가 fit 메소드에서 적용합니다. batch_size = best_hps.get('batch_size') # 최적값으로 모델을 생성합니다. model = tuner.hypermodel.build(best_hps) # 학습을 진행합니다. # validation_split 아규먼트로 Training 데이터셋의 10%를 Validation 데이터셋으로 사용하도록합니다. # 예를 들어 배치 크기가 256이라는 것은 전체 데이터셋을 샘플 256개씩으로 나누어서 학습에 사용한다는 의미입니다. # 예를 들어 에포크(epochs)가 10이라는 것은 전체 train 데이터셋을 10번 본다는 의미입니다. history = model.fit( X_train, y_train, validation_split = 0.1, batch_size=batch_size, epochs=100, ) # 학습중 손실 변화를 그래프로 그립니다. history_df = pd.DataFrame(history.history) history_df['loss'].plot() history_df['val_loss'].plot() plt.legend() plt.show() history_df = pd.DataFrame(history.history) history_df['accuracy'].plot() history_df['val_accuracy'].plot() plt.legend() plt.show() # Test 데이터셋으로 모델 성능 평가를 합니다. y_pred = model.predict(X_test) y_pred = np.argmax(y_pred, axis=1) y_test = np.argmax(y_test, axis=1) print(accuracy_score(y_test, y_pred)) |
'Deep Learning > Keras' 카테고리의 다른 글
| tf.keras.applications.EfficientNet 모델 사용시 주의할 점 (0) | 2023.10.10 |
|---|---|
| Keras와 OpenCV를 사용하여 손글씨 숫자 인식하기 (0) | 2023.10.09 |
| TensorFlow 예제 - Keras + OpenCV를 사용하여 실제 손글씨 숫자 인식 (0) | 2023.10.09 |
| Keras 모델을 TensorFlow Lite로 변환하기 (h5 -> pb -> tflite) (0) | 2022.10.23 |
| Keras - Data Augmentation 이미지로 확인해보기 (0) | 2021.06.29 |
문제 발생시 지나치지 마시고 댓글 남겨주시면 가능한 빨리 답장드립니다.
도움이 되셨다면 토스아이디로 후원해주세요.
https://toss.me/momo2024
제가 쓴 책도 한번 검토해보세요 ^^

